
RubyファイルにGoコードを書いてRuby Nextで動かす(翻訳)
Rubyは素晴らしい言語です。私たちはRubyの読みやすさ、柔軟性の高さ、そして開発者中心主義を愛しています。しかしここ火星ではGo言語も愛されています。Goにも独特のシンプルさとマジックの感覚があるからです。単刀直入に申し上げると、Goはいくつかの点でRubyを上回っています(高速、静的型付け、すぐに利用できるクールなコンカレンシー)。とは言うものの、一部の勇敢な読者は、「そんなにいいなら全部Goで書けばいいのに?」という一見もっともな疑問が心の中に湧き上がってくるかもしれません。
要するに、Rubyだけでは作業に十分対応できない場合もあるということです。私たちもアプリケーションの一部をもう少し高速なものに書き直さなければならなくなったことがあります。たとえばimgproxyは、eBay向けのRubyプロジェクトを手掛けているときにGoで立ち上げたものです。

Goへの大きな切り替えはAnyCableでも起きました。経緯について詳しくは以下の記事をどうぞ。
参考: AnyCable: Action Cable on steroids — Martian Chronicles, Evil Martians’ team blog
全部Goで書かない理由は何でしょう?真面目に回答するならば…
でも今さら真面目な答えなんて欲しくありませんよね?今さら、どんなときにGoを使ってどんなときにRubyを使うかについての解説記事をわざわざ書く意味などあるでしょうか?そういう考えはゴミ箱にポイすることにして、代わりに「空想」という心のレンズを通して方法を探ってみることにしましょう。仮に、何らかの(黙示録的な)理由で現実世界が制御不能になってしまい、「すべてを」Goで書く必要に迫られる世界を空想することにします。
現状を調査する
たとえば、既にすべてをRubyで書いたプロジェクトがあるにもかかわらず、この空想世界ではRubyを泣く泣く捨てなければならなくなるとします。RubyをGoにする1には以下のようないくつかのオプションが考えられます。
- 全部書き直す: プロジェクト全体をそのままGoで書き直すことは可能といえば可能ですが、Joel On Softwareが教えるように、これはおそらく筋の悪い方法です。
他のオプションも検討してみましょう。
- マイクロサービスを新たに書く: 新しいマイクロサービスを使ってGoで新たに小さなプロジェクトを立ち上げることは可能といえば可能ですが、Rubyのレガシーコードのことを忘れてはいませんか?
-
第3のソリューションとは…Rubyの中にGoを書くことです!
目標は、Goで書かれた新しいクラスをRubyコードベースの中で正しく動かすことです。これならば、移行時に作業の80%は終わっていることになります。
このアイデアを試してみるために、A Tour of Goにある”Hello World”サンプルコードの拡張子をmain.goからmain.go.rbに変更してみましょう。
# main.go.rb
package main
import "fmt"
func main() {
fmt.Println("Hello, 世界")
}
まずは普通にこのコードを実行してみます。
$ ruby main.go.rb
main.go.rb:1:in `<main>': undefined local variable or method `main' for main:Object (NameError)
残念ながら、やはり動きません。これは一部のコードを手書きする必要があるということです。Rubyではめったにありませんが、こういうことはたまに起きます。
GoパッケージをRubyで実装する
最初にpackageメソッドを実装します。以下は、Rubyがpackage mainをどう認識するかを示しています。
package main #=> package(main())
package foo #=> package(foo())
Rubyはmainメソッドを呼び出して、その結果をpackageメソッドに渡しています。しかしmainもfooも未定義なので、これを動かす方法はひとつしかありません。
method_missingを追加して、常にメソッド名を返すようにしてみましょう。
class << self
def method_missing(name, *_args)
name
end
end
この手法は現実のproductionコードで完璧に使えるでしょうか?まさか
今度はpackageメソッドに何をさせるかを見ていきましょう。Goのパッケージは変数や関数などの可視範囲を制限します。つまりパッケージは本質的に名前空間であり、名前空間といえばRubyのモジュールを連想しますね。
package foo
# =>
module GoRuby
module Foo
# 定義済みの関数
end
end
そこで、パッケージ名を取り出し、その名前でモジュールを宣言しなければなりません。グローバルな名前空間を汚さないよう、これをGoRubyモジュールの内部で行ってみましょう。
class << self
def package(pkg)
mod_name = pkg.to_s.capitalize
unless GoRuby.const_defined?(mod_name)
GoRuby.module_eval("#{mod_name} = Module.new { extend self }")
end
@__go_package__ = GoRuby.const_get(mod_name)
end
end
mod_nameというモジュールがまだ存在しない場合は、module_evalで新たにモジュールを定義します。最後に結果を@__go_package変数に保存します(後で必要になります)。packageはこれでおしまいなので、次はimportメソッドです。
Goのimportを動かす
Goでは、パッケージをインポートし、たとえば fmt.Println("Hello, 世界")のようにそのメソッドを名前で呼び出すことでアクセスします。実装が必要なものを以下に示します。
import "fmt"
# =>
def fmt
GoRuby::Fmt
end
以下のようにすればいけそうです。
class << self
def import(pkg)
mod_name = pkg.split('_').collect(&:capitalize).join # String#camelize from ActiveSupport
raise "unknown package #{pkg}" unless GoRuby.const_defined?(mod_name)
define_method(pkg) { GoRuby.const_get(mod_name) }
end
end
mod_nameが未定義の場合は例外を出力し、そうでない場合は define_methodでメソッドを定義します。
これでimportも通るようになりました。この調子で次の関数定義に挑戦してみましょう。
関数定義を扱う
さてここで問題です。チッチッチッ…2。さてブロックはどこへ渡されるでしょうか?
