
こんにちは、hachi8833です。生まれてはじめてRailsにプルリク投げて一瞬でマージいただきました 。
。
つっつきボイス:「お、ついにRailsにプルリク 」「土曜に投げたんですが、数分もしたらkamipoさんがマージしててたまげました
」「土曜に投げたんですが、数分もしたらkamipoさんがマージしててたまげました 」「kamipoさんの常駐率スゴそう
」「kamipoさんの常駐率スゴそう 」「セキュリティガイドのmarkdownに
」「セキュリティガイドのmarkdownに>みたいな生のHTML要素や記号が書き込まれていて、普通なら誰もそういうのは気にしないんですけど、GitLocalizeというツールの原文パースがその箇所でぶっ壊れたので、やむなくプルリクしました」「気づいた人が投げるのが一番 」
」
ドキュメントのようなトリビアなプルリクのタイトル冒頭には[ci skip]を付けてCIに負担をかけないようにするのがマナーと知りました↓(訳したのは自分ですが )。
)。
参考: Ruby on Rails に貢献する方法 - Railsガイド
RailsのCI (継続的インテグレーション: Continuous Integration) サーバーの負荷を減らすために、ドキュメント関連のコミットメッセージには[ci skip]と記入してください。こうすることで、コミット時のビルドはスキップされます。[ci skip] は「ドキュメントのみの変更」以外では使用できません。コードの変更には絶対使用しないでください。
railsguides.jpより
GitLocalizeはGitHub上のmarkdownやhtmlドキュメントの多言語翻訳支援ツール(無料)で、なかなかスグレモノです。こちらについては近々記事にしたいと思います 。
。

- 各記事冒頭には
でパーマリンクを置いてあります: 社内やTwitterでの議論などにどうぞ
- 「つっつきボイス」はRailsウォッチ公開前ドラフトを(鍋のように)社内有志でつっついたときの会話の再構成です
- 毎月第一木曜日に「公開つっつき会」を開催しています: お気軽にご応募ください
 でパーマリンクを置いてあります: 社内やTwitterでの議論などにどうぞ
でパーマリンクを置いてあります: 社内やTwitterでの議論などにどうぞ
![⚓]() Rails: 先週の改修(Rails公式ニュースより)
Rails: 先週の改修(Rails公式ニュースより)
今回は公式の更新情報とコミットリストから見繕いました。
![⚓]() 水平シャーディングのサポートが追加
水平シャーディングのサポートが追加
アプリケーションからマルチプルシャーディングに接続してシャーディングを切り替えられるようになった。シャーディングのスワップは引き続き手動である点に注意(今回の変更には自動シャーディング切り替えのAPIは含まれていない)。
# 設定例
production:
primary:
database: my_database
primary_shard_one:
database: my_database_shard_one
# マルチプルシャーディングへの接続
class ApplicationRecord < ActiveRecord::Base
self.abstract_class = true
connects_to shards: {
default: { writing: :primary },
shard_one: { writing: :primary_shard_one }
}
# コントローラやモデルのコードでシャーディングをスワップする
ActiveRecord::Base.connected_to(shard: :shard_one) do
# shard_oneから読むようになる
end
水平シャーディングAPIではreplicaもサポートされる。詳しくはガイドを参照。
ついでにこのPRでは、ドキュメントのないメソッドをいくつかprivate名前空間に移動し、エラーメッセージやドキュメントにも手を加えた。
同PRより大意
つっつきボイス:「たぶんhorizontal付けなくても普通にシャーディングでよかった気がする 」
」
つっつき後、verticalなシャーディングもあるらしいという指摘がありました。
参考: How Sharding Works - Jeeyoung Kim - Medium
同記事より
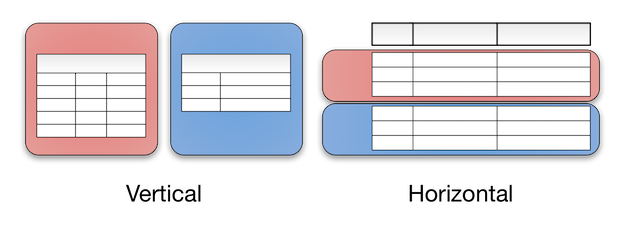

「と がいっぱい付いてました」「マルチDBになってからはシャーディングをRailsでやる方法がしばらくなかったからじゃないかな
がいっぱい付いてました」「マルチDBになってからはシャーディングをRailsでやる方法がしばらくなかったからじゃないかな 」「そういえばシャーディングは6.1から対応したいってどこかに書いてあったような」
」「そういえばシャーディングは6.1から対応したいってどこかに書いてあったような」
最初に申し上げておきたいのは、現時点のRailsではシャーディング(sharding)はまだサポートされていないという点です。私たちはRails 6.0でマルチプルデータベースをサポートするために膨大な作業をこなさなければなりませんでした。シャーディングのサポートを忘れていたわけではありませんが、そのために必要な追加作業は6.0では間に合いませんでした。さしあたってシャーディングが必要なのであれば、シャーディングをサポートするさまざまなgemのどれかを引き続き利用するのがおすすめと言えるかもしれません。
railsguides.jpより
