
- #1: 基本となる8つの正規表現
- #2: 正規表現とは何か/ワイルドカードとの違い
- #3: 冒頭/末尾にマッチするメタ文字とセキュリティ、文字セットの否定と範囲(本記事)
![⚓]() 正規表現はじめの九歩:
正規表現はじめの九歩: \Aと\z

\A- 文字列の冒頭を表す(
\Aは大文字!) \z- 文字列の末尾を表す(
\zは小文字!)
\Aや\zは、対象となる文字列全体(改行も含む)の冒頭や末尾を表します。以下の2つの例は、どちらも改行を含む文字列の冒頭または末尾に接している言葉だけにマッチしています。
\Aや\zがマッチするのは文字列そのものではないことにご注意ください。また、パターンの途中に置く意味はありません。
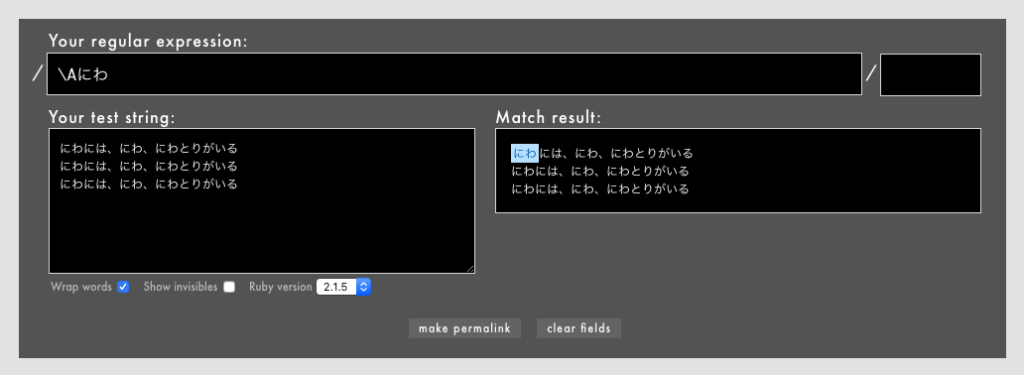
- 例:
/\Aにわというパターン(Rubular)
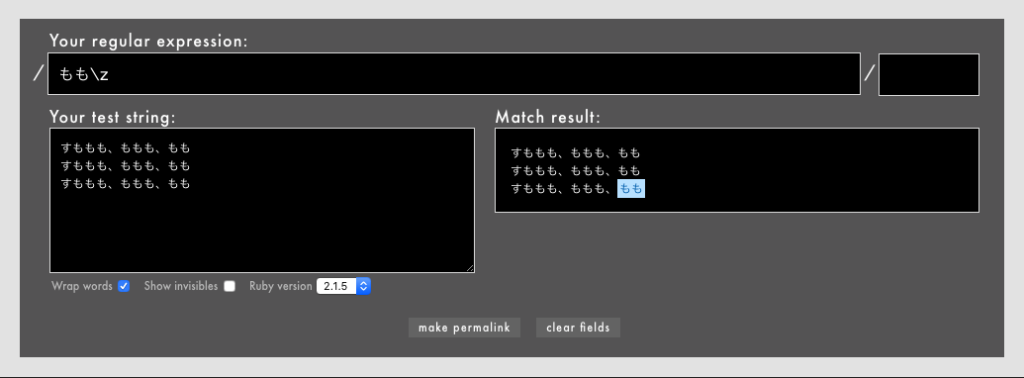
- 例:
/もも\z/というパターン(Rubular)
注:
\Aや\zのように、\で始まるメタ文字(文字列アンカー)のサポートはライブラリごとの違いが割とあります。たとえばPOSIX BREやPOSIX EREでは原則としてサポート外です(言い切れないのが歯がゆいところですが)。
本記事では、RubyやPythonやPerlやPHPといった比較的高機能な正規表現ライブラリを前提としています。
![⚓]()
\Aや\zと、|の合わせ技
第1回で学んだ|は、\Aや\zよりも優先順位が低いので、次のように|で区切ったパターンそれぞれに\Aや\zを書くこともできます。
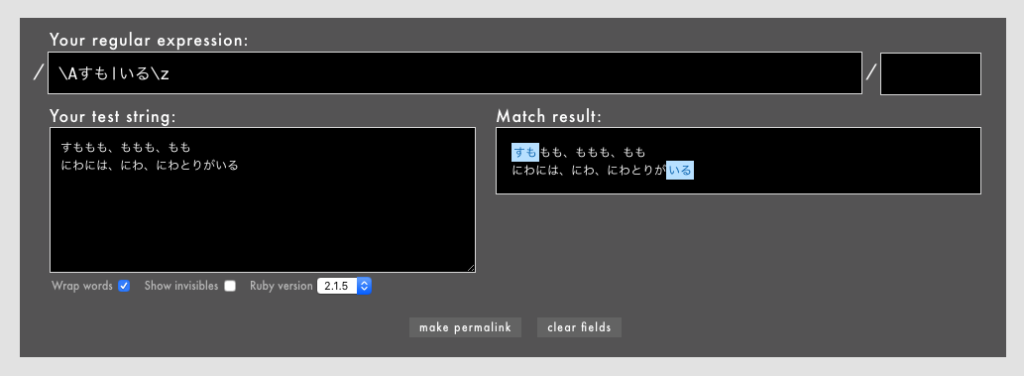
- 例:
/\Aすも|いる\z/というパターン(Rubular)
|でつないでいるので、片方だけのマッチでも両方のマッチでも、マッチとして扱われます。
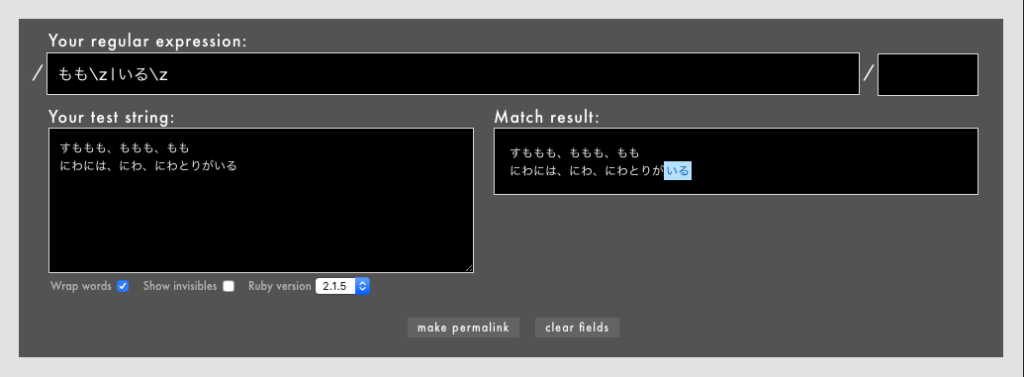
以下の例では、対象文字列の2行目を削除すれば1行目末尾の「もも」にマッチします。Rubularで試してみましょう。
