
Unicodeで絶対知っておくべきセキュリティ5つの注意(翻訳)
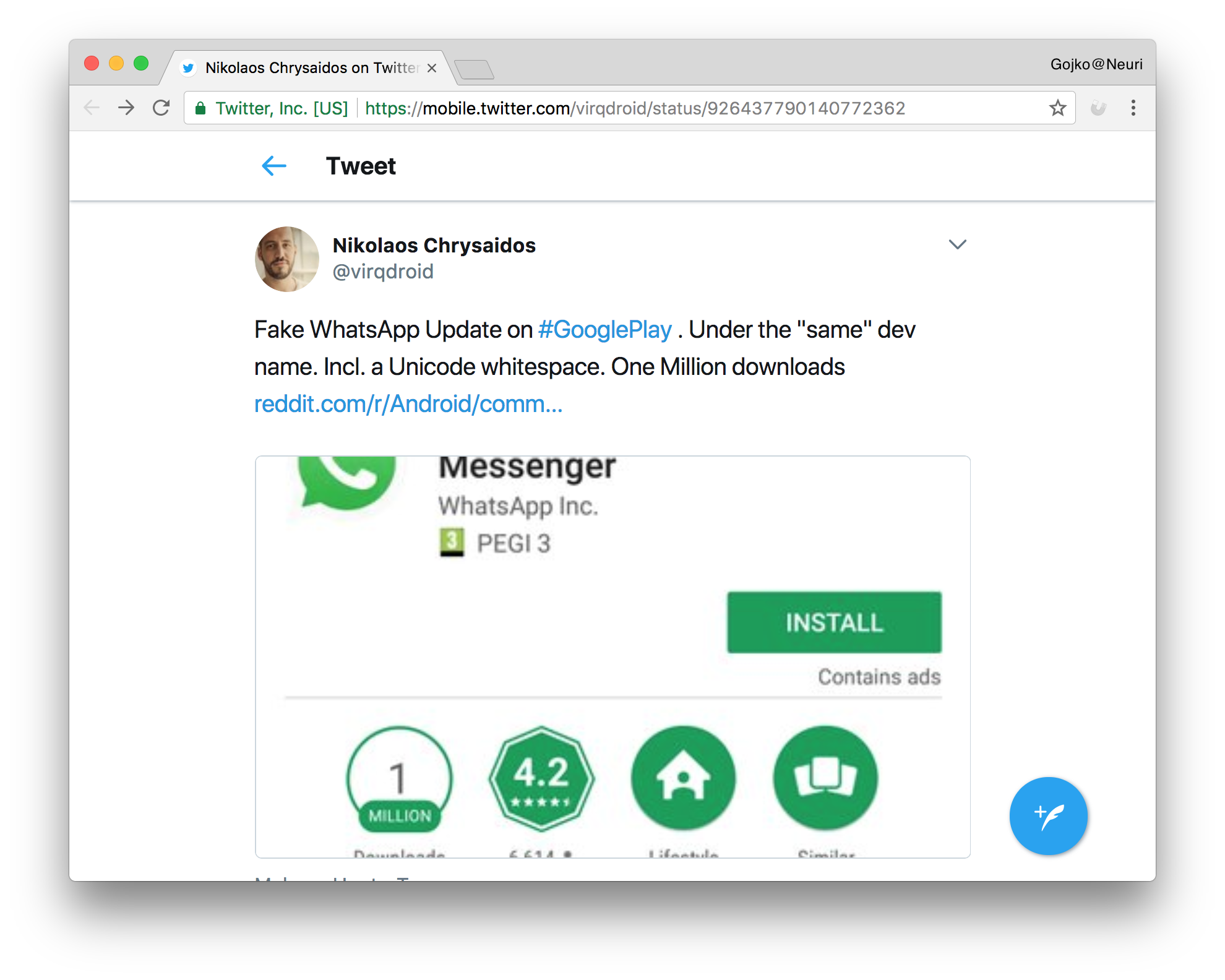
先週の「WhatsApp Androidの偽アプリ出現」のニュースによると、公式アプリと同じ開発者に見える名前で偽アプリが提供されました。この詐欺師は、印刷に現れないスペース文字を開発者名に混ぜ込むことでバリデーションのすり抜けに成功しました。このハックによって、Play Storeのメンテナーが気づくまでに100万人以上が騙されました。
Unicodeの標準としての価値は計り知れません。UnicodeのおかげでPCやスマホ、ウォッチを問わず同じメッセージを同じ方法で世界中どこでも表示できます。残念なことに、Unicodeが複雑なせいで、詐欺師やいたずら小僧どもにとって格好の金の鉱脈になってしまっています。Unicodeで引き起こされる基本的な問題をGoogleなどの巨大企業が食い止められないのであれば、中小企業にとっては勝ち目のない戦いに感じられてしまうのではないでしょうか。しかし、問題を引き起こしているのは、ほとんどが一握りの乱用です。詐欺行為を防ぐために、開発者なら誰もが知っておくべきUnicodeの知識トップ5をご紹介いたします。
1. 画面に表示されないUnicodeポイントがたくさんある
Unicodeには「ゼロ幅」のコードポイントがいくつもあります。たとえばzero-width joiner(U+200D)やzero-width non-joiner(U+200C)はハイフネーションのヒントとして使われます。これらの文字は画面上には表示されませんが、文字列を比較するときに影響を与えます。WhatAppアプリの詐欺が長い間発覚しなかった理由はこれです。こうした文字の多くはGeneral Punctuationブロック( U+2000〜U+206F)に含まれています。一般に、このブロックのコードポイントをIDの文字に利用する必然性はないのでフィルタは簡単です。しかし、Mongolian Vowel Separatorのように、この範囲外にも特殊な非表示コードがいくつか存在します。
一般に、Unicodeの一意性制約に単純な文字列比較を使うのは危険です。考えられる回避法としては、悪用される可能性のあるIDやその他のデータに許可されている文字セットを制限することです。残念ながら、これですべての問題を解決できるわけではありません。
2. 見た目が極めて似ているコードポイントがたくさんある