「シャーディングを待ち構えてた人は結構いるらしいことがわかった」「そんな感じですね」「ま自分はシャーディングやりたくないのでシャーディングじゃない方法で実現したいですけどっ 」
」
参考: シャーディングとは、テーブルシャーディングという可能性【水平分割】 | SEO対策なら株式会社ペコプラ
![⚓]() スキーマキャッシュで拡張子.gzipをサポート
スキーマキャッシュで拡張子.gzipをサポート
スキーマキャッシュのシリアライズ戦略使うYAMLとMarshalの両方でgzipをサポートした。
特に巨大なスキーマキャッシュはKubernetesのデプロイで問題になる可能性がある(ConfigMapの上限は1 * 1024 * 1024)。データベースがこれ以上大きくなると上限を超えるかもしれない。
同PRより大意
# activerecord/lib/active_record/connection_adapters/schema_cache.rb#L11
def self.load_from(filename)
return unless File.file?(filename)
- file = File.read(filename)
- filename.end_with?(".dump") ? Marshal.load(file) : YAML.load(file)
+ read(filename) do |file|
+ filename.include?(".dump") ? Marshal.load(file) : YAML.load(file)
+ end
+ end
+
+ def self.read(filename, &block)
+ if File.extname(filename) == ".gz"
+ Zlib::GzipReader.open(filename) { |gz|
+ yield gz.read
+ }
+ else
+ yield File.read(filename)
+ end
end
+ private_class_method :read
...
def dump_to(filename)
clear!
connection.data_sources.each { |table| add(table) }
- File.atomic_write(filename) { |f|
- if filename.end_with?(".dump")
+ open(filename) { |f|
+ if filename.include?(".dump")
f.write(Marshal.dump(self))
else
f.write(YAML.dump(self))
end
}
end
...
+ def open(filename)
+ File.atomic_write(filename) do |file|
+ if File.extname(filename) == ".gz"
+ zipper = Zlib::GzipWriter.new file
+ yield zipper
+ zipper.flush
+ zipper.close
+ else
+ yield file
+ end
+ end
+ end
先週のatomic_writeが消えたのかと思って焦りましたが、openに移動してたんですね。
つっつきボイス:「先週スキーマキャッシュでMarshal使えるようにしてたので(ウォッチ20200302)、その続きっぽいです」「なるほど、gzipのCPUコストは安いですし」「拡張子もgzになってるからスキーマ自体をgzで保存できるようになったのか」「PRにもKubernetes環境でスキーマキャッシュがあふれないためとありますね: 実際、コンテナではこういうストレージの割り当てがほとんどないので、そこにでかいファイルを押し込まれると困るという要請があったんでしょうね」「なるほど〜」
![⚓]() Kubernetesとボリュームオプション
Kubernetesとボリュームオプション
「自分たちはその辺を考えたくない: docker runコマンドの-v/--volumeに相当することをdocker-composeでやれば回避できるんですけど、くばねてだとその辺ができないということなんでしょうね」「Shopifyではdocker buildに含めているとか何とか下の方に書いてありますね: 場合によるんでしょうけど」
「それそれ: 自分がKubernetesに踏み切れない理由のひとつが、ボリュームオプションをどうしても使いたいからなんですよ」「わかります」「ボリュームオプションが使えないとなるとインフラを相当慎重に作らないといけなくなる 」「GCPのKubernetes(GKE: Google Kubernetes Engine)ならボリュームマウントやれないかな〜?AWS ECS(Elastic Container Service)は既にできていて、AWSのEKS(Elastic Container Service for Kubernetes)もちょっと前にできるようになったと聞いたような覚えが」
」「GCPのKubernetes(GKE: Google Kubernetes Engine)ならボリュームマウントやれないかな〜?AWS ECS(Elastic Container Service)は既にできていて、AWSのEKS(Elastic Container Service for Kubernetes)もちょっと前にできるようになったと聞いたような覚えが」