- 例:
/もも\z|いる\z/というパターン(Rubular)
![⚓]()
![⚠]() 警告: 冒頭や末尾を
警告: 冒頭や末尾を^や$で表すときはセキュリティに注意
 警告: 冒頭や末尾を
警告: 冒頭や末尾を^- 行の冒頭を表す(原則避ける)
$- 行の末尾を表す(原則避ける)
一般の正規表現の資料では、冒頭や末尾を表すメタ文字として真っ先に^や$が記載されています。そしてネットに落ちている正規表現でも^や$が多用されています。
ただし少なくともRubyやPHP、PCRE(Perl)、またはPCREっぽい正規表現ライブラリでは、^や$というメタ文字をユーザー入力で使うと、多くの場合脆弱性の元になる場合があります。
^や$で脆弱性が発生するかどうかは、正規表現に与えるオプションにもよります。たとえばPHPではmを指定しなければ^や$の挙動は^や$と同じになります。
参考: PHP: 正規表現パターンに使用可能な修飾子 - Manual
本シリーズでは、正規表現の外から与えるオプションについては原則扱いません。

次の例をご覧ください。「すも」で始まり「もも」で終わる文字列だけを使おうとして以下の正規表現を書いたために、Set-Cookie: SESSIONID=ABCというコードを注入されています。つまり、マッチしてはいけないはずの文字列にマッチしてしまっています。この方法でSQL文を注入されれば、いわゆるSQLインジェクションという致命的な脆弱性につながります。
例: /^すも.+?もも$/というパターンで注入が発生(Rubular)
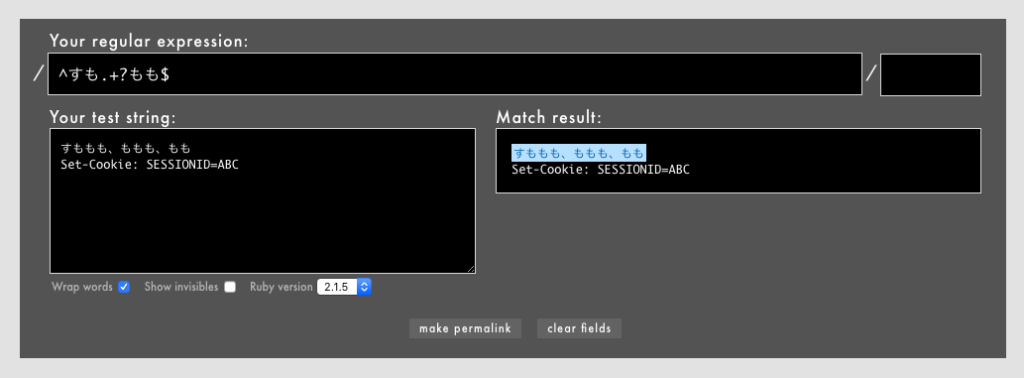
^や$を原則として避けるべき理由は、上記のライブラリでは「文字列の冒頭や末尾」ではなく「行の冒頭や末尾」にマッチするためです。
少なくとも、Webアプリの入力値のような「信頼できない文字列」のバリデーションでは^や$で冒頭や末尾を表すことは避けましょう。以下のRubyスタイルガイドにも同様の記載があります。
![⚓]()
^や$のまっとうな使用例