Unicodeは世界中のあらゆる手書き言語で使われるシンボルをすべてカバーしようとしているため、人間には区別不可能なほど見た目が互いによく似ている文字がどうしても増えてしまいます。しかしコンピュータならあっさりと区別できます。この問題を利用したいたずらとしてMimicというお遊びユーティリティがあり、これはソフトウェア開発でよく使われるシンボル(コロンやセミコロンなど)を見た目のよく似た別のUnicode文字に差し替えてしまいます。コード編集ツールはカオスと化し、開発者が混乱する可能性があります。

見た目のよく似たシンボルの問題は、単なるいたずらにとどまりません。homomorphic(準同型)攻撃と呼ばれる、これを悪用した攻撃手法によって深刻なセキュリティ問題が生じることがあります。2017年4月、セキュリティの研究者は異なる文字セットを混ぜ込むことでapple.comと見た目のそっくりなドメインを登録し、さらにSSL証明書まで取得してみせました。主要なブラウザは何も知らずにSSL鍵を表示し、このドメインを「安全」なものとして扱ってしまいました。
表示可能文字と非表示文字の混在と同様、ID(特にドメイン名)の文字に別の文字セット名の混用を許可する正当性はまずありません。ほとんどのブラウザでは、文字セットの混在したドメイン名を16進Unicode値で表示することでペナルティをかけ、ユーザーが簡単に惑わされないようにしています。ユーザーにIDを表示しようとする場合(検索結果など)は、混乱防止のため同様の手法を検討してください。しかし、これも完全な解決方法ではありません。sap.comやchase.comといった一部のドメインは、非ラテン文字セットのブロック1つだけで完全に構成できてしまいます。
Unicodeコンソーシアムは紛らわしい文字一覧を公開しており、詐欺の可能性を自動チェックするときの資料として有用かもしれません。その他に、紛らわしい文字の簡単な作り方をお探しの方はShapecatcherというサイトをチェックしてみてください。このツールは、手書きの文字に似ているUnicodeシンボルのリストを表示します。
3. 正規化で正しく正規化されるとは限らない
ユーザー名などのIDで、ユーザーのID入力方法が異なる場合にも処理を統一するためには、正規化(normalization)が重要です。IDの正規化によく使われる方法のひとつは、すべて小文字に変換することです。たとえばJamesBondはjamesbondと同じになります。
互いによく似た文字や重複したセットが多数存在するため、(自然)言語が異なっていたりUnicode処理ライブラリが異なっていたりすると、適用される正規化戦略もそれによって変わることがあります。正規化が複数箇所に分散していると、セキュリティ上のリスクにつながる可能性があります。要するに、アプリのさまざまな部分で行われる小文字変換の動作がすべて同じであると仮定すべきではないということです。SpotifyのMikael Goldmann氏は、同社のユーザーのひとりがアカウントハイジャック手法を発見した後、この問題について2013年に見事なインシデント分析を行いました。攻撃者が他人のユーザー名をUnicode異体字で登録すると(ᴮᴵᴳᴮᴵᴿᴰなど)、同じ正規アカウント名(bigbird)に変換される可能性があります。語の正規化手法がアプリのレイヤごとに異なる場合、偽アカウントを登録してパスワードをリセットできてしまいます。