func main() {
# 何かする
}
# => ブロックはどこへ渡されるか?
# 回答1: 以下のブロックはfooへ渡される
func(main()) {
# 何かする
}
# 回答2: 以下のブロックはmainへ渡される
func(main() {
# 何かする
})
これをRuboCopに見られたら速攻で警笛を鳴らされるところです 。丸かっこ
。丸かっこ()がないと、Rubyはブロックを「存在しないmainメソッド」に渡します。ここで method_missingの出番です。
class << self
def method_missing(name, *_args, &block)
if block
[name, block.to_proc]
else
name
end
end
end
ブロックを受け取ったら、それを配列の第2要素として返します。
以下はfuncメソッドの実装方法です。
class << self
def func(attrs)
current_package = @__go_package__
name, block = attrs
if current_package.respond_to? name
raise "#{name} already defined for package #{current_package}"
end
current_package.module_eval { define_method(name, block) }
end
end
今度はマジックを使っていません。ここでは現在アクティブなモジュール(@__go_package__)内でmethod_missingから名前とブロックを定義しています。
残るはGoの標準ライブラリだけです。
ここでは文字列をstdoutに出力するメソッドが1つあれば十分なので、ここまでにしておきます。以下をご覧ください。
module GoRuby
module Fmt
class << self
def Println(*attrs)
str = "#{attrs.join(' ')}\n"
$stdout << str
[str.bytesize, nil]
end
end
end
end
“Go Ruby, Go!”
これで必要そうなことはひととおりやれた感じです。この新しいライブラリをrequireしてmain.go.rbを実行してみましょう。
$ ruby -r './go_ruby.rb' main.go.rb
今度はエラーにならない代わりに、Hello, 世界も出力されません。Goではmainパッケージのmain()関数がGoの実行可能プログラムのエントリポイントになりますが、まだこれをライブラリに実装していません。ありがたいことにRubyにはat_exitコールバックメソッドがあるので、これを使うことにしましょう。
at_exit do
GoRuby::Main.main
end
もう一度コードを実行してみましょう。すぐに試したい方向けにgistを用意してあります。
$ ruby -r './go_ruby.rb' main.go.rb
Hello, 世界
Goの開発者はビルド時間にこだわっていますが、こちらはビルド時間ゼロです 。Goよりいいですね。
。Goよりいいですね。
今度はもう少し手を加えてみましょう。
さらにGoらしく
Goの:=演算子はどうでしょう?きっと実装はちょろいですよね?No method ':=' is foundエラーが発生することを期待しています。これを解決するためにRubyのObjectにこのメソッドを実装すると、以下のようになります。
$ ruby -e 'a := "Hello, 世界"'
-e:1: syntax error, unexpected '=', expecting literal content or terminator or tSTRING_DBEG or tSTRING_DVAR
a := "Hello, 世界"
予想は半分当たりでした。エラーになったまではよかったのですが、期待したものと少し違っています。このエラーは、以下のようにパーサーで発生したものです。
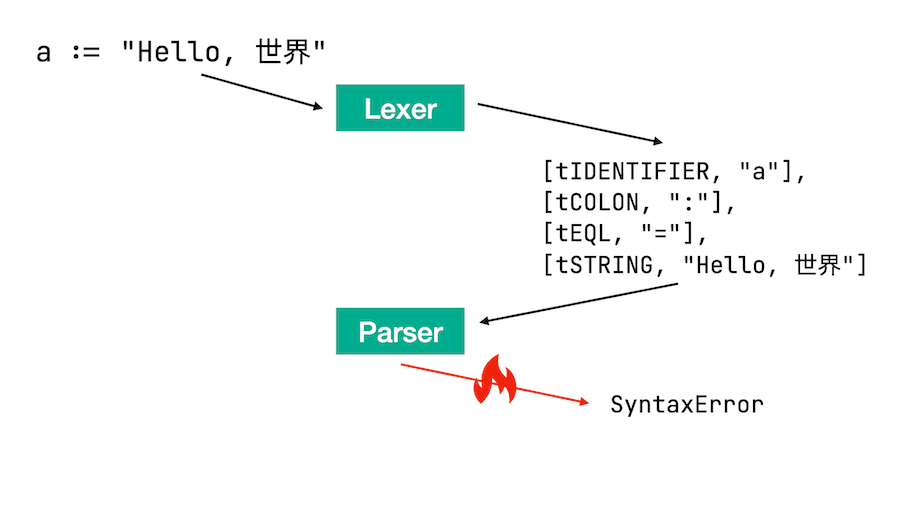
コードは最初lexer(字句解析器)に渡され、テキストをトークンに分割します。次にトークンの配列がパーサー(構文解析器)に渡され、:の直後に=を置くのは無効な演算子であるためにエラーが発生します。これを修正するにはどうすればよいでしょう?現実的な選択肢を探ってみましょう。
- Rubyチームに
:=を追加するよう頼み込む: 数年かけて日本語をマスターし、コアチームの信頼を獲得し、ミーティングに参加する方法を調べて、やっと:=を追加することになりそうです。 - Rubyをforkする: Rubyをforkして自力でメンテすることは一応可能です。ほとんどの人はDockerを使っているので、Rubyを差し替えてもビジネスには影響しないでしょう。
- 諸手を挙げてエイヤでトランスパイルする: Rubyの中でGoを書いてトランスパイルする手があります。JavaScriptやTypeScriptのBabelのようなものがRubyにもあればいいのですが、何か代わりになるものはないかな…
![🤔]()

ここではDSLが通用しない
ところで、実はコードをトランスパイルするツールなら既にあります。ruby-nextはEvil MartiansのVladimir Dementyevが一人で書き上げました。これを使ってみてはどうでしょう?