もちろん、以下の「改行を含めた正規表現検索」のように、^や$を使わないと表せない正規表現もあります。何が何でも使ってはいけないというものではありませんが、それでも十分慎重に扱うべきです。^や$をあえて本記事の「はじめのn歩」に含めなかったのはこれが理由です。
以下はいずれも「信頼できる文字列」を対象として仮定しています。
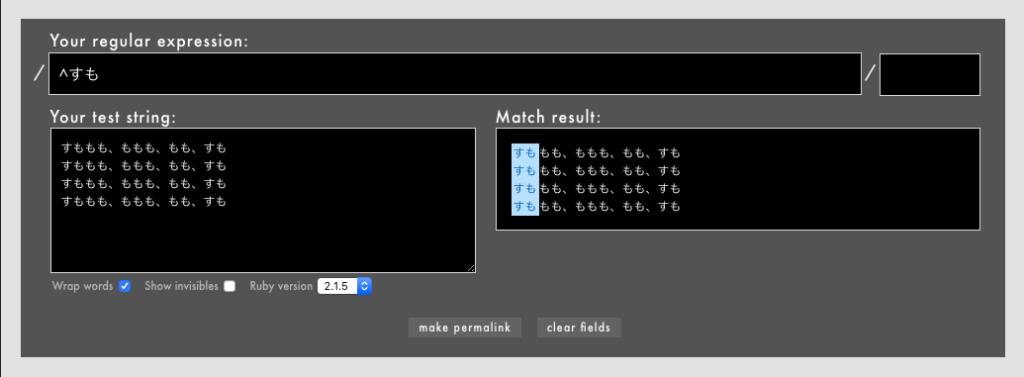
- 例:
/^すも/で複数行の文字列で行の冒頭文字とマッチさせる(Rubular)
- 例:
/すも\nもも$/というパターン(Rubular)
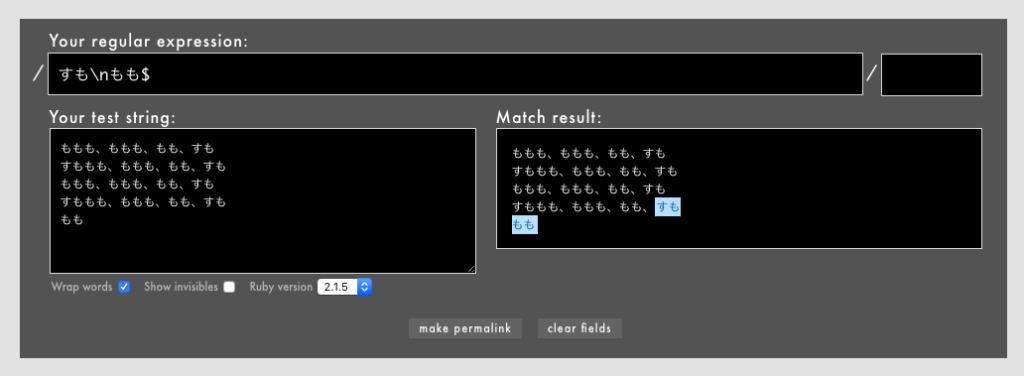
なお、上は/すも\n^もも$/のように^を追加しても同じようにマッチしますが、冗長です。
正規表現はじめの十歩: [^文字]による文字セットの否定表現
[^文字]- 指定された文字でない任意の1文字(否定)
はじめの六歩で学んだ文字セット[ ]の冒頭に^を置くと、文字セットの否定を表現できます。
これは先ほどの^とは異なり、使っても大丈夫な^です。
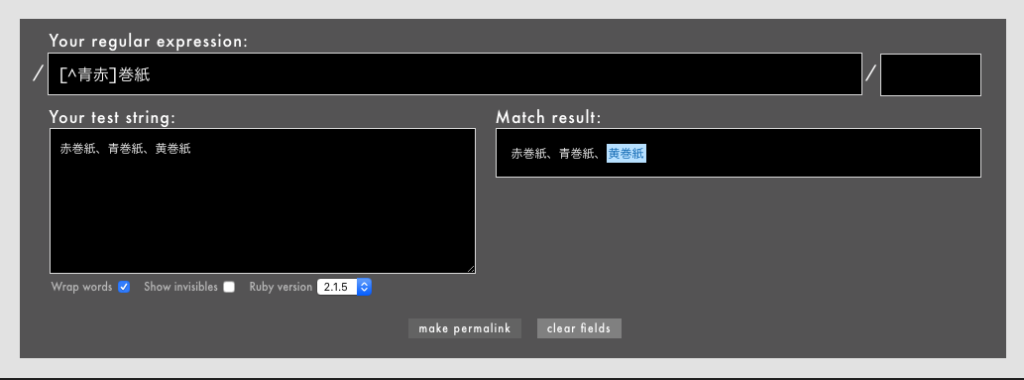
[^文字]も文字セットなので、文字セット全体は1文字として扱われる点にご注意ください。たとえば[^ABC]という文字セットは、「AでもBでもCでもない1文字」という意味です。
よく間違えられるのですが、「ABCではない文字列」ではありませんので、単語やフレーズの否定は1つの文字セットで表せません。
例: /[^青赤]巻紙/というパターン(Rubular)
なお、
$は[ ]の中では単なる文字でしかなく、機能はありません。詳しくは文字クラス [ ] 内でエスケープしなくてもよい記号をご覧ください。
![⚓]() 正規表現はじめの十一歩:
正規表現はじめの十一歩: [ - ]による文字範囲表現
[a-z]aからzまでのいずれかの1文字を表す[a-z0-9]aからzと0から9までのいずれかの1文字を表す