「くばねてほとんど使ってないんでわかりませんけど、たぶんAWSで言うEFS(Elastic File System)に相当するサービスがGCPでも使えるならボリュームマウントできそう」「GCPのサービスを一気通貫で使っていればできそうな気がしますね」「AWSのECSもEFSならマウントできるはず: EFSは言ってみればマルチAZの同時接続に対応したNFSなので」「GCPにもEFS的なサービスあるのかどうかはまだ知らない」
参考: 最強のマネージドKubernetesはどれ? スペシャリストが比較検証したGKS/AKS/EKS – G3 Enterprise
参考: Amazon ECS で Amazon EFS を使用して Docker ボリュームを作成する
参考: Amazon EFS を Amazon EKS で使用する
参考: GCP と AWS サービス対応表・比較表(2019年2月版) | apps-gcp.com
参考: Network File System - Wikipedia
![⚓]() GCPとGoogleの底知れなさ
GCPとGoogleの底知れなさ
「GCP、そろそろ勉強しないといけないかな〜って気持ちになってきますね: 最近babaさんがSlackのAWSチャンネルでAWSのここが残念とかいろいろ書いてるのを見てると特に」「ああAWSのorganizationとかが残念な件」「あの書き込みはもしかすると社内インフラをGCPに移行するための布石を打ってたりして」「自分もそんな気がしてる」
「そういえば最近某所で某インフラエンジニアと呑みながらちょっと話したんですけど『やっぱGCPはつえぇ〜ですよ 』って言ってた」「へ〜強い人もそう言ってるとは」「babaさんとも話したことあるんですけど、AWSは言ってみれば下から積み上げていったボトムアップ的なサービス、一方Googleは研究レベルのものをいきなりぽいっと放り込んで二世代ぐらい先の世界を実現する異世界感がヤバい
』って言ってた」「へ〜強い人もそう言ってるとは」「babaさんとも話したことあるんですけど、AWSは言ってみれば下から積み上げていったボトムアップ的なサービス、一方Googleは研究レベルのものをいきなりぽいっと放り込んで二世代ぐらい先の世界を実現する異世界感がヤバい 」「スゴさのレベルが」「亜空間に連れてかれそう」
」「スゴさのレベルが」「亜空間に連れてかれそう」
「普通の発想ならプロダクトにまず投入しないような技術をぽいっとリリースするGoogleの底力はやっぱスゴくて、GCPじゃないとできないことが結構多いってその人も言ってましたね」「ふ〜む」「AWSは既存のパラダイムで構築されている分、それに縛られることも多かったりしますし」「GCPは3年前にお遊びで使ってみただけですけど相当世界変わってそう」
「KubernetesはGoogleがオープンソースにしたことで今日の隆盛がありますけど、当然ながらすべてをオープンソースにしたわけではない」「たしかに」「オープンになったのはせいぜいインターフェイス周りですし、もちろんそれで問題なく使えますけど、パフォーマンスやコストに直結する部分はそれよりも下のレイヤにあるわけで、Kubernetesのクラスタを動かすネットワークレイヤとか時刻同期みたいな部分にとんでもない謎技術が集中しているはず」「ほぇ〜」「だから自分はKubernetesを使うならGKEにすべきって思うんですよ」「わかります」「Kubernetesのようなものを自前でホスティングするなんてもってのほか」「そうでしょうね」
![⚓]() マルチDB向けのrakeタスクを追加
マルチDB向けのrakeタスクを追加
今回の変更で、シングルデータベースに加えて以下のようなコマンドも使えるようになった。
同PRより大意
rails db:schema:dump
rails db:schema:dump:primary
rails db:schema:dump:animals
rails db:schema:load
rails db:schema:load:primary
rails db:schema:load:animals
rails db:structure:dump
rails db:structure:dump:primary
rails db:structure:dump:animals
rails db:structure:load
rails db:structure:load:primary
rails db:structure:load:animals
rails db:test:prepare
rails db:test:prepare:primary
rails db:test:prepare:animals
つっつきボイス:「公式情報のPRリンクが間違ってたので探しちゃいました」
![⚓]()
each_with_objectをindex_byやindex_withに置き換えた
つっつきボイス:「このプルリクちょっと面白かったです」「each_with_objectはRubyのメソッドで、index_なんちゃらはRailsのメソッドでした」「ほほぅ」「後者の方が短く書けて速いみたいです」「index_withって知らなかったけど、index_byはたま〜に使ってた」
参考: Enumerable#each_with_object (Ruby 2.7.0 リファレンスマニュアル)
参考: index_by — Enumerable
参考: index_with — Enumerable
# actionview/lib/action_view/renderer/partial_renderer/collection_caching.rb#L92
- def fetch_or_cache_partial(cached_partials, template, order_by:)
- order_by.each_with_object({}) do |cache_key, hash|
- hash[cache_key] =
- if content = cached_partials[cache_key]
- build_rendered_template(content, template)
- else
- yield.tap do |rendered_partial|
- collection_cache.write(cache_key, rendered_partial.body)
- end
- end
+ order_by.index_with do |cache_key|
+ if content = cached_partials[cache_key]
+ build_rendered_template(content, template)
+ else
+ yield.tap do |rendered_partial|
+ collection_cache.write(cache_key, rendered_partial.body)
+ end
end
+ end
end
参考: Enumerable#index_by() が標準で欲しい - kなんとかの日記 — 2008年の記事です
「index_byがRubyにも欲しいというむか〜しの記事↑を見つけました」「たしかにRubyに標準で入ってもおかしくなさそう」「どゆこと?」「index_byは以下で言うとUser.find(:all)したものをindex_byすると、user.idがキーになって、それに該当するユーザーのオブジェクトがその先にいるという」「なるほど、ブロックの値をキーにしたハッシュを取れるのか!まさしくindex_byという名前にふさわしい 」「たまにこういうのを使いたくなりますね」
」「たまにこういうのを使いたくなりますね」
# kwatch.hatenadiary.orgより
module Enumerable
def index_by() # 名前は to_hash のほうが好み
hash = {}
each do |item|
key = yield(item)
hash[key] = item
end
return hash
end
end
## example: キーが user id, 値が User オブジェクトであるような Hash を作る
hash = User.find(:all).index_by {|user| user.id }
「まあうかつにallで取ると死にそうだけど」「」「find(:all)という今は使わないむか〜し昔の書き方をしていた頃からindex_byがあったのがよくわかった」「2008年!」
「そしてindex_withはRails 6から入ったのか(ウォッチ20180608)」「むむ、index_withはブロックの中で評価した式がハッシュの値になって、評価する前のキーがハッシュのキーになるってことか!」「そういうことか〜!」「ちょっとややこしい」
# activerecord/lib/active_record/associations/preloader.rb#L175
def records_by_owner
- @records_by_owner ||= owners.each_with_object({}) do |owner, result|
- result[owner] = Array(owner.association(reflection.name).target)
+ @records_by_owner ||= owners.index_with do |owner|
+ Array(owner.association(reflection.name).target)
end
end
「つまりたとえば配列Aと配列Bがあったとして、index_withでブロックの中でupcaseかけたとすると、元のlowercaseの方がハッシュのキーになって、upcaseかけた結果がハッシュの値になるという感じ」「凄まじいメソッド」「こういうのを使いたい瞬間があるのか〜」
「ざっくりまとめるとindex_withはハッシュの値に影響して、index_byはハッシュのキーに影響するのが違いということかな」「逆転の関係 」「オプション引数をこねこねしたくなると欲しいヤツ」「知ってたら使いたくなるメソッドですね」「人の書いたコードで見ると一瞬考えちゃいそうだけど」「書いた人以外はすぐわからないところはRubyの
」「オプション引数をこねこねしたくなると欲しいヤツ」「知ってたら使いたくなるメソッドですね」「人の書いたコードで見ると一瞬考えちゃいそうだけど」「書いた人以外はすぐわからないところはRubyのtapと似てるかも」
参考: Object#tap (Ruby 2.7.0 リファレンスマニュアル)
「このプルリクを投げた人はRails用のcopを書いたついでに修正をかけたそうで、rubocop-railsにもcopが反映されました↓」「これはとってもいい流れ!」
![⚓]() ガイドの追加修正
ガイドの追加修正
つっつきボイス:「最後はトリビアでガイドの修正: 1つめはパラレルトランザクションのテスト方法」
パラレルトランザクションをテストする
Railsではどのテストケースも自動的に1つのデータベーストランザクションでラップされ、テスト完了時にロールバックされます。これによってテストの独立性を担保でき、データベースの変更が単独のテストに閉じ込められます。
スレッド内でパラレルトランザクションを実行するコードをテストしたい場合、トランザクションがテストトランザクションの配下でネストしているため、互いにブロックしてしまう可能性があります。
以下のようにテストケースのクラスでself.use_transactional_tests = falseを書くことでトランザクションを無効にできます。
class WorkerTest < ActiveSupport::TestCase
self.use_transactional_tests = false
test "parallel transactions" do
# start some threads that create transactions
end
end
メモ: トランザクションを無効にしたテストによるデータベースの変更は完了時に自動でロールバックされなくなるため、作成したデータテストをすべてクリーンアップしなければなりません。
testing.mdより大意
「もうひとつはActive StorageガイドのサンプルコードにXSSが発見されたので修正されました」「おっと」「要らん変数(${file.name})が埋まってた」
// direct_uploads.js
addEventListener("direct-upload:initialize", event => {
const { target, detail } = event
const { id, file } = detail
target.insertAdjacentHTML("beforebegin", `
<div id="direct-upload-${id}" class="direct-upload direct-upload--pending">
<div id="direct-upload-progress-${id}" class="direct-upload__progress" style="width: 0%"></div>
- <span class="direct-upload__filename">${file.name}</span>
+ <span class="direct-upload__filename"></span>
</div>
`)
target.previousElementSibling.querySelector(`.direct-upload__filename`).textContent = file.name
})
// (略)
参考: クロスサイトスクリプティング - Wikipedia — XSS
![⚓]() Rails
Rails
![⚓]() fakeredis: redisサーバーを立てずに開発テスト(Ruby Weeklyより)
fakeredis: redisサーバーを立てずに開発テスト(Ruby Weeklyより)
- リポジトリ: guilleiguaran/fakeredis: In-memory driver for redis-rb, useful for development and test environments
# 同リポジトリより
require "fakeredis"
redis = Redis.new
>> redis.set "foo", "bar"
=> "OK"
>> redis.get "foo"
=> "bar"
つっつきボイス:「これうれしい人いるかなと思って」「なるほど、redisのfaker: CIでぺろっとredisを動かしたいときに役に立つのかな?」「どうだろう〜?今どきはredis立てちゃうんでは?」「そう思う」「redis立てるのが面倒な人向けかなと」「そのパターンはありそうですが」
「redisが欲しいけどredisを立てられないときとか?」「BPSのWebチームで内製したSandStarというGitLab CIサーバー↓だとdocker-composeでredis立てられますけど(実際にはredis動かしてませんが)、そういうのがない環境だとredis立ち上がらないので、シングルプロセスでredisのfalerが動かせるのはそれなりに価値があるかもしれませんね」
![⚓]() Webpackerに乗り換えるべき理由25
Webpackerに乗り換えるべき理由25
つっつきボイス:「25も」「さよならSprocketsという文字が見えた」「Sprocketsからの乗り換えも含んでるみたい」
「実際Railsプロジェクトの中でJavaScriptのコードも管理するんだったらWebpackerなのかな〜っていう気はしますけど」「今のRailsではJSの管理が公式にWebpackerになりましたね: 画像やCSSの公式な管理はまだですけど」「でも自分はここ最近のRailsプロジェクトではもうSprockets入れてませんし 」「Sprocketsって今も入っちゃうんでしたっけ?」「
」「Sprocketsって今も入っちゃうんでしたっけ?」「rails newで--skip-sprocketsって叩かないと入ってきます」「ちなみにSprocketsを殺しても、scaffoldするとapp/assets/ディレクトリ作られちゃいました」
記事ななめ読み:
- 乗り換えない理由があるとすれば
- JSを大して使ってない
- 時間ない
- 心の準備がまだ
- 1. WebpackerこそRailsの未来
- 2. Sprocketsは死んだ、Sprocketsよ永遠なれ
- 3. JSをうまく書く方法が変わる
- 4. ESモジュールのパワーを享受できる
- 5.
$JAVASCRIPT_FRAMEWORKが不要になる - 6. 別のファイル構成を利用できる
- 7. 依存関係の管理がしやすくなる
- 8. jQueryプラグインとおさらばできる(その気があれば)
- 9. ES2015以降の構文をES5+Babelにコンパイルできる
- 10. エクスペリメンタル機能もその気になれば使える
- 11. 特定のブラウザバージョンを対象にできる
- 12. 新しいブラウザAPIのポリフィルが使える
- 13. TypeScriptが使える
![❤]()
- 14. 新しい強力なツールの封印が解かれる
- 15. ソースコードをプログラム的に変更できる
- 16.
require_tree的なこともできる - 17. コードの自動静的分割
- 18. コードの自動動的分割
- 19. 最新のCSSフレームワークが使える
- 20. アセットコンパイルがRailsのdevelopmentサーバーの外に出る
- 21. development環境でページをリロードせずにコードを更新できる
- 22. source mapオプションが使える
- 23. パフォーマンスバジェットを実践できる
- 24. バンドルの中身をチェックできる
- 25. tree-shaking(不要なコードをビルドから削除する機能)が使える
参考: Google Developers Japan: パフォーマンスバジェットのご紹介 - ウェブパフォーマンスのための予算管理
「お、そろそろゲームにログインする時間なのでおいとまします」「」「お疲れさまでした〜 」
」
今回のウォッチつっつき会は、たまたまですが参加者が自分もふくめて全員リモートワーク中だったのでZoomで社内開催しました 。Zoomありがたいです。なお社内でのつっつき会は途中入場途中退出自由でROM専もOKです。
。Zoomありがたいです。なお社内でのつっつき会は途中入場途中退出自由でROM専もOKです。
![⚓]() Let’s Encryptの証明書をRubyで自動更新(RubyFlowより)
Let’s Encryptの証明書をRubyで自動更新(RubyFlowより)
# 同記事より
require 'fileutils'
require 'acme-client'
require 'openssl'
apps =
{ 'drgcms' => {
dir: '/path_to/drgcms', domains: %w[www.drgcms.org tulips.drgcms.org] }
}
client_key = OpenSSL::PKey::RSA.new( File.read('lets-encrypt.key') )
client = Acme::Client.new(private_key: client_key, directory: 'https://acme-v02.api.letsencrypt.org/directory')
apps.each do| app, domains |
p '',"Renewing APP: #{app}"
order = client.new_order(identifiers: domains[:domains])
order.authorizations.each do |authorization|
p ['validating', authorization.domain]
challenge = authorization.http
# write challange data to challenge.filename
FileUtils.mkdir_p( File.join( domains[:dir], 'public', File.dirname( challenge.filename ) ) )
File.write( File.join( domains[:dir], 'public', challenge.filename), challenge.file_content )
# validate single domain
challenge.request_validation
while challenge.status == 'pending'
p ['challenge.status', challenge.status]
sleep(2)
challenge.reload
end
p challenge.status # => 'valid'
end
# get certificate
private_key = OpenSSL::PKey::RSA.new(4096)
csr = Acme::Client::CertificateRequest.new(private_key: private_key, names: domains[:domains])
order.finalize(csr: csr)
while order.status == 'processing'
sleep(1)
challenge.reload
end
# save certificate and private key
if (certificate = order.certificate)
File.write("#{app}-pkey.pem", private_key.to_pem )
File.write("#{app}-cert.pem", certificate)
else
raise "Error retrieving certificate for application #{app}. Certificate was empty."
end
end
つっつきボイス:「ACMEv1とかv2って初めて見ました」「これはLet’s Encryptの更新プロトコルです」「おぉ、それ用のgemもあるみたいですね」「自分はLet’s Encryptのコマンドで十分ですけど、Rubyでやりたい人もいるんでしょう」
- リポジトリ: unixcharles/acme-client: A Ruby client for the letsencrypt’s ACME protocol.