Ruby Nextによるコードのトランスパイルでは、コード読み込みをハイジャックし、独自に更新したlexerとパーサーで解析します。次に、得られたASTノードをRuby Nextのリライター(rewriter)で改変します。Ruby Nextのリライターは、注目する必要のある箇所をマーキングしてから改変を行います。最後にRuby Nextはunparserライブラリでコードを書き換え、ここでマーキング済みノードも書き換えます。
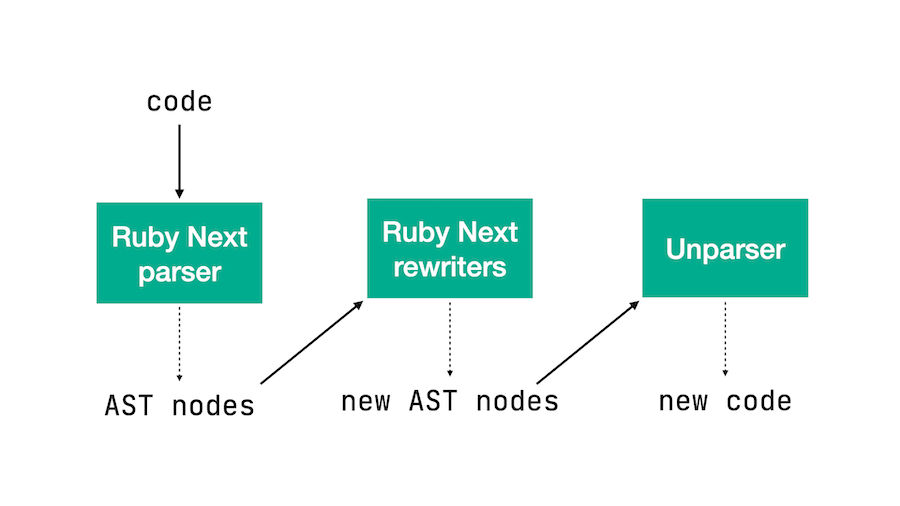
前置きはこのぐらいにして、Rubyで:=を使えるようにする実行可能な計画を実際に立案してみましょう。
- 最初にRuby Nextのlexerに手を加える
- 同様にRuby Nextのパーサーにも手を加える
- 次にRuby Nextのリライターを書く
- 最後にコード内で実際に
:=を書けるようにする
腕まくり開始: lexerに手を加える
最初はlexerです。ここではlexerで:=を単一のトークンとして扱えるようにしたいと思います。これは、パーサーがシンプルな=のときと同じASTノードを返せるようにするためです。
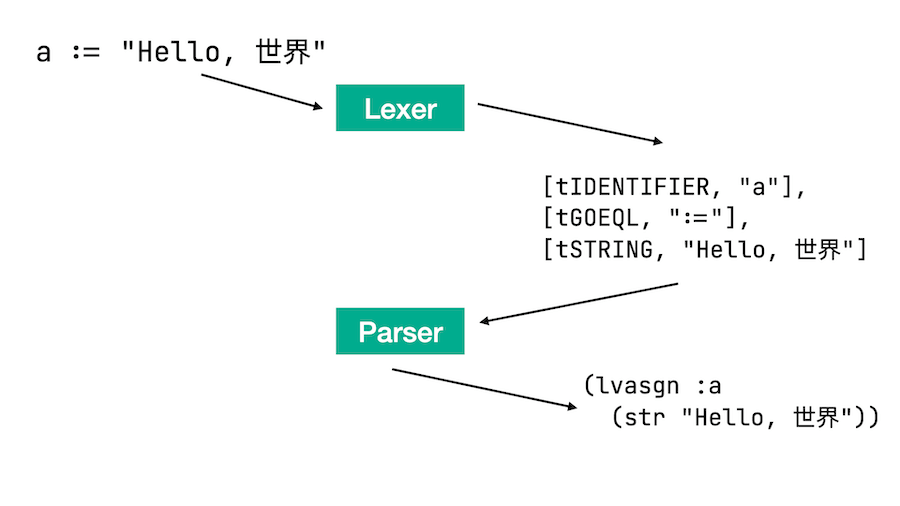
それが終われば、main.go.rbを読み込んでASTを取得し、元のコードを書き換えてからRubyで実行できるようになります。
parser gemのlexerはRagelで書かれています。Ragel State Machine Compilerは有限状態機械3コンパイラ兼パーサージェネレータです。Ragelは、正規表現やさままざまな論理ルールを含むコードを受け取り、ターゲット言語(C++、Java、Ruby、Goなど)に最適化されたステートマシンを出力します。
Ragelを現実に体感してみたい方は、Pumaの恐ろしく高速なHTTPパースをご覧ください。
ところで、私たちのlexerは最終的に2,500行程度に収まりました。Ragelを実行すると、24,000行近い最適化されたRubyクラスを得られます。
$ wc -l lib/parser/lexer.rl
2556 lib/parser/lexer.rl
$ ragel -F1 -R lib/parser/lexer.rl -o lib/parser/lexer.rb
$ wc -l lib/parser/lexer.rb
23780 lib/parser/lexer.rb
ここで目先を変えてソースコードをがっつり眺めてみましょうか?冗談です。そんなことより算術演算用のlexerを独自に書いてみましょう。
シンプルなlexerを書く
欲しいのは算術演算用のシンプルなlexerです。ここでは、ある文字列をこのlexerにかけるとトークンの配列に変換します。
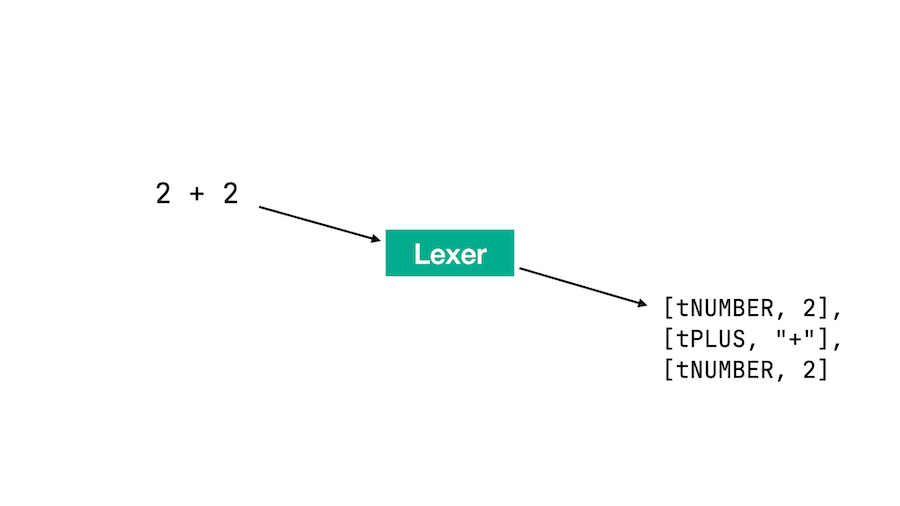
まずはRubyのクラスを定義します。これをLexerと呼ぶことにします。
class Lexer
def initialize