4. 画面上に表示される文字の長さとメモリサイズはまったく別物
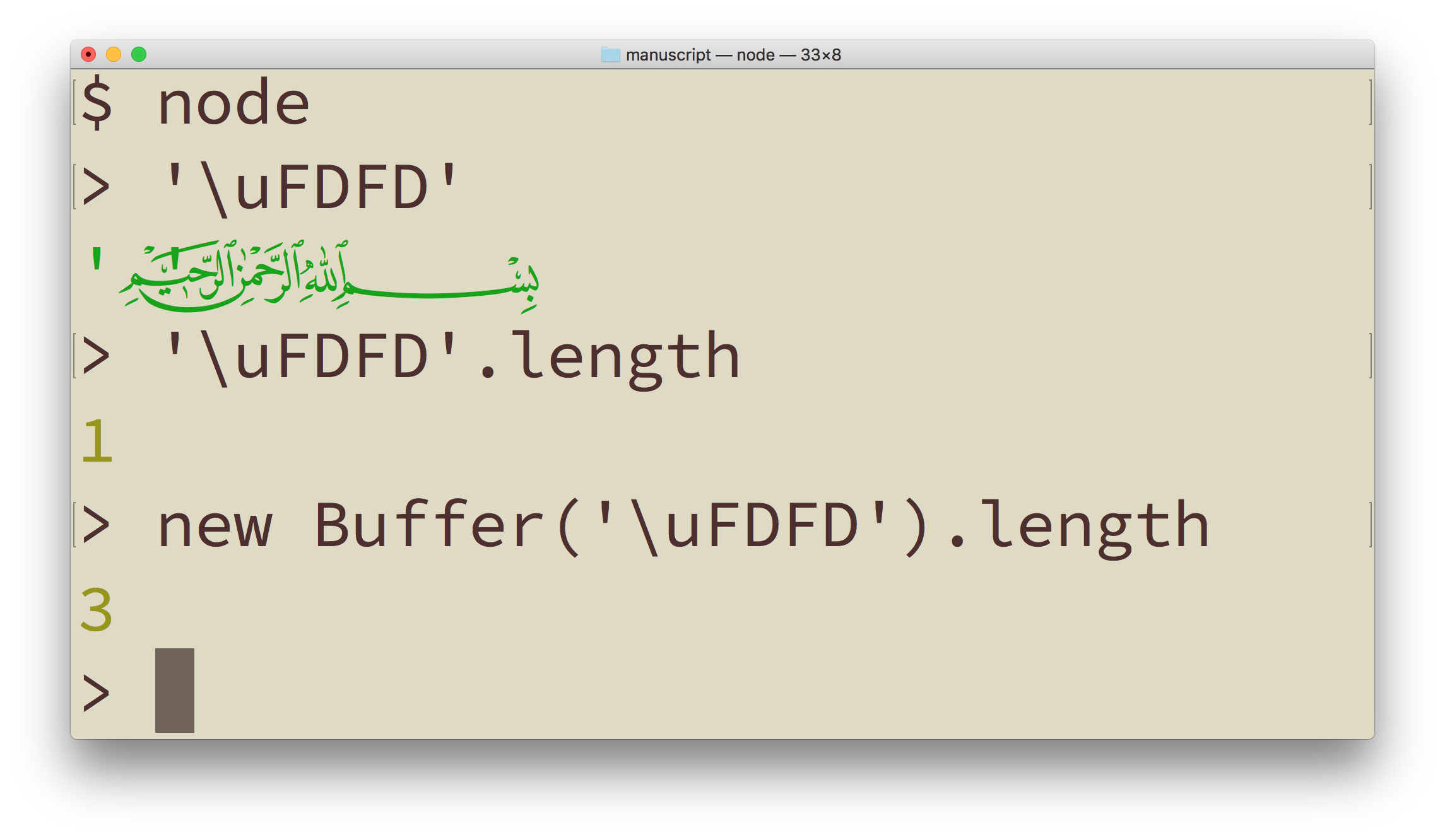
基本的なラテン文字セットや多くのヨーロッパ文字セットでは、画面や紙の上のテキスト片が占める幅は、シンボルの個数におおむね比例し、テキストのメモリ上のサイズにもおおむね比例します。EM(「M」という文字の幅)やEN(「N」という文字の幅)が長さの単位としてよく使われる理由はこれです。しかしUnicodeではこうした仮定はことごとく危険です。Bismallah Ar-Rahman Ar-Raheem(U+FDFD)のように、たった1文字でそこらの英単語よりも長くなる愛すべきシンボルは山ほどあり、Webサイトで仮定される表示上の囲みからあっさりはみ出してしまいます。つまり、文字列の文字長をベースとするワードラップやテキスト折り返しのアルゴリズムはことごとく破綻してしまうということです。ターミナルで動作するCLIプログラムのほとんどは固定長フォントを前提としているので、ターミナルにこうした文字を表示すると、引用符の位置が完璧にずれてしまうのがわかります。
これをいたずらに使ったzalgo text generatorというサイトは、入力したテキスト片の周りにゴミ文字を大量に追加して、テキストが上下方向に大きくはみ出すように変えてしまいます。
もちろん、非表示コードポイント全体の問題によってメモリサイズと画面上のサイズの関連性が失われてしまうため、画面サイズに収まるよう巧妙に調節したテキストをフィールドに入力すればデータベースのフィールドがパンクする可能性もあります。固有のスペース(幅)を持たない例は他にも膨大にあるので、非表示文字をフィルタするだけでは不十分です。
U+036BやU+036Cなどの「combining latin character」は直前の文字の上に配置されるので、1行のテキスト内に複数行のテキストを書けるようになります(N\u036BO\u036CはNͫOͬと表示される)。ヘブライ語聖書の経典朗唱向けのイントネーションを表すカンティレーション記号(参考)は、同じ表示スペースにいくつでも重ねられるので、画面上のたった1つの文字に大量の情報をエンコードするという悪用が簡単にできてしまいます。Kartin Kleppeは、古典的なライフゲーム(参考)のブラウザ版実装にカンティレーション記号をエンコードしてみせました。このページのソースコードを見た方は相当なショックを受けるでしょう。
