
- 前記事: RabbitMQはSidekiqと同等以上だと思う: 前編(翻訳)
- 次記事: RabbitMQはSidekiqと同等以上だと思う: 後編(翻訳)
概要
原著者の許諾を得て翻訳・公開いたします。
- 英語記事: RabbitMQ is more than a Sidekiq replacement – Not again
- 原文公開日: 2018/03/07
- 著者: Stanko Krtalić Rusendić
原文が長いため、3本に分割します。後編は今後公開いたします。
RabbitMQはSidekiqと同等以上だと思う: 中編(翻訳)
Sidekiqのメモリ問題
有償のフォールトトレーランスにしたとしても、SidekiqではジョブキューにRedisを使うため、メモリ消費の問題があります。Redisは前述のようにデータストアがメモリ上に配置され、かつ、使われなくなったデータをディスクに逃がすしくみがありません。つまりキューのジョブはすべてメモリ上にまとめて保持されていることになります。
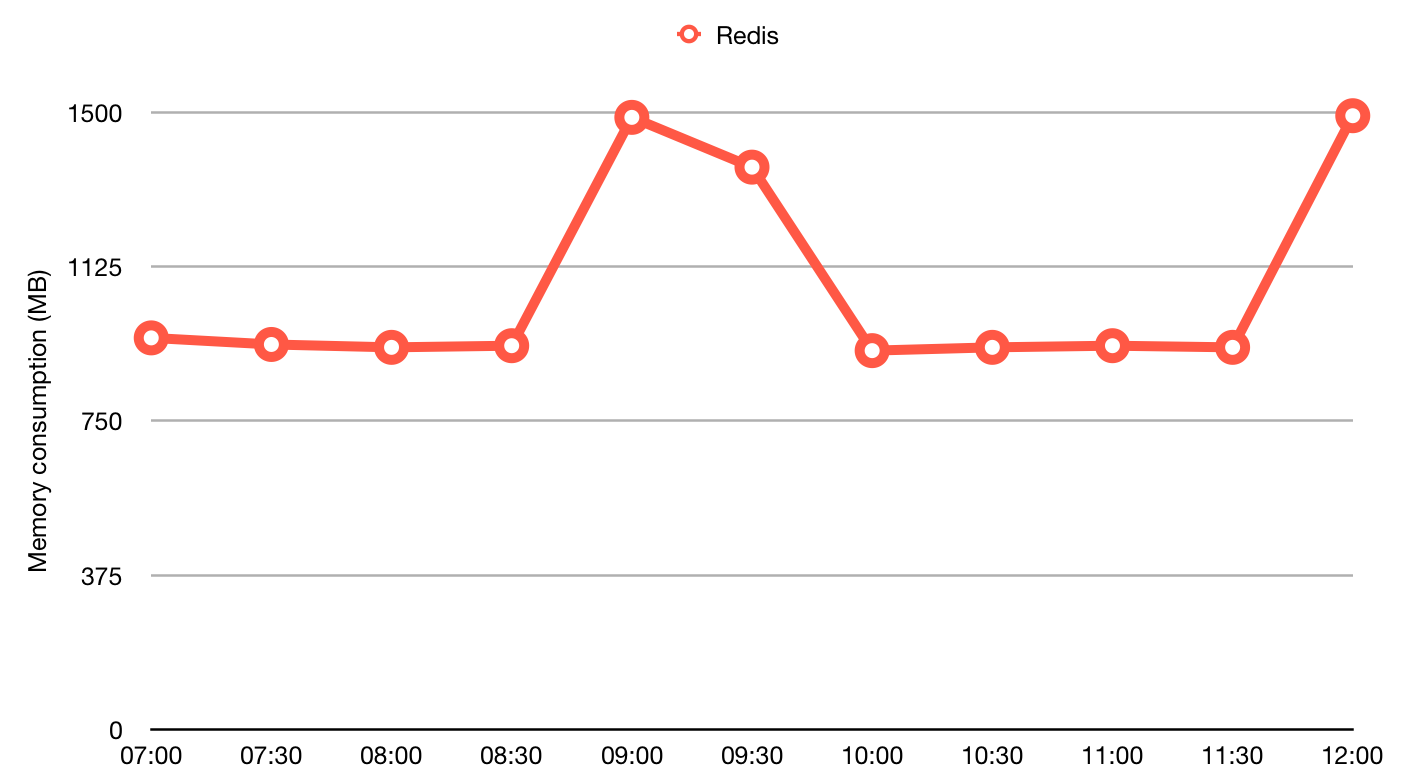
この問題解決に最もよく使われるのは、ジョブキューの値ではなくデータベースレコードのIDを渡すという方法です。これによってRedisのメモリ消費は抑えられますが、SidekiqやRubyのメモリ使用量は逆に増加します。メモリ使用量が増加するのは、Sidekiqの各インスタンスでモデルアクセスのためにアプリを初期化する必要があるためです。これは、軽量なRubyプロセスとして独自のワーカーを自作することで解決できる可能性がありますが、私たちの場合、2つの異なるアプリ(ワーカーと、メインのアプリ)でモデルやデータベースアクセスの情報を管理するときに問題になります。別の解決方法は、メインアプリのAPIを消費することですが、その結果私たちのところではアプリの負荷を下げるどころか増加しています。
RabbitMQはこれらの問題をどう解決するか
RabbitMQは汎用のメッセージキューです。RabbitMQを「バックグラウンドワーカー方式」のバックエンドシナリオで利用するには、RabbitMQのライブラリにアクセスする必要があります。これはSneakersで行うことを強くおすすめします。Sneakersはワーカープロセスの作成/管理、キューの作成/キューの送信などSidekiqでできることはすべて行え、Sidekiqとよく似た構文が使えます(Gist)。
# SneakersとSidekiqワーカーの実装例
class SneakersLogger
include Sneakers::Worker