@data = nil # 入力される記号の配列
@ts = nil # トークンの開始インデックス
@te = nil # トークンの終了インデックス
@eof = nil # EOFインデックス
@tokens = [] # トークンの配列を得る
end
end
Ragelはこのクラスオブジェクトのコンテキストで動作し、data、ts、teが定義されることを前提とします。最終的なステートに達するには、eofというEOFインデックスが必要です。tokensは、ユーザーに返されるトークンの配列です。
それではステートマシンに取りかかりましょう。Ragelのコードは%%{ ... }%%の内側に置かれます。
class Lexer
%%{ # ハイライトを修正 %
# ステートマシンに命名する
machine ultimate_math_machine;
# 定義済み変数にアクセスする方法をRagelに指示する
access @;
variable eof @eof;
# 正規表現風のルール
number = ('-'?[0-9]+('.'[0-9]+)?);
# このステートマシンの主要なルール
main := |*
# 数値が渡されたら、解析された数値のインデックスを出力
number => { puts "number [#{@ts},#{@te}]" };
# 「any」は任意の記号用の定義済みRagelステートマシン
# 今はすべてを無視する
any;
*|;
}%% # ハイライトを修正 %
end
上のコードではultimate_math_machineという名前のステートマシンを定義し、定義済み変数にアクセスする方法をRagelに伝えています。次に数値を検出するための正規表現風ルールを定義しています。最後にステートマシン自身を宣言しています。
数値にさしかかると中かっこ[]内のRubyコードを実行します(ここではトークン種別とそのインデックスの出力)。現時点では、anyという定義済みステートマシンを用いて他の記号をすべてスキップしておきます。
残る作業はLexer#runメソッドの追加だけです。このメソッドは入力データを準備してRagelステートマシンを初期化し、実行します。
class Lexer
def run(input)
@data = input.unpack("c*")
@eof = @data.size
%%{ # ハイライトを修正 %
write data;
write init;
write exec;
}%% # ハイライトを修正 %
end
end
上のコードは入力文字列をunpackしてEOFインデックスを求めます。write dataとwrite initはRagelステートマシンの初期化で、write execで実行します。
このあたりでシンプルなステートマシンをコンパイルして実行してみましょう。
$ ragel -R lexer.rl -o lexer.rb
$ ruby -r './lexer.rb' -e 'Lexer.new.run("40 + 2")'
number [0,2]
number [5,6]
動きました!
今度は@tokensの配列に含まれるトークンを展開して演算子のルールをいくつか追加する必要があります。以下はRuby側のコードです。
class Lexer
# 計算機内のすべての記号とトークン名のリスト
PUNCTUATION = {
'+' => :tPLUS, '-' => :tMINUS,
'*' => :tSTAR, '/' => :tDIVIDE,
'(' => :tLPAREN, ')' => :tRPAREN
}
def run(input)
@data = input.unpack("c*") if input.is_a?(String)
@eof = input.length
%%{ # ハイライトを修正 %
write data;
write init;
write exec;
}%% # ハイライトを修正 %
# トークンを結果として返す
@tokens
end
# 入力の配列と現在のインデックスからサブ文字列を再構築する
def current_token
@data[@ts...@te].pack("c*")
end
# 得られた配列に現在のトークンをpushする
def emit(type, tok = current_token)
@tokens.push([type, tok])
end
# 渡されたtable(ハッシュ)でトークン種別を定義してemitを呼び出す
def emit_table(table)
token = current_token
emit(table[token], token)
end
end
ここで新たにメソッドをいくつか追加しました。Lexer#emitメソッドは、得られた配列にトークンを追加します。Lexer#emit_table(table)メソッドはPUNCTUATIONのハッシュを用いてトークンの種別を定義してから結果の配列に追加します。また、Lexer#runメソッドの末尾では@tokensを返しています。
今度はステートマシンに手を付けましょう。
class Lexer
%%{ # ハイライトを修正 %
machine ultimate_math_machine;
access @;
variable eof @eof;
# 正規表現風のルール
number = ('-'?[0-9]+('.'[0-9]+)?);
operator = "+" | "-" | "/" | "*";
paren = "(" | ")";
# このステートマシンの主要なルール
main := |*
# 数値が渡されたら、トークン種別:tNUMBERでemitを呼び出す
number => { emit(:tNUMBER) };
# 演算子か丸かっこが渡されたら
# PUNCTUATIONを指定してemmit_tableを呼び出し、トークンを選択する
operator | paren => { emit_table(PUNCTUATION) };
# スペースについてはRagelステートマシンにホワイトスペースが定義済み
space;
*|;
}%% # ハイライトを修正 %
end
ステートマシンが数値にさしかかるとLexer#emitメソッドを呼び出します。ステートマシンが演算子や丸かっこにさしかかるとLexer#emit_tableを呼び出します。また、ステートマシンのanyをspaceに書き換えて、ホワイトスペースをすべてスキップするようにします。完全なlexerは以下のgistにあります。
- Gist: lexer.rl
それでは再びコンパイルして実行してみましょう。
$ ragel -R lexer.rl -o lexer.rb
$ ruby -r './lexer.rb' -e 'p Lexer.new.run("2 + (8 * 5)")'
[[:tNUMBER, "2"], [:tPLUS, "+"], [:tLPAREN, "("], [:tNUMBER, "8"], [:tSTAR, "*"], [:tNUMBER, "5"], [:tRPAREN, ")"]]
トークンが出力されましたね!
Ruby Nextのlexer
これでparser gemのlexerを改造する準備が整いました。まずは PUNCTUATIONのハッシュに新しいトークンを追加しましょう。
PUNCTUATION = {
'=' => :tEQL, '&' => :tAMPER2, '|' => :tPIPE,
':=' => :tGOEQL, # other tokens
}
:=をpunctuation_endルールに追加します。
# すべての記号リスト(punctuation_beginを除く)
punctuation_end = ',' | '=' | ':=' | '->' | '(' | '[' |
']' | '::' | '?' | ':' | '.' | '..' | '...' ;
最後に、expr_fnameステートマシンのひとつに:=を追加します。追加場所は:の直前です。
'::'
=> { fhold; fhold; fgoto expr_end; };
':='
=> { fhold; fhold; fgoto expr_end; };
':'
=> { fhold; fgoto expr_beg; };
fholdとfgotoはRagel関数で、前者はインデックスを管理し、後者は次のステートマシンを呼び出します。
lexerの旅は後少しで終わります。テストを書いてチェックしてみましょう。
# test/ruby-next/test_lexer.rb
def test_go_eql
setup_lexer "next"
assert_scanned(
'foo := 42',
:tIDENTIFIER, 'foo', [0, 3],
:tGOEQL, ':=', [4, 6],
:tINTEGER, 42, [7, 9]
)
end
テストを実行してみるとすべて問題なく動いているので、いよいよパーサーに進みましょう!
