
概要
原著者の許諾を得て翻訳・公開いたします。
- 英語記事: Exploring the Linguistics Behind Regular Expressions
- 原文公開日: 2017/11/20
- 著者: Alaina Kafkes
訳注: 原文タイトルは「正規表現を背後で支える言語学を理解する」といったニュアンスです。翻訳記事タイトルでは内容を把握しやすくするため「チョムスキー」を加えました。
正規表現をチョムスキー言語学まで遡って理解する(翻訳)
正規表現は、新人/ベテランを問わずプログラマーに恐怖心を呼び起こします。私が最初に正規表現(しばしばregexと略記されます)というものを目にしたときも、()だの*だの文字だの数字だので構成された祈祷書を読んでいるうちにめまいがしてきたのを覚えています。正規表現はナンセンスで理解不能なものに思えたのです。
正規表現は、高度なコンピュータサイエンス(CS)学科で扱われるのだろうと思っていました。それならば正規表現に取り組む気になったことでしょう。しかし私が正規表現に出会ったのは、学部4年になるまで先延ばしにしていた入門クラスだったのです。このコースの目的は、暗号学/人間とコンピュータのインタラクション/機械学習の概念を紹介することで、コードを1行も書いたことがない学生をCSに引きずり込むことでした。ところで機械学習はこの中で唯一の最新かつ最大の技術系バズワードですね。
レクチャーには数回ぐらいしか出席していませんでしたが、その中で出された課題の1つで私は頭を抱えてしまいました。CSに影響を与えたコンピュータサイエンティストか学者についてエッセイを1本書かなければならなかったのです。そのときはノーム・チョムスキーを選択しました。
そのときは知る由もありませんでしたが、チョムスキーについて学ぶうちに私は正規表現というウサギの穴に再び引きずり込まれ、いつしか正規表現が魔法のごとく別の何かに姿を変える様子にすっかり魅了されてしまいました。私が正規表現で夢中になったのは、正規表現のパワーの源たる、同じ名前の言語的なコンセプトの方でした。
正規表現を背後で支える言語学、すなわちほとんどのプログラマーに知られていない背景を知ることで、皆さまも正規表現を好きになっていただければと思います。ここでは特定のプログラミング言語での正規表現の使い方を解説するつもりはありませんが、言語としての正規表現をご紹介することで、皆さまが選んだプログラミング言語で正規表現がどのように機能しているのかを深く追求するきっかけになれば幸いです。
まずはチョムスキーに話を戻しましょう。チョムスキーのどのあたりが正規表現に関係あるのでしょうか?そもそもチョムスキーがCSと何の関係があるのでしょうか?
なりゆきコンピュータサイエンティスト
Wikipediaにはノーム・チョムスキーは言語学者、哲学者、認知科学者、歴史家、社会批評家、政治活動家と記載されていますが、コンピュータサイエンティストとは書かれていません。チョムスキーはそれらのすべての分野で重要な業績を残しているため、CSへの間接的な貢献は見落とされがちです。
チョムスキーの学術上の業績を調べるうちに、チョムスキーのコンピューティングへの興味が偶然であったという思いが強くなりました。このことから、チョムスキーの業績は一見CSとは無関係に見えたとしても、分野を問わずコンピューティングやIT業界に何かしら寄与しているという私の信念が裏付けられました。
とりわけチョムスキーによる言語学方面の功績は、CSの学際的な研究が与えたインパクトの好例です。チョムスキー階層は、コンピュータサイエンティスト/ソフトウェアエンジニア/ホビイストが日常的に書いているコードに転換されました。
そう、CSに正規表現なるものをもたらしたのは、この階層という概念だったのです。しかしチョムスキーから正規表現への飛躍を理解する前に、チョムスキー階層の概要について説明します。
言語の規則と秩序
チョムスキー階層とは、形式文法の秩序化です。それぞれの文法が、階層上で上位の文法の真部分集合となるような、形式言語の統語論的(syntactic)な規則を考えてみましょう。ある形式言語の文法は他のものよりも厳密であることから、チョムスキーは形式言語を彼の名を冠した階層に編成することを追求しました。