# キューとそのオプションを定義
from_queue 'loggings'
def work(log_message)
Logger.log(log_message)
# ここで繰り広げられるマジックは次のセクションで解説
ack!
end
end
# ---
class SidekiqLogger
include Sidekiq::Worker
def perform(log_message)
Logger.log(log_message)
end
end
SidekiqとRabbitMQの実装における最大の違いは、10行目のack!です。これを書くことでSneakersとRabbitMSにジョブの実行を保証させられるようになります。これはRabbitMQのコミュニケーションプロトコルであるAMQPの機能です。AMQPのメッセージを取り出すときのモードは、ackモードとno-ackモードの2種類があります。
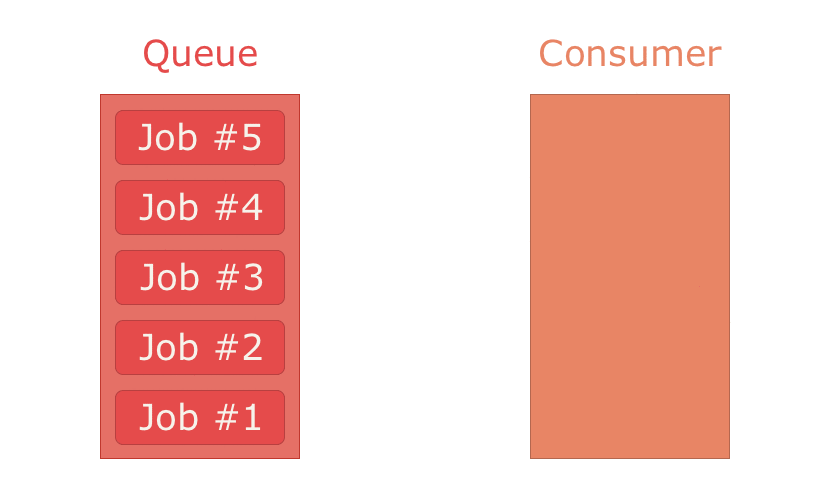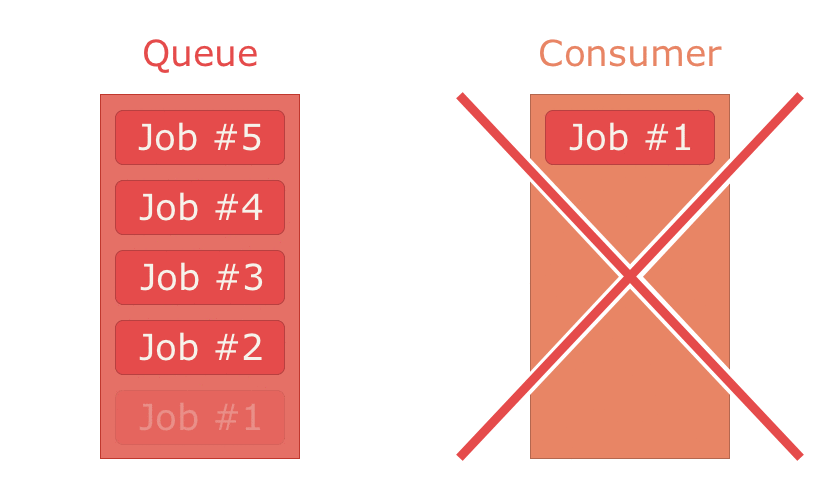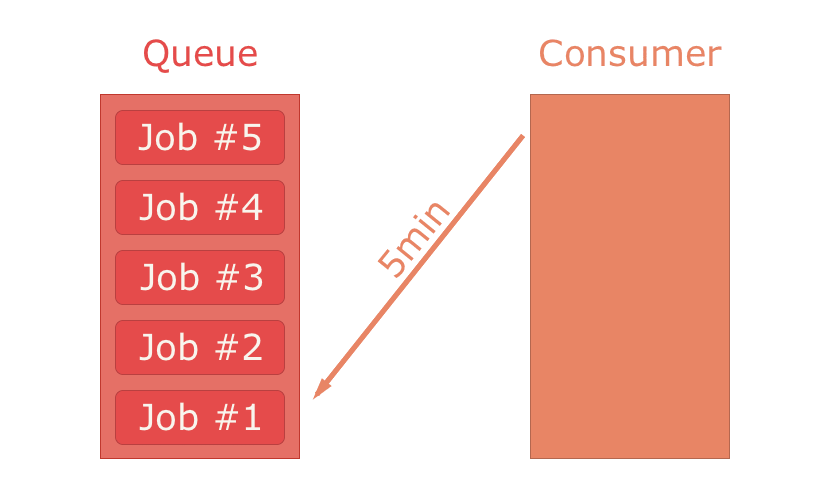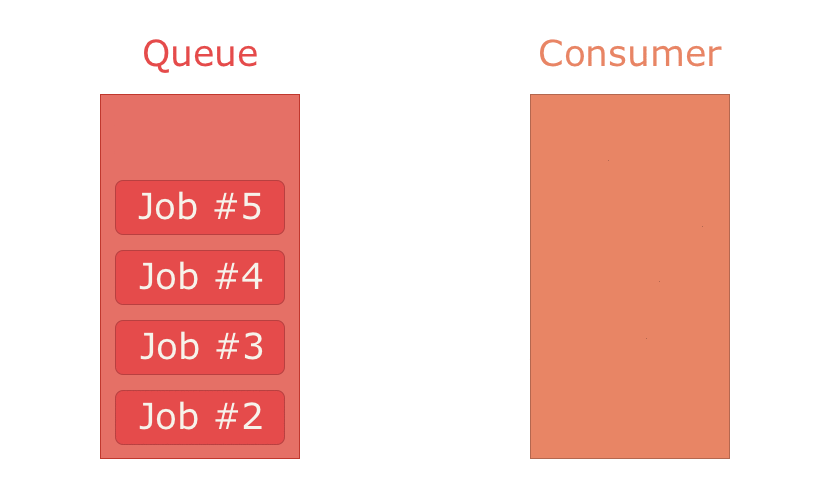