「げげ、まだあるのか?」って?はい、まだありますとも。ここはEvil Martiansブログのガチ技術記事につき悪しからず。でもご心配なく、頂上はすぐそこです。気を取り直して進みましょう
進めや進め: パーサーに手を加える
ところで、本記事で”パーサー”という言葉が出現するたびに一気飲みするゲームを企画しているそこのお方、ぜひお止めください。弊社は結果に一切責任を持ちません。

このparser gemの内部にあるパーサーは、RubyのyaccであるRaccです(RakeでもRackでもありません)。RaccはRagelと同様に、入力で受け取ったファイルをコンパイルしてRubyクラスのパーサーを生成します。

Raccを動かすには、ルールのブロックを含む文法ファイルと、#next_tokenメソッドが定義されているパーサークラスを作成する必要があります。ここでは、parser gemが動く仕組みを理解するためにパーサーをゼロから手作りしてみることにします。lexerの出力をこのパーサーに入力してparser gemに渡し、ASTノードを出力として受け取ってみましょう。
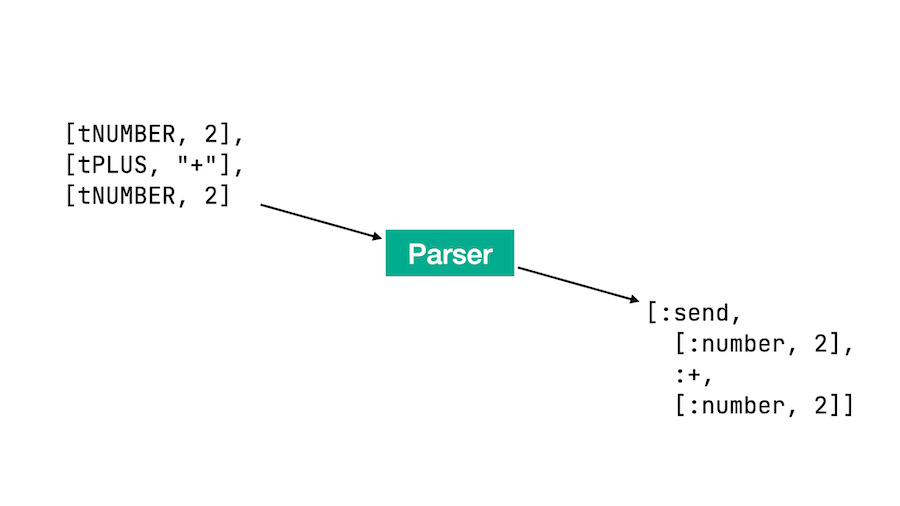
ところで、lexerとパーサーが両方必要な理由でお悩みの方は、2 + (1 + 7) * 5という算数の問題を考えてみてください。lexerの仕事はトークンのストリームを返すことだけであり、丸かっこ()や演算子の優先順位などには関知しません。そのようなASTノードのグループ化はパーサーの仕事です。
シンプルなパーサーを書いてみる
まずはMatchParserクラスを定義してパーサーを書いてみましょう。
class MathParser
# lexerから受け取るトークンの種別
token tPLUS tMINUS tSTAR
tDIVIDE tLPAREN tRPAREN
tNUMBER
# 演算子の優先順位
prechigh
left tSTAR tDIVIDE
left tPLUS tMINUS
preclow
rule
# expは他のルールのいずれか1つを表す
exp: operation
| paren
| number
# :numberノードを返す
number: tNUMBER { result = [:number, val[0]] }
# 丸かっこ内の結果を返す
paren: tLPAREN exp tRPAREN { result = val[1] }
# すべての演算子について:sendノードを返す
operation: exp tPLUS exp { result = [:send, val[0], val[1].to_sym, val[2]] }
| exp tMINUS exp { result = [:send, val[0], val[1].to_sym, val[2]] }
| exp tSTAR exp { result = [:send, val[0], val[1].to_sym, val[2]] }
| exp tDIVIDE exp { result = [:send, val[0], val[1].to_sym, val[2]] }
end
lexerのトークン種別はtokenブロックに記述し、演算子の優先順位はprechighブロックに記述します。最後にruleブロックに以下のルールを定義します。
number- パーサーが数値にさしかかったらASTノードを特殊変数
resultに追加する paren- 丸かっこ内部で式にさしかかったら、式のASTノードを返す
operation- パーサーが2項演算子にさしかかったら
:sendというASTノードを2つの式の演算子と結果のASTノード付きで返す
MathParserクラスの下には、---- headerや---- innerという特殊なブロックを定義できます。
# class MathParser ... end
---- header
require_relative "./lexer.rb"
---- inner
def parse(arg)
@tokens = Lexer.new.run(arg)
do_parse
end
def next_token
@tokens.shift
end
インポートは---- headerブロック内で定義できます。ここでは今作ったlexerをインポートしています。
---- innerブロック内ではパーサークラスのメソッドを定義できます。メインとなるMathParser#parseメソッドはlexerからトークンを受け取り、do_parseを呼び出して解析を開始します。MathParser#next_tokenメソッドは配列内のトークンを1個ずつ取り出します。パーサーの完全なコードは以下のgistに置いてあります。
- gist: parser.y
それでは、以下のようにビルドして実行してみましょう。
$ racc parser.y -o parser.rb
$ ruby -r './parser.rb' -e 'pp MathParser.new.parse("5 * (4 + 3) + 2");'
[:send,
[:send, [:number, "5"], :*, [:send, [:number, "4"], :+, [:number, "3"]]],
:+,
[:number, "2"]]
Ruby Nextのパーサー
手作りパーサーをコンパイルしてRubyパーサーを作成できたので、とうとうparser gemのパーサーに手を付ける準備が整いました。
よく使われる代入処理=が、このgemでどのように処理されるかを少し見てみましょう。
arg: lhs tEQL arg_rhs
{
result = @builder.assign(val[0], val[1], val[2])
}
#...