先ほど、形式文法は統語論的な規則であるということについて簡単に触れました。この規則は、与えられた形式言語で有効なあらゆる句(phrase)を与えます。文法は、言語を作り上げる規則を提供します。言語学者の言い方を借りれば、ある言語の形式文法は、非終端(nonterminal: 入力または中間文字列値)を終端(terminal: 出力文字列値)に変換できるフレームワークを提供します。
この目新しい語彙を解明するために、既成の形式文法を用いて非終端の集合を終端に変換する例を1つお目にかけましょう。なんちゃって形式言語「Parseltongue」(訳注: ハリー・ポッターシリーズの「蛇語」のこと)には次の形式文法があるとします。
- 終端: {s, sh, ss}
- 非終端: {snake, I, am}
- 生成規則: {I → sh, am → s, snake → ss}
この生成規則を使って、「I am snake」という文を「sh s ss」に変換できます。この変換は次のように部分ごとに行われます。「I am snake」→「sh am snake」→「sh s snake」→「sh s ss」
蛇語の例から、非終端文字列が形式文法によって終端のみの文字列に構文解析される様子がわかります。しかし形式文法は言語を生成するだけではなく、ある文字列が形式文法に一致するかどうかを認識する装置でもあります。例の「I am a snake」という文字列はもれなく終端に変換できますが、「I am not a snake」という文字列は蛇語では記述できません。非終端の「not」は蛇語の終端に翻訳できないからです。
大事なことなので2回書きます。形式文法は形式言語を生成します。これは、形式文法の階層を作り出すことによって、チョムスキーは言語そのものも分類したということです。
面倒な前書きはここまでにして、チョムスキー階層における4種類の形式文法を見てみることにしましょう。制約が最も強いものから順に次の種類があります。
- 正規文法
- 入力文字列から出力文字列までの過去の情報を保持しない
- 文脈自由文法
- 入力文字列から出力文字列までの、直近のステート情報のみを保持する
- 文脈依存文法
- 入力文字列から出力文字列までの過去のステート情報をすべて保持する
- 制限なし文法(帰納的可算文法)
- ステート情報をすべて保持することで、与えられた入力文字列から想定可能なあらゆる出力文字列を作成できる
この「ステート情報(state knowledge)」とは一体何だかおわかりでしょうか。Wikipediaのスコープの記載に基いて考えてみましょう。たとえば正規文法は、入力文字列を出力文字列に変換する処理において、文字列の過去のステートに関する情報を自身の「スコープ」内で保持しません。これは、文法が個別に非終端を終端(およびゼロ以上の非終端数列)に変換した後は、文法は文字列の過去のステートを忘れてしまうということです。
一方、制限なし文法の場合は、翻訳する文字列のすべての可能な状態を保持します。文脈自由文法や文脈依存文法は、両者の中間のどこかに位置します。
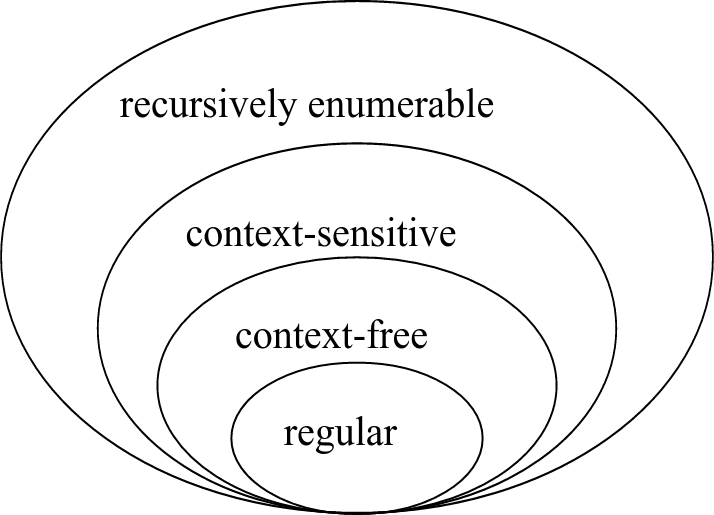
チョムスキー階層の文法を詳しく知りたければ、オートマトン理論をのぞいてみる必要があるでしょう。ここからは、正規表現に関連する文法を中心に解説します。この文法には「正規文法(regular grammar)」というぴったりな名前がつけられています。
正規表現ではどうなるか
正規表現と正規文法は同等です。両者の形式は異なりますが、どちらも同じ統語論的規則の集合を表現し、同じ正規言語を生成します。
言語学的には、正規表現は次のように再帰的に定義されます。
- 空集合は正規表現である。
- 空文字列は正規表現である。
- 入力アルファベット中の任意の文字
xについて、xは正規言語{x}を生成する正規表現である。 - 選択(alternation):
xとyが正規表現であれば、x | yは正規表現である。たとえば正規表現0|1からは正規言語{0,1}が生成される。 - 連結(concatenation):