文字セット[ ]の中で2つの文字を-でつなぐと、文字セットの文字の範囲を簡潔に表せます。これも非常に有用な書式です。-は文字セットの中でのみ常に機能を持つメタ文字です。
たとえば、ASCII数字1文字を表す[0123456789]という文字セットは、[0-9]と表せます。
上の[a-z0-9]のように、文字セット[ ]の中で複数の範囲も記述できます。範囲はいくつでも追加できます。
なお、-そのものを文字セット[ ]の中で使いたい場合は、主に以下の2とおりの方法があります。
-を[ ]の中で最後に置く(苦し紛れ感)- 例:
[a-zA-Z0-9_?$%#@-]
- 例:
- バックスラッシュ
\でエスケープする- 例:
[\-]
- 例:
なお、-で表す文字単位は文字セット内で連続していなくても構いません。たとえば以下の2つ目は1つ目の記号をわざと文字範囲の隙間に移動したものですが、結果は同じですので、Rubularで開いて試してみてください。
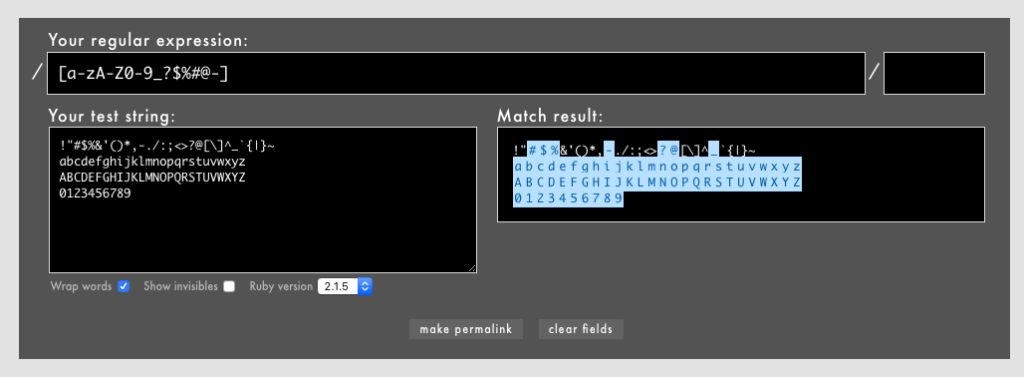
しかし2.のような混在した書き方は混乱を招くだけなので、スタイルとして範囲は文字セットの前半にまとめて置くようにしましょう。未来の自分のためにも。
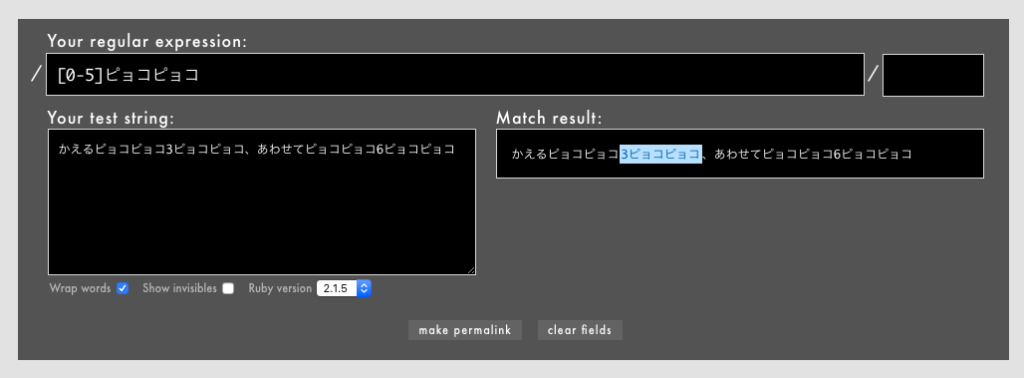
- 例:
/[0-5]ピョコピョコ/というパターン(Rubular)
![⚓]() 注意: 文字範囲
注意: 文字範囲[ - ]を雑に指定しないこと
たとえば横着して[a-zA-Z]という文字範囲を[A-z]などと書くと、[や_などといった記号にまでマッチしてしまいます。以下の文字コード表を見れば理由はおわかりかと思います(Unicodeの文字コード表ですが、この部分の並びはASCIIと同じです)。私は[A-z]という書き方自体使おうなどと思いつきませんでした。
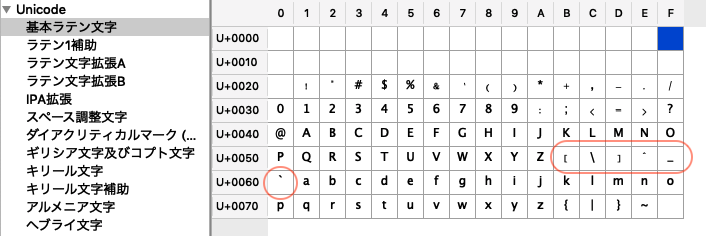
文字範囲を使う前には文字コード表などで余分な文字を巻き込んでいないかどうかチェックする癖を付けましょう。くれぐれも雰囲気で範囲を指定しないように。文字セット[ - ]を精密に記述しようとすると、しばしば文字をべたに列挙するしかないこともあります。