ackモードの場合、コンシューマー(consumer)はメッセージが処理されたことをackする(=応答を返す)タイムウィンドウを1つ指定しなければなりません。言い換えると、ackモードではコンシューマーがメッセージ処理の最大所要時間を指定しなければなりません。コンシューマーがキューからメッセージを1件取り出すと、キュー内のメッセージは事実上削除されますが、RabbitMQはそのコピーを保持し続けます。コンシューマーがack信号を指定の時間内に返せなかった場合は、メッセージがキューの先頭に戻されます。コンシューマーがack信号を指定の時間内に無事返せた場合、メッセージはRabbitMQから完全に削除されます。no-ackモードの場合は保証がないので、タイムウィンドウの指定もありませんし”ack”信号を返す義務もありません。
他にも、メモリ消費に違いがあります。デフォルトのRabbitMQは可能な限り多くのメモリを確保します。設定可能な基準点に達した時点で、適切なメッセージをすべてディスクに逃します。ただしすべてのキューがこのように処理されるわけではありません。RabbitMQは、可能な場合にすべてのメッセージをディスクに保持する「遅延キュー」(lazy queue)機能もサポートします。これは巨大なメッセージを渡す場合に便利です。
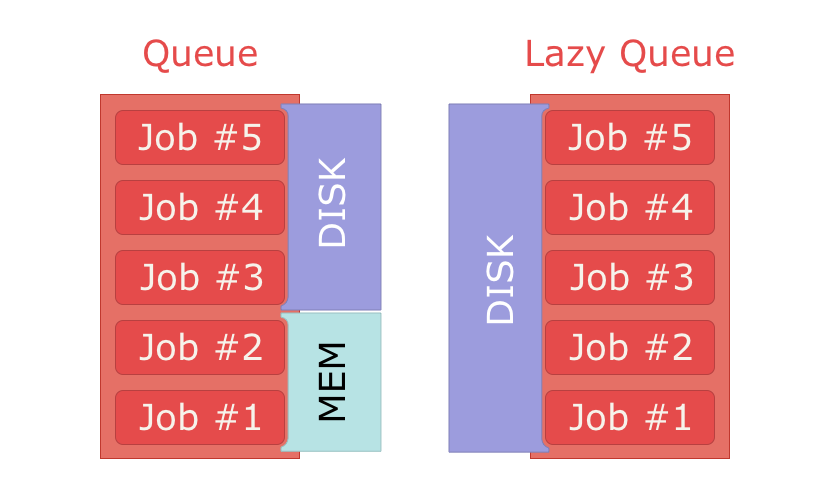
これらの機能によって、巨大なペイロードを扱える信頼性の高いジョブキューを作成できるようになります。データベースにアクセスしない軽量Rubyプロセスでワーカーを自作できます。高性能やメモリ消費を要求されずに、ジョブをキューで処理するのに必要なデータをこれですべて受けることができます。
ここで、本記事でまだ触れていなかったSidekiqの機能がひとつあります。UIです。Sidekiqは、ジョブの健全性や一般的なスループットの監視に役立つ便利なUIを備えています。

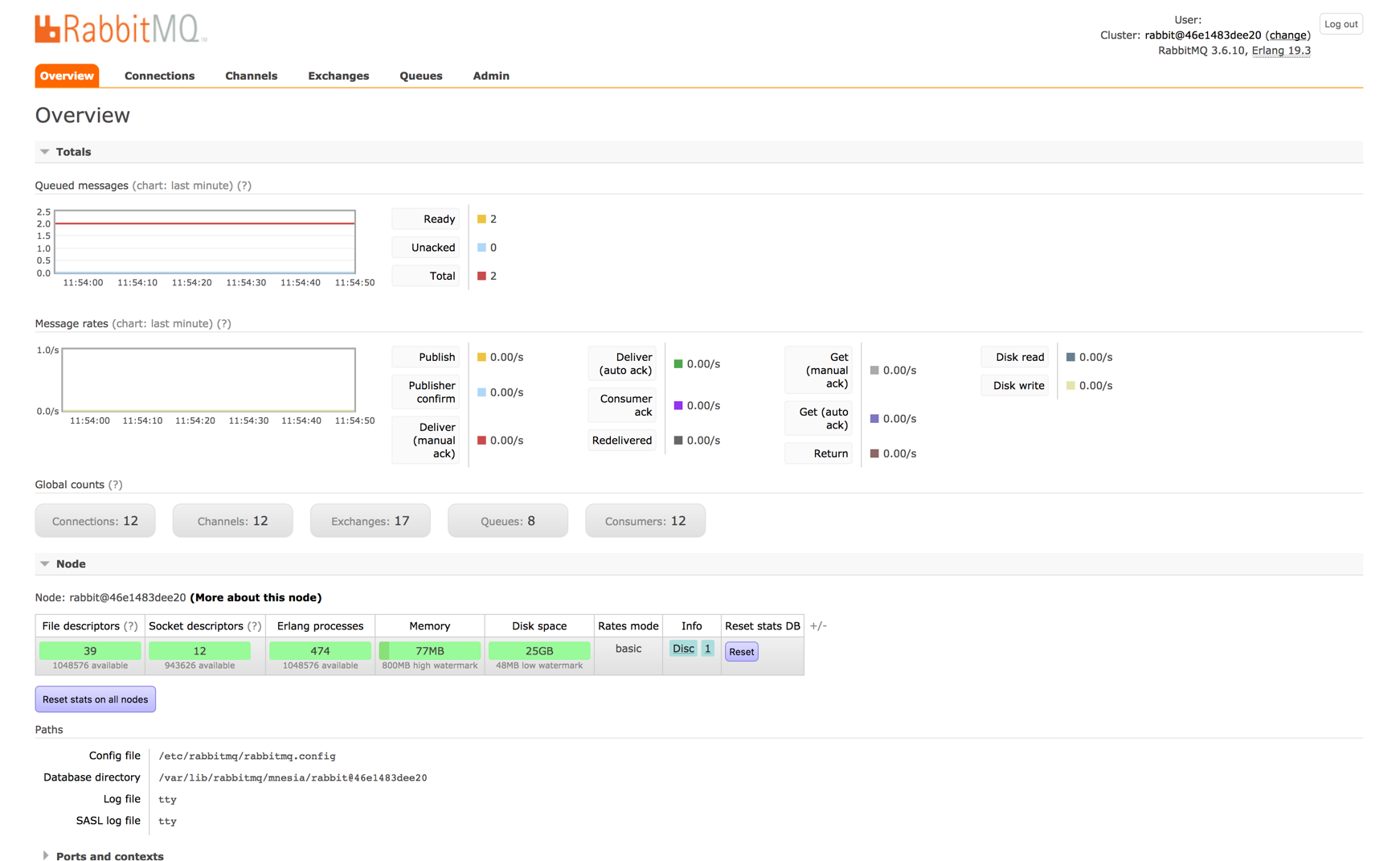
RabbitMQにはさらに強力なUIがあり、失敗/成功件数の洞察の他にも、ディスクやRAMといったシステムリソースの使用量をグローバルおよびキューごとに表示したり、メッセージをUIから直接コンシューム(consume)およびパブリッシュしたり、コンシューマーやユーザーの管理機能、ログイン画面といったさまざまな機能があります。こうした機能はSidekiqではプレミアム版(1950ドル/年)の機能で使えます(さらにワーカー数は価格単位あたり100個までとなります)。
「exchange」
AMQPでは「exchange」という概念が定義されています。exchangeは一種のルーターと見なせます。メッセージがexchangeにパブリッシュされると、exchangeは配信すべきメッセージを決定します。ここで、メッセージを直接キューに入れることは不可能になっている点が重要です。仮にメッセージをキューに直接パブリッシュしたとしても、臨時のexchangeを作成してキューに配信するようになっています。
RabbitMQでサポートされるexchangeには4種類あります。
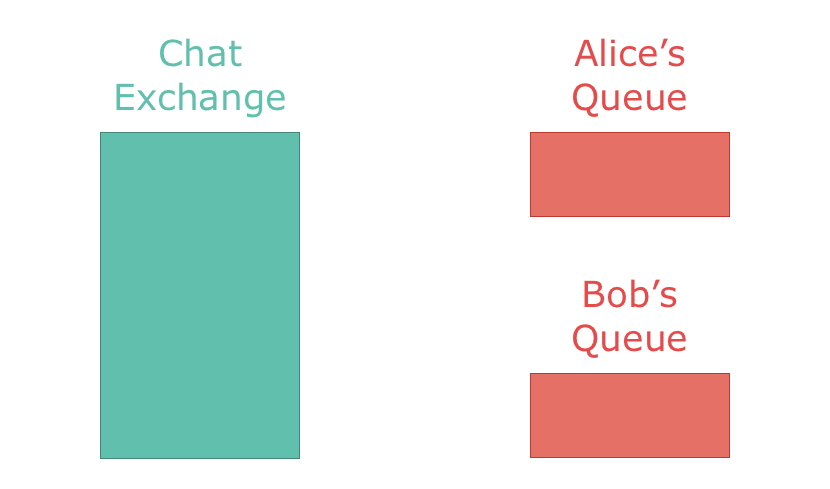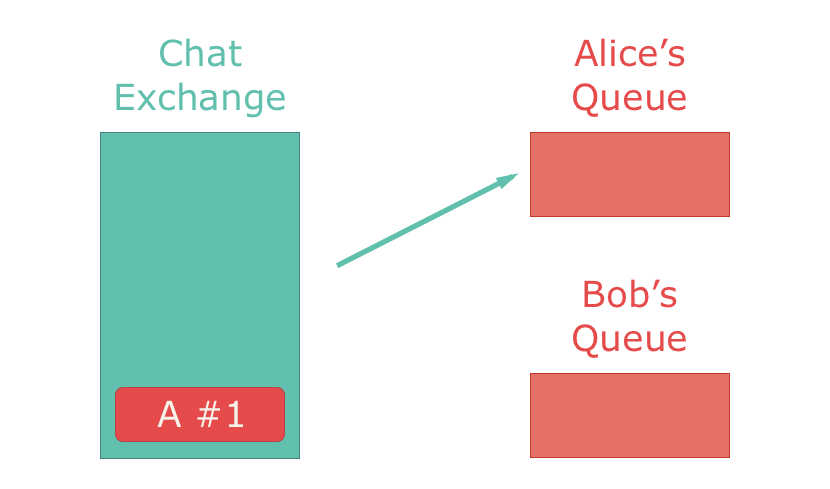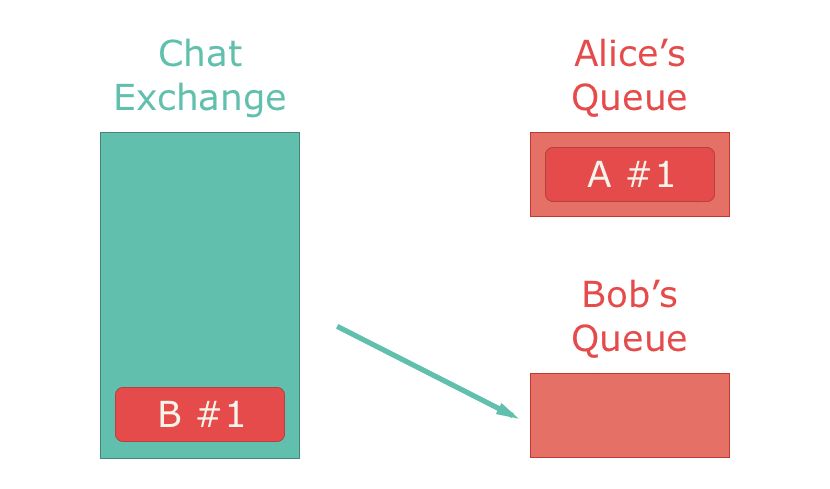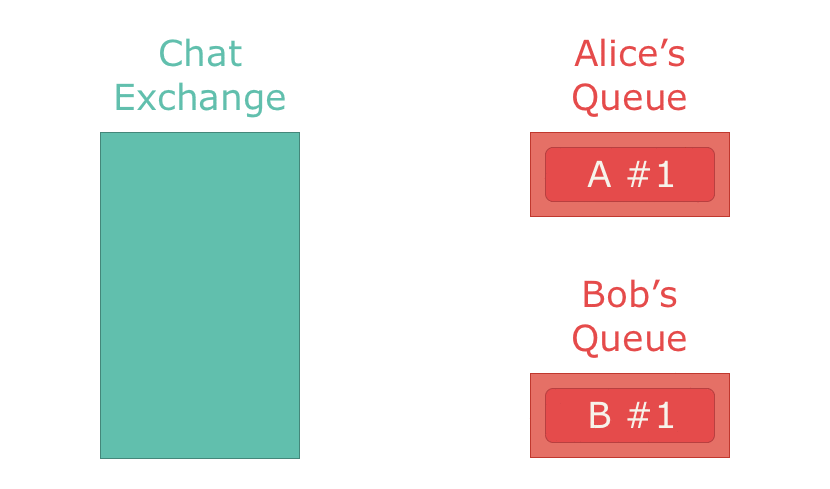
最もよく利用されているのはdirect exchangeで、すべてのメッセージを1つのキューに配信します。exchangeとキューは1対1対応します。direct exchangeをチャットアプリに応用した場合、メッセージはチャットルームから1人のユーザーに配信されます。

他にfan-out exchangeというものもあります。これはメッセージを自分に紐付けられたすべてのキューに配信するもので、1つのexchangeと複数のキューが1対多になっています。チャットアプリを例に取ると、fan-out exchangeは1件のメッセージを全ユーザーに送信するときに使われます。
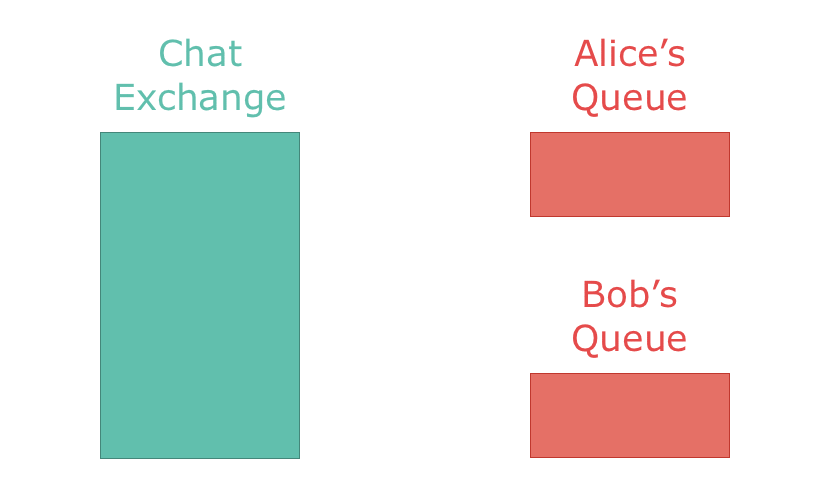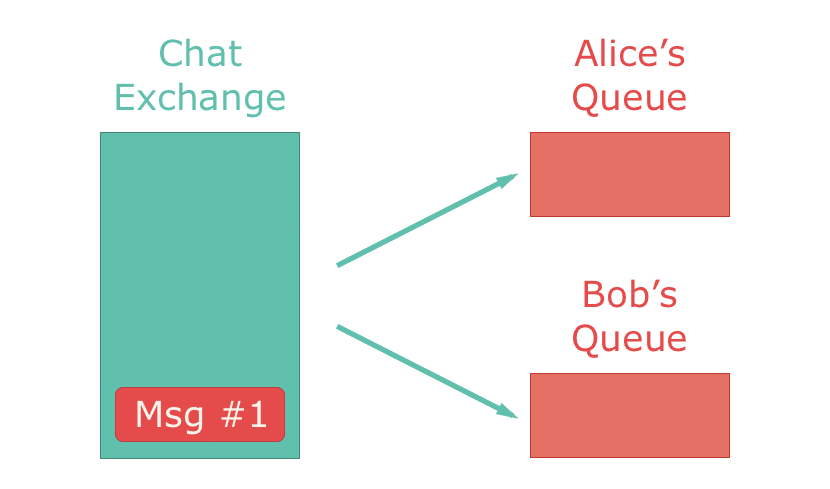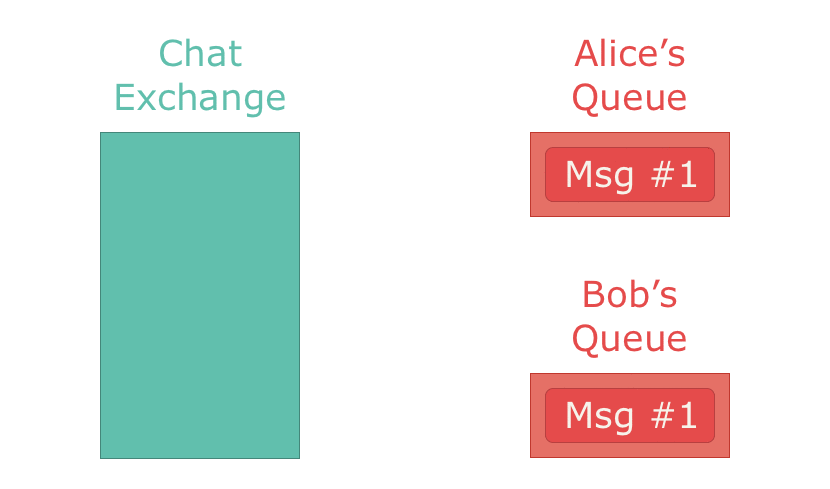
次はtopic exchangesです。これはメッセージのタグやトピックに紐付けられたキュー、およびキューに紐付けられたトピックを元にメッセージをそれらに配信します。チャットアプリを例に取ると、topic exchangeは対応するユーザーにダイレクトメッセージを送信するときに使われます。
最後はheader exchangesです。これはtopic exchangeをさらに推し進めたもので、トピックを参照するのではなく、ルーティングキーも呼び出して、メッセージのヘッダーを参照して配信すべきメッセージを決定します。RabbitMQのメッセージにはこれらに関連付けられた属性(ヘッダー)を追加でき、これによってメッセージの扱いを変えられます。たとえば”x-match”ヘッダーは、値がそれにマッチするexchangeを指定して、キューにルーティングされるようにします。”reply-to”ヘッダーは、メッセージの処理結果をどこにパブリッシュすべきかを指定します。
exchangeを利用することで、1回こっきりの配信、パフォーマンス向上、サービスの廃止処理(deprecation)が容易など、さまざまなメリットが得られます。exchangeによるメッセージ配信は、同等のロジックを扱うRubyに比べてかなり高速かつ高信頼性です。メンテするコードを持たないことには実用的な理由もあります。ロジックはRabbitMQが引き受けるので、設定だけで使えます(設定はコードで行います)。exchange〜exchange間やexchange〜キュー間の紐付けは任意のクライアントからその場で変更できるので、あるアプリが別のサービスの振る舞いを変えられるようになります。exchangeは個人的に、サービスを別のサービスに(一時的に)切り替える必要なしに、ダウンタイムを極小またはゼロにとどめてデプロイしたり、サービスを廃止処理(deprecation)するのに役立ちました。
- 前記事: RabbitMQはSidekiqと同等以上だと思う: 前編(翻訳)
- 次記事: RabbitMQはSidekiqと同等以上だと思う: 後編(翻訳)