xとyが正規表現であれば、x - yは正規表現である。たとえば正規表現0-1からは正規言語{01}が生成される。 - 反復(repetition)(またはクリーネ閉包):
xとyが正規表現であれば、x*は正規表現である。たとえば正規表現0-1*からは正規言語{0, 01, 011, 0111, ...}が無限に生成される。
正規文法は、先ほどの蛇語のような規則の組み合わせでできています。ある正規文法を使って入力文字列を構文解析して出力文字列にできるように、正規表現もおおむね同じように文字列を変換できます。正規表現で採用されているこの「選択/連結/反復」操作(先のアナロジーで言うなら、規則)のさまざまな解析例があります。
ここで少しだけ親愛なるノーム・チョムスキーに話を戻しましょう。チョムスキーの文法階層や正規文法は、入力文字列を出力文字列に変換するときの手順に関する情報を一切保持しません。これが正規表現においてどのような意味を持つかおわかりでしょうか。
正規文法のこの「忘却」は、文字列のある部分の翻訳は、その後に翻訳される別の非終端部分の翻訳に何の影響も与えないということです。出力文字列の作成において、文字列のさまざまな部分が互いに影響することはありません。
正規文法を支える言語学から、最初にプログラマーたちが正規表現をコードに組み込んだ理由について洞察を得ることができます。ここまでは言語を生成/認識する形式文法についてのみ議論してきましたが、正規文法が入力文字列の断片を1つずつ出力文字列に変換するという事実によって、パターンマッチャーとして使うことができるのです。プログラミングにおける正規表現では、生成規則を用いて入力文字列(パターン)を正規言語(パターンにマッチする文字列の集合)に変換します。
しかし、プログラミング言語の作者たちが言語学の分野で定義されているとおりに正規表現を実装していたのであれば、私はこの記事を書くことはなかったでしょう。コンピュータの正規表現は、言語学でいち早く登場した正規表現とは似ても似つかないものになっていますが、本記事で解説した言語学の正規表現は、コードに含まれる正規表現を理解するための有用な枠組みを提供してくれます。
似ていて違う正規表現とregex
訳注: 「Two Regular Expressions, Both Alike in Dignity」はシェークスピアの「ロメオとジュリエット」の前口上のもじりです。
ここからは、言語学的な意味での正規表現を正規表現、プログラミングにおける正規表現をregexと使い分けることにします。言語学的な正規表現とプログラミングの正規表現はかなり違っているにもかかわらず、世間ではどちらも正規表現と呼ばれてしまっています。何とも紛らわしいことです。
正規表現とregexの違いは、利用法から生じたものです。正規表現(正規文法)は形式言語理論の一部であり、自然言語における共有要素を記述するために存在しています。自然言語とは、人間が計画的に設計したものではない、長年に渡って進化を繰り返している言語を指します。言語学者は正規表現という言葉を理論のために用います(チョムスキー階層における形式文法の分類など)。正規表現は、人間が話す言葉を言語学者が理解するうえで役に立ちます。
一方regexは、与えられたパターンにマッチする文字列を検索する目的でプログラマーたちが毎日使っているものです。正規表現は理論に寄っていますが、regexは実用に即しています。プログラミング言語は形式言語ですが、人間(ここではプログラマーたち)によって設計された特定の目的のための言語です。お気づきの方もいらっしゃるかと思いますが、プログラミング言語の作者たちはコードのregexの機能を増強しました。どんな拡張が施されたのか見てみましょう。
正規表現には選択/連結/反復の3つの操作があることを思い出しましょう。私はregexのプロではありませんが(regexpertとでも言うんでしょうか?)、Wikipediaの正規表現をのぞいてみただけでも、regexには3つの操作以上のものが実装されていることがわかります。
たとえばPOSIXのregex文法を使う場合、.orkは「orkという3つの文字で終わる4つの文字すべて」にマッチします。このピリオド.は、単純な選択/連結/反復よりも強力だと思いますか?