5. Unicodeは単なるパッシブデータではない
コードポイントによっては、表示可能な文字の表示方法に影響を与えるよう設計されているものがあります。つまり、ユーザーがコピペしているのは単なるデータ以上のものであり、処理インストラクションも入力できるということです。よくあるいたずらとして、right-to-left override(U+202E)文字でテキストの進行方向を変えてしまうというのがあります。たとえば、Google MapsでNinjasを検索してみてください。このクエリ文字列は実際には検索ワードを逆順にしたものになっているので、ページには「ninjas」と表示されていますが、実際には「sajnin」を検索しています。
この手口は有名になり、XKCDでネタとして使われたほどです。

データと処理インストラクション(事実上の実行可能コード)の混在は絶対によくありません。ユーザーが処理インストラクションを直接入力できてしまう場合は特にそうです。ユーザー入力をそのままページに表示すれば大きな問題になります。ほとんどのWeb開発者はそのことを知っているので、ユーザー入力からHTMLタグを除去してサニタイズしますが、ユーザー入力にUnicodeの制御文字が含まれる可能性にも注意が必要です。これは禁止用語やコンテンツのフィルタリングをすり抜ける初歩的な方法であり、語の文字を逆順にしてright-to-leftを語の最初に置いてオーバーライドするだけでできてしまいます。
right-to-leftをハックして悪意のあるコードを埋め込むのはさすがに無理かもしれませんが、気をつけないとコンテンツ表示を台無しにされる、つまりページ全体の文字が逆順で表示される可能性があります。よく行われている対策は、ユーザーが入力するコンテンツの置き場所をinputフィールドやtextエリアに限定して、処理インストラクションがせめてページの他の部分に効かなくなるようにすることです。
もうひとつ、表示の処理インストラクションで特に大きな問題として、異体字(variation)セレクタがあります。色違いの絵文字ごとにコードを作成するのを避けるために、Unicodeでは異体字セレクタで基本シンボルと色をミックスできるようになっています。white flagにrainbow異体字セレクタを適用するとrainbow flagになります。しかし異体字がすべて有効とは限りません。2017年1月、iOSのUnicode処理のバグが原因で、ある仕掛けを施したメッセージを送りつけるだけでiPhoneをリモートでクラッシュさせるといういたずらが発生しました。このメッセージには1つのwhite flag、1つの異体字セレクタ、そして1つのゼロが含まれていました。iