こんにちは、hachi8833です。長くなりましたが、「Rubyスタイルガイドを読む」シリーズの文法編もやっと今回で終わりです。次回からの「命名編」もどうぞご期待ください。
文法(8) 配列や論理値など
文字列を引数に取るArray#*はわかりにくいので避け、Array#joinを使うこと
Favor the use of
Array#joinover the fairly crypticArray#*with a string argument.
# 不可
%w(one two three) * ', '
# => 'one, two, three'
# 良好
%w(one two three).join(', ')
# => 'one, two, three'
Rubyリファレンスマニュアル: Array#*では以下のAとBの2種類が記載されています。Aが本来望ましい用法と思われるので、乗算などとまぎらわしいBの用法を避けてArray#joinで記述するということですね。
# A: 繰り返しの *
p [1, 2, 3] * 3 #=> [1, 2, 3, 1, 2, 3, 1, 2, 3]
# B: 結合の *(避ける)
p [1, 2, 3] * "," # => "1,2,3"
「変数が配列でない場合は配列に変換する」処理はArray()で書くこと
Use
Array()instead of explicitArraycheck or[*var], when dealing with a variable you want to treat as an Array, but you’re not certain it’s an array.
# 不可1 (変数が配列かどうかをチェックするためだけの1行目が冗長)
paths = [paths] unless paths.is_a? Array
paths.each { |path| do_something(path) }
# 不可2 (Arrayインスタンスが毎回作成されてしまう)
[*paths].each { |path| do_something(path) }
# 良好 (かつ読みやすい)
Array(paths).each { |path| do_something(path) }
配列になっている変数を#eachで回して処理するのはRubyでは定番中の定番ですが、変数を素直に#eachすると、変数が配列でない場合にエラーになってしまいます。
paths = "a"
paths.each { |path| puts path } # pathsが配列になってないとエラーになる

かといって、最初の「不可1」コード例のように変数が配列かどうかをわざわざチェックするのは残念です。
「不可2」のコード例では[*paths].eachのような記法を使って条件分岐をなくしています。
paths = "a"
[*paths].each { |path| puts path } # 動くが、Arrayのインスタンスが常に生成されてしまう
[*paths]は変数が配列であってもなくても動作しますし、一見よさそうですが、変数が配列であるかどうかにかかわらず常にArrayインスタンスが生成されてしまいます。morimorihogeさんがすかさず動作を確認してくれました。
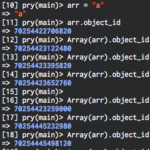
arr = ['a', 'b']
arr.object_id
[*arr].object_id # 毎回異なる
[*arr].object_id # 毎回異なる
...
確かにobject_idが毎回異なっており、[*arr].object_idにアクセスするたびにインスタンスが生成されていることがわかります。arr.object_idと[*arr].object_idも異なっています。これは効率が悪そうです。

なお[*paths]のアスタリスクは、実引数側で「配列を展開して渡す」ためのものです。
メソッドに引数を渡す場合に、配列を展開してメソッドの引数にすることもできます。メソッドの呼び出しの際に、「
*配列」の形式で引数を指定すると、配列そのものではなく、配列の要素が先頭から順にメソッドの引数として渡されます。ただし、配列の要素の数とメソッドの引数の数は一致していなければいけません。
『たのしいRuby』第5版第1刷、p115より

代わりに推奨されているのが「良好」コード例で示されているArray(paths).eachのような書き方です。

Array(paths)だとインスタンスが生成されないかどうか試してみましょう。
arr = ['a', 'b']
arr.object_id
Array(arr).object_id # arr.object_idと同じ
Array(arr).object_id # arr.object_idと同じ
...
確かにobject_idは毎回同じになっています。arr.object_idとArray(arr).object_idも同じなので、インスタンスは生成されていません。

babaさんの指摘でわかりましたが、Array()はKernel#Arrayという、Kernelモジュールのメソッド(Ruby全体で使える関数的なメソッド)です。
大文字で始まる珍しいメソッド名なので、Array#initializeでインスタンスを生成しているように一瞬見えてしまいますが、KernelモジュールはObjectクラスにインクルードされるのでnewせずにRubyのどこででも使え、最終的にrb_Arrayという関数を呼んでいます。
DevDocなどのKernel#arrayのリンク先で「show source」をクリックするとrb_arrayを呼んでいることを確認できます。
なおrb_arrayは、objがArrayでない場合は#to_aを使ってArrayに変換するので、Kernel#Arrayに渡す変数が配列ではない場合は以下のように毎回インスタンスが生成されます。変数の要素が1つなら#eachは1回で終わるので問題にはならないと思います。
arr = "a" # 配列でない変数
arr.object_id
Array(arr).object_id # 毎回異なる
Array(arr).object_id # 毎回異なる
...

範囲演算子やComparable#between?を使って比較をできるだけ簡潔に書く
Use ranges or
Comparable#between?instead of complex comparison logic when possible.
# 不可
do_something if x >= 1000 && x <= 2000
# 良好
do_something if (1000..2000).include?(x)
# 良好
do_something if x.between?(1000, 2000)
比較条件で==の直接使用を避け、even?やzero?といった述語メソッドを使うことが望ましい
Favor the use of predicate methods to explicit comparisons with
==. Numeric comparisons are OK.
ただし数値の比較に==を使うのは許容されるそうです。
# 不可
if x % 2 == 0
end
if x % 2 == 1
end
if x == nil
end
# 良好
if x.even?
end
if x.odd?
end
if x.nil?
end
if x.zero?
end
if x == 0 # これはOK
end
多くのプログラミング言語では「条件部分になるべくリテラルを書かないようにする」ことが推奨されていますが、Rubyではさらに進んで述語メソッド(論理値–trueかfalseのいずれかだけ–を返すメソッド)の利用が推奨されます。
nilでないことのチェック(nilチェック)は、論理値を扱っていることが確実でない限り行わないこと
Don’t do explicit non-
nilchecks unless you’re dealing with boolean values.
# 不可
do_something if !something.nil?
do_something if something != nil
# 良好
do_something if something
# 良好 - 論理値に変換している
def value_set?
!@some_boolean.nil?
end
BEGINブロックは避ける
Avoid the use of
BEGINblocks.
ENDブロックは避け、Kernel#at_exitにする
Do not use
ENDblocks. UseKernel#at_exitinstead.
# 不可
END { puts 'Goodbye!' }
# 良好
at_exit { puts 'Goodbye!' }
フリップフロップは避ける
Avoid the use of flip-flops.
何もサンプルがありませんが、ここで言うフリップフロップは「呼ぶたびにオン/オフやtrue/falseなどの状態を反転するメソッド」を指すと考えられます。
フリップフロップを避けるということは、たとえば明示的に「オンにするメソッド」「オフにするメソッド」で書くということですね。
制御で条件をネストすることは避ける
Avoid use of nested conditionals for flow of control.
Prefer a guard clause when you can assert invalid data. A guard clause is a conditional statement at the top of a function that bails out as soon as it can.
以下にあるように、guard clauseの利用が推奨されています。用が済んだらすぐ脱出することで、条件の無駄なネストを避けられます。
# 不可
def compute_thing(thing)
if thing[:foo]
update_with_bar(thing[:foo])
if thing[:foo][:bar]
partial_compute(thing)
else
re_compute(thing)
end
end
end
# 良好
def compute_thing(thing)
return unless thing[:foo] #<= guard clauseその1
update_with_bar(thing[:foo])
return re_compute(thing) unless thing[:foo][:bar] #<= guard clauseその2
partial_compute(thing)
end
ループではnextの利用が望ましい
Prefer
nextin loops instead of conditional blocks.
if〜endやunless〜endといった条件ブロックをこしらえなくても、nextと後置条件の合せ技にすることですっきりと1行で書けます。
# 不可
[0, 1, 2, 3].each do |item|
if item > 1
puts item
end
end
# 良好
[0, 1, 2, 3].each do |item|
next unless item > 1 # 簡潔
puts item
end
以下の別名メソッドについてざっくり優先順位を定める
| 優先順位: 低 | 優先順位: 高い |
|---|---|
#collect |
#map |
#detect |
#find |
#find_all |
select |
#inject |
#reduce |
#length |
#size |
同じ行のメソッドは互いに別名になっています。
Prefer
mapovercollect,findoverdetect,selectoverfind_all,reduceoverinjectandsizeoverlength. This is not a hard requirement; if the use of the alias enhances readability, it’s ok to use it.
このスタイルはそれほど厳しくはないので、別名メソッドを統一する目安ということだと思います。injectはRubyでは相当有名なメソッドなので、突然reduceに変えるとかえっていぶかしがられるかもしれませんね。
The rhyming methods are inherited from Smalltalk and are not common in other programming languages. The reason the use of
selectis encouraged overfind_allis that it goes together nicely withrejectand its name is pretty self-explanatory.
#collectや#detectといった「韻を踏んだ」メソッド名がSmalltalk由来で他の言語で馴染みが薄いからという程度の理由付けです。言われてみれば表の左は〜ectで終わる名前が多いですね。
#find_allと#selectだけ#selectが優先されているのは、#selectの方が#rejectと(英語的に)相性もよく意味もわかりやすいからだそうです。
#sizeの意味で#countを使わないこと
Don’t use
countas a substitute forsize. ForEnumerableobjects other thanArrayit will iterate the entire collection in order to determine its size.
Arrayオブジェクト以外のEnumerableオブジェクトではサイズを確定するためにコレクション全体を列挙します。
# 不可
some_hash.count
# 良好
some_hash.size
#mapと#flattenではなく#flat_mapを使うこと
ただしflat_mapだと階層が3つ以上の場合に完全にフラットにしきれないので、その場合は#mapと#flattenを使ってよいそうです。
Use
flat_mapinstead ofmap+flatten.
This does not apply for arrays with a depth greater than 2, i.e. ifusers.first.songs == ['a', ['b','c']], then usemap + flattenrather thanflat_map.flat_mapflattens the array by 1, whereasflattenflattens it all the way.
# 不可
all_songs = users.map(&:songs).flatten.uniq
# 良好
all_songs = users.flat_map(&:songs).uniq
#reverse.eachよりも#reverse_eachがよい
Prefer
reverse_eachtoreverse.eachbecause some classes thatinclude Enumerablewill provide an efficient implementation. Even in the worst case where a class does not provide a specialized implementation, the general implementation inherited fromEnumerablewill be at least as efficient as usingreverse.each.
reverse_eachは少なくともreverse.eachより効率が落ちることはなく、クラスによってはreverse_eachの実装の方が効率がよいそうです。
# 不可
array.reverse.each { ... }
# 良好
array.reverse_each { ... }
文法編は今回で完了です。来週はいよいよ「命名編」に進みます。ご期待ください。
関連記事
- Rubyスタイルガイドを読む: ソースコードレイアウト(1)エンコード、クラス定義、スペース
- Rubyスタイルガイドを読む: ソースコードレイアウト(2)インデント、記号
- Rubyスタイルガイドを読む: 文法(1)メソッド定義、引数、多重代入
- Rubyスタイルガイドを読む: 文法(2)アンダースコア、多重代入、三項演算子、if/unless
- Rubyスタイルガイドを読む: 文法(3)演算子とif/unless
- Rubyスタイルガイドを読む: 文法(4)ループ
- Rubyスタイルガイドを読む: 文法(5)ブロック、proc
- Rubyスタイルガイドを読む: 文法(6)演算子など
- Rubyスタイルガイドを読む: 文法(7)lambda、標準入出力など