パーサーがtEQLトークンにさしかかると、Parser::Builders::Default#assignメソッドを呼び出して代入処理を行います。
def assign(lhs, eql_t, rhs)
(lhs << rhs).updated(
nil, nil,
location => lhs.loc
.with_operator(loc(eql_t))
.with_expression(join_exprs(lhs, rhs))
)
end
もう少し細かく見てみましょう。eql_t トークンが使われるタイミングは、明らかに入力テキストにある=演算子の位置を算出するときだけです。つまり、このメソッドを新しいトークン用に使い回せば、それだけで期待どおりに動くということです。
それでは新しい tGOEQLトークンを追加しましょう。
token kCLASS kMODULE kDEF kUNDEF kBEGIN kRESCUE kENSURE kEND kIF kUNLESS
# ...
tRATIONAL tIMAGINARY tLABEL_END tANDDOT tMETHREF tBDOT2 tBDOT3
tGOEQL
次に、tEQLトークンを用いる代入処理のルールを見つけ出して複製し、そのトークンを tGOEQLに置き換えます。
command_asgn: lhs tEQL command_rhs
{
result = @builder.assign(val[0], val[1], val[2])
}
| lhs tGOEQL command_rhs
{
result = @builder.go_assign(val[0], val[1], val[2])
}
#...
arg: lhs tEQL arg_rhs
{
result = @builder.assign(val[0], val[1], val[2])
}
| lhs tGOEQL arg_rhs
{
result = @builder.go_assign(val[0], val[1], val[2])
}
#...
できました!テストを追加しましょう。
# test/ruby-next/test_parser.rb
def test_go_eql
assert_parses(
s(:lvasgn, :foo, s(:int, 42)),
%q{foo := 42},
%q{ ^^ operator
|~~~~~~~~~ expression},
SINCE_NEXT
)
end
テストを実行すると、すべて問題なく動作していることがわかります。これでparser gemで:=を扱う準備が整いました。
次はどんな作業でしょうか?
“お次”はRuby Next
Ruby Nextには複数のモードが用意されています。トランスパイラモードでは、ファイルをRuby Nextに渡してコードを書き換えさせ、これを出力とします(このあたりはRaccやRagelと同じですね)。ランタイムモードでは、ファイルを実行中にRuby Nextがパッチを当てます。
ここではどちらのモードを選ぶかは重要ではありません。どちらの場合も、ソースコードがlexerとパーサーで処理されて、最終的にはRuby Nextで利用可能なリライターで処理されます。
ここで新しいASTノードが従来の一般的な代入処理のASTノードと違う点は、演算子の違いだけです。
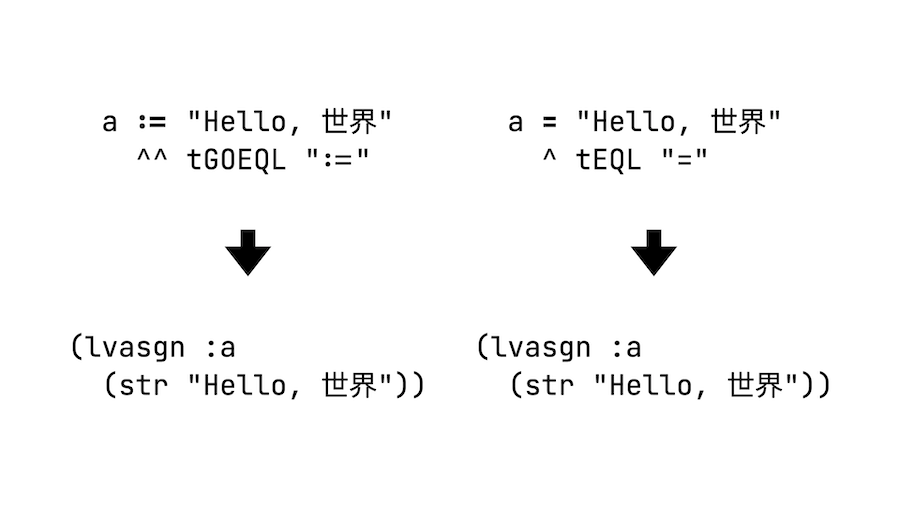
それではRuby Nextのリライターを書いて置き換えてみましょう。
新しいASTノードをキャッチするには、"on_#{ast_type}"というメソッドを定義する必要があります。ここではASTノードの種別がlvasgnなので、メソッド名は#on_lvasgnになります。
# lib/ruby-next/language/rewriters/go_assign.rb
module RubyNext
module Language
module Rewriters
class GoAssign < Base
NAME = "go-assign".freeze
SYNTAX_PROBE = "foo := 42".freeze
MIN_SUPPORTED_VERSION = Gem::Version.new(RubyNext::NEXT_VERSION)
def on_lvasgn(node)
# 演算子が既に'='の場合はスキップ
return if node.loc.operator == "="
# ast-nodeを「リライト必要」とマーキングする
context.track! self
# 演算子を'='に置き換える
replace(node.loc.operator, "=")
end
end
end
end
end
on_lvasgnメソッドの内部では、ノードの演算子をチェックし、=でない場合はそのノードを「リライト必要」とマーキングしてから、:=演算子を=に書き換えます。
次に、この新しいリライターをRubyNext::Language.rewritersに追加する形で登録します。lib/ruby-next/language/proposed.rbに以下のように手を加えることで、“proposed feature”扱いで登録してみましょう。
# lib/ruby-next/language/proposed.rb
# ...
require "ruby-next/language/rewriters/go_assign"
RubyNext::Language.rewriters << RubyNext::Language::Rewriters::GoAssign
ここまでできたので、冒頭のGoコードを再録します。
# main.go.rb
package main
import "fmt"
func main() {
s := "Hello, 世界"
fmt.Println(s)
}
最後に、uby-next.rbをrequireしてから実行します。
$ ruby -ruby-next -r './go_ruby.rb' main.go.rb
Hello, 世界
やりました!この素晴らしい成果をしばし絵文字でお祝いしましょう。残念ながらここで達成したことを的確に表現できる絵文字がないので、こちらのストロー付きコップをどうぞ: 
“真面目な”結論
上の「OK, Go」という曲のPVではありませんが、私たちはルーブ・ゴールドバーグ・マシン4ならぬRuby Go-berg Machineの実験で少々横道にそれたようなので、ここで冒頭の疑問「そんなにいいなら全部Goで書けばいいのに?」に立ち返ることにしましょう。
本記事では、Goの機能を再現するためにRubyの超強力なDSLを用いました。そこで生じた問題を解決しつつ、ruby-nextがruby-next-parser gemを利用する方法を学びました。さらにlexerとパーサーを手作りし、最後はruby-next-parserに手を加えてruby-nextに新しいリライターを追加しました。
このような美しくも頭がどうかしている世界をGoだけで手軽に実現できるでしょうか?さすがに無理ですね。
Rubyは”文字通り”何でもできるレベルで強力です。RubyでGoコードを動かせるようにしてみんなの貴重な時間をすりつぶすこともできます 。Go自身でRubyを動かすとしたら、Ruby VMを実装するかmrubyのCバインディングを使うかする必要があり、RubyでDSLを書いたりパーサーを2行ばかり書き換えるほど手軽にというわけにはいかないでしょう。
。Go自身でRubyを動かすとしたら、Ruby VMを実装するかmrubyのCバインディングを使うかする必要があり、RubyでDSLを書いたりパーサーを2行ばかり書き換えるほど手軽にというわけにはいかないでしょう。
とは言うものの、RubyでGoコードを書く実用的な理由などありはしません。しかし新しいスゴ技を1つ身に付けられたのですから、そんなことは問題ではありません!Rubyを文字通り心ゆくまで魔改造できるなら、とことんやるまでです。徹底的に遊び倒し、実装を現実世界で試し、最高のアイデアを得たらRuby Issue Trackerに提案してみましょう。”Rubyの大いなる能力は大いなるパワーを伴う”5(で合ってましたっけ?)。
関連記事
- 訳注: “let it go”(行かせる)のもじりです。参考: Let It Go ↩
-
訳注: 原文では米国の長寿クイズ番組「ジェパディ! 」のテーマ音楽のYouTube動画(
https://www.youtube.com/watch?v=IkdmOVejUlI)にリンクされていましたが、その後リンクが無効になっていたので、同じ曲の別動画にリンクしました。 ↩ - 有限オートマトン – Wikipedia ↩
- 訳注: 日本で言う「ピタゴラスイッチ」に相当します。参考: ルーブ・ゴールドバーグ・マシン – Wikipedia ↩
- 訳注: これはMatzがときどき引き合いに出す「Great power comes with great responsibility.」のもじりです。参考: 大いなる力には、大いなる責任が伴う – Wikipedia ↩
The post RubyファイルにGoコードを書いてRuby Nextで動かす(翻訳) first appeared on TechRacho.
概要
原著者の許諾を得て翻訳・公開いたします。
日本語タイトルは内容に即したものにしました。