参考: ACME クライアント実装 - Let’s Encrypt - フリーな SSL/TLS 証明書
![⚓]()
CarrierWave::Uploader::Baseをうっかり継承しないようにする方法(Ruby Weeklyより)
つっつきボイス:「Uploader::Baseを継承するとすぐに気づかないバグになるみたいですね」「CarrierWaveみたいなでかいライブラリにこういうことするのってあんまりない気がしますけど」
# 同記事より
module CarrierWave
module Uploader
module YourAppName
class MustInheritFromApplicationUploaderError < StandardError; end
def initialize(model = nil, mounted_as = nil)
# これがraiseされると、適用されたアップローダがApplicationUploaderを
# 継承する必要があることを思い出させてくれる
# このオブジェクトモデルのファイルではアップローダーを指定していないことがあった
unless is_a?(ApplicationUploader)
raise MustInheritFromApplicationUploaderError, "Did you forget to specify an uploader?"
end
super
end
end
end
end
「お、上のコードを見るとたしかに直接の継承を明示的に禁止するコードになってる: CarrierWave本体じゃなくてApplicationUploaderを継承せいということね 」「MustInheritFromApplicationUploaderErrorってスゴい名前」「今のRailsも
」「MustInheritFromApplicationUploaderErrorってスゴい名前」「今のRailsもActiveRecord::BaseではなくApplicationRecordを継承するようになってますし」
前編は以上です。
おたより発掘
https://t.co/o5ZyElt5PD 見ての感想ですが、クックパッドマートは内部でSimpacker使ってます。 (今のところ特に問題なし)https://t.co/wghVSYDEF5
— ryo katsuma / cookpad mart (@ryo_katsuma) March 9, 2020
バックナンバー(2020年度第1四半期)
週刊Railsウォッチ(20200303後編)Ruby 2.7で引数のruby2_keywordsフラグを確認する、fake_apiでAPIプロトタイプ、groupdateで日付をグルーピングほか
- 20200302前編 RubyKaigi 2020は9月に延期、Railsのセキュリティパッチバージョニングが変更、dry-monadsほか
- 20200226後編 dry-rbを使うべき理由、最近のRubyオンライン教材、AWSから乗り換えた話ほか
- 20200212後編 Rubyistが解説するUnicodeとUTF-8、Sorbetが速い理由、CSSの歴史、2019年の脆弱性まとめほか
- 20200210前編 Railsのベンチマークジェネレータ、長いバックグラウンドジョブと戦う、Timestamp切り詰めの謎、Open APIツールほか
- 20200204後編 Ruby3.0の他のbreaking change、Rubyのシリアライザ、GitHubのcode ownersほか
- 20200203前編 Railsの各種高速化コミット、OpenAPIの使い所、パンくずリストgem loaf、Railsビュー最適化ほか
- 20200128後編 もう一つのgemマネージャgel、”Did you mean”の仕組みを追う、DXOpalでブラウザゲームほか
- 20200127前編 Railsでキーワード引数warning退治始まる、ライブラリとフレームワークの違い、ShopifyのRails高速化記事ほか
- 20200121後編 RubyKaigi 2020受付開始、RubyGemsとBundlerの今後、ファイル同期ツールMutagenほか
- 20200120前編 福岡でも公開つっつき会、Railsのconnection_specification_nameでprimaryという名前が非推奨に、structure.sqlとschema.rbほか
- 20200115後編 Ruby 2.7関連情報、Bootstrap 5は今年前半リリースか、PostgreSQLでやってはいけないリストほか
- 20200114前編 config_forのbreaking change、Active Storage variantをDBでトラッキング、SprocketsとWebpackの違いほか
今週の主なニュースソース
ソースの表記されていない項目は独自ルート(TwitterやはてブやRSSやruby-jp Slackなど)です。