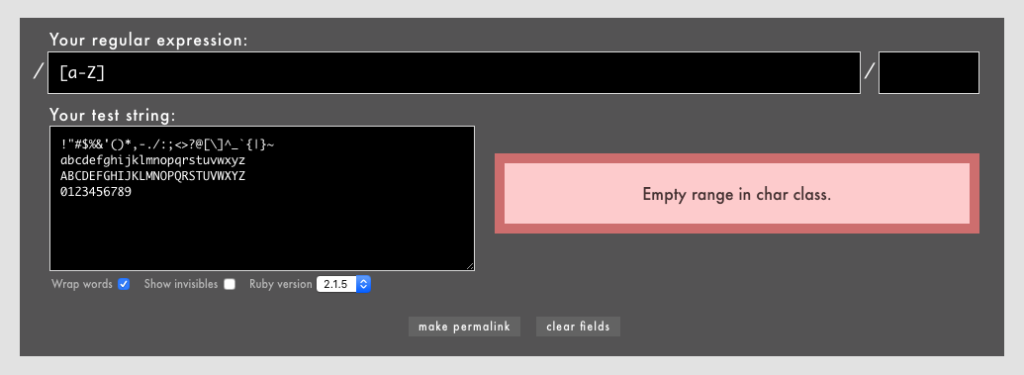
当然ですが、文字セット範囲[-]は文字コード表順にチェックされるので、[a-Z]のように逆順に書いても無効です((Rubular))。
詳しくは以下の参考記事でも説明されています。
![⚓]() 保存版: よく使われる文字範囲
保存版: よく使われる文字範囲
以下はよく使われる文字セット範囲のイディオムを私なりに吟味したものですが、コピペする前によくお読みください。すべて日本語のみを想定しています。
- 数字
[0-9]- 英字(大文字小文字)
[a-zA-Z]- 英数字
[a-zA-Z0-9]- 英数字と半角スペースとASCII記号
[a-zA-Z0-9 !"#$%&'()*,.\/:;<>?@\[\\\]\^_`{|}~-]
・-を最後に置いているのがポイント![⚠]() エスケープはRuby用になっているので他のライブラリでは適宜エスケープを調整すること
エスケープはRuby用になっているので他のライブラリでは適宜エスケープを調整すること- (まあ実用的な)全角ひらがな
[ぁ-ん]
・![⚠]()
ゑなどにはマッチするがゔやゞやゟといった特殊なひらがなにはマッチしない(UnicodeHiraganablock)- (まあ実用的な)全角カタカナ
[ァ-ヴー]
・![⚠]() 長音
長音ーも入れないと不完全
・![⚠]()
ヰなどはマッチするがヶやヸといった特殊なカタカナにはマッチしない(UnicodeKatakanablock)- (まあ実用的な)Unicode漢字
[一-龠]
・レアな中国語の漢字は漏れる
・![⚠]() よくネットに落ちている
よくネットに落ちている[亜-熙]はShift-JIS用の古い書き方- (まあ実用的な)Unicode漢数字
[〇一二三四五六七八九十百千万億兆京]
・べた書きのみ- (非実用)Unicode漢数字(大字含む)
[零〇壱一弐二参三肆四伍五陸六漆七捌八玖九拾十陌百阡千萬万億兆京]
・べた書きのみ
![⚓]() 正規表現は「フレーズの否定」が苦手
正規表現は「フレーズの否定」が苦手
このシリーズ記事の#3で初めて否定を取り上げたのは、否定表現がしばしば正規表現でつまづきの元になるためです。
正規表現を書いてると、時たま猛烈に欲しくなるのが「AAAやBBBやCCCのどれでもない文字列」というフレーズの否定表現です。
しかしそれを簡単に実現できる手段は正規表現にありません。理由は、フレーズの否定をまともに実装しようとすると効率が悪くなることが予想されるためです。
否定の文字セット[^]を組み合わせれば実現できるのではないかという気がしてきますが(実際、原理的には可能ですが)、多くの場合徒労に終わります。
仮に「ABCDという文字列を含まない正規表現」を無理やり既存の方法で書くとたとえばこうなります(引用元)↓。こういうフレーズの否定表現を自動生成するスクリプトがネットに落ちていたりします。
^([^A]+|A+(BC?A+)*([^BA]|B([^CA]|C([^DA]|$)|$)|$))*$

ご覧のとおり可読性が著しく落ち、後で自分が読んでもきっとわけがわからなくなります。フレーズの否定は正規表現で頑張るより、正規表現を使うコード側で工夫しましょう。
次回説明する「先読み」「後読み」を使えば擬似的にフレーズの否定を表現できることもありますが、個人的にはあまりおすすめしません。
![⚓]()
grepコマンドの-vは覚えておこう
たとえばLinuxコマンドのgrepであれば、grep -vオプションを使うことで「指定の正規表現にマッチしない行」だけを簡単に取り出せます。
cat text.txt | grep -v "ABCD"
正規表現そのもので頑張るより、この発想で取り組む方が話が早いと思います。
(おまけ)実はRuby 2.4.1〜にはフレーズ否定の正規表現がある!
詳しくは以下の記事をどうぞ。
- #1: 基本となる8つの正規表現
- #2: 正規表現とは何か/ワイルドカードとの違い
- #3: 冒頭/末尾にマッチするメタ文字とセキュリティ、文字セットの否定と範囲(本記事)