違います。実を言うと、最も高度なregexメタ文字(regex操作を呼び出す文字)ですら、正規表現の操作から派生したものなのです。仮に、アルファベットに含まれる26個の小文字だけを含む正規文法があるとすると、regexパターン.orkは[a|b|c|...|z]orkのように正規表現の操作だけで記述できます。
regexにはメタ文字がやたらめったらあるので正規表現よりずっと強力な操作セットを備えているように思えますが、メタ文字は正規表現を定義するさまざまな操作を置き換える便利なショートカットに過ぎません。regexのメタ文字は、選択/連結/反復のよくある組み合わせをプログラマー好みの形に抽象化したものを提供しています。
ここまではregexというものを、正規表現に便利なショートカットや明確なユースケースを加えたものとして表しました。しかし、チョムスキー階層を思い出してみれば、正規文法は規則の中でも最も制約が強いものであり、スコープを持たないのです。ありがたいことに、regexは言語学の先輩である正規表現に比べて少しばかりユルいので、実用面でより強力なものになっています。
正規文法規則からはみ出す
チョムスキー階層によれば、正規文法には入力文字列を出力文字列に変換する際の情報が保持されないことを思い出しましょう。正規表現は正規文法と同等なので、正規表現には文字列が入力から出力に変わるときの中間ステートを記憶する場所がありません。言い換えると、ある正規表現に含まれる非終端の翻訳は、正規表現の他の部分の非終端の翻訳に影響しないということでもあります。
regexではこのようになっていません。regexでは後方参照をサポートするために、正規文法の重要な特性に違反しています。後方参照(backreferencing)が使えることで、プログラマーは正規表現を丸かっこ()で区切ってメタ文字でその部分を参照できます。たとえば、(la)\1というパターンは「lala」という文字にマッチするときに\1というメタ文字を使って「la」という文字の検索を反復します。
正規表現において文字列の各部分は互いに影響を与えられないため、regexの後方参照は先輩よりもずっと強力です。さらに重要なのは、後方参照には、1行の中である語を誤って2回続けて書いてしまった場合にその誤りを検索するという実用的な使いみちがあるという点です。実用という観点から見ることで、正規表現がプログラミングのregexでどのように改変されたのかを洞察できます。
regexの機能をさらに高めているのは、いわゆる「マッチの欲張り具合」を変更できる機能です。regexパターンのカテゴリである量指定子(quantifier)にはさまざまなものがありますが、これらは見た目が似ていても文字列の一部にマッチするときの挙動が大きく異なります。欲張り量指定子/最長一致量指定子(greedy quantifier)である*は文字列に可能な限り長く一致しようとしますが、ものぐさ量指定子/最小一致量指定子(reluctant quantifier)である?は文字列の一致する長さを最小限にしようとします。「abcorgi」という文字列が与えられていると、パターンが.*corgiの場合は文字列全体にマッチしますが、パターンが.?corgiの場合は「bcorgi」だけにマッチします。
所有量指定子(posessive quantifier)である+は文字列に対して最長一致を試みますが、欲張り量指定子の*と異なり、最大一致を見つける際に文字列の直前の文字をバックトラックしません。「abcorgi」という文字列が与えられている場合、.*corgiと.+corgiはどちらも文字列全体にマッチします。所有量指定子と欲張り量指定子の結果は多くの場合同じですが、所有量指定子はバックトラックを回避するので効率が高まる傾向があります。
量指定子はメタ文字なので、技術的には正規表現の3つの操作である選択/連結/反復を組み合わせて作ることも可能です。しかし、量指定子の作り出すシンプルな抽象化によって、プログラマーが欲しいマッチの種類を素早く指定することができます。
まとめと関連書籍
長旅お疲れさまでした!チョムスキーと彼の名を冠したチョムスキー階層について学び、正規文法を深く深く掘り下げました。そして正規文法から始まって、正規表現の言語学上の定義を調べました。最後に、プログラマーが日常的にregexを使いたくなるよう正規表現とregexの違いに着目しました。
本記事ではチョムスキーから現代的なプログラミング言語まで正規表現の歴史を辿りましたが、regexのお話はこれでおしまいではありません。言語学的な正規表現やコンピュータのregexをもっと学びたい方向けに、学習のはかどる問いかけをいくつかご用意いたしました。
- オートマトン理論とは何か?チョムスキー階層とどのように関連しているか?
- regexはどのように実装されているか?さまざまなregexアルゴリズムにはどのようなトレードオフが存在するか?
- 文字列マッチや操作を行う組み込みライブラリではなくregexを使うのが適切なのはどのような状況か?
また、正規表現の言語学的側面やコンピュータに関連する要素を私が研究していたときに用いた資料のリストもご用意いたしました。regexでお楽しみください!
- Regular-Expressions.info
- Wikipedia: Regular Expressions
- StackOverflow: Chomsky Hierarchy in plain English
- Introduction to Automata Theory, Languages, and Computation by Hopcroft et al.
- StackOverflow: Difference between regular expression and grammar in automata
- How to Think like a Computer Scientist: Formal and Natural Languages
- Oracle’s Java Tutorials: Quantifiers
- StackOverflow: Compare regex in programming languages with regular expression from automata/formal language
- Quora: How are regular expressions implemented?
本記事をお楽しみいただけた方は、ぜひ[いいね]ボタンのクリックや記事の共有をお願いいたします。
不明な点やご意見がありましたら、Twitterかコメント欄までどうぞ。本記事はMediumで最初に公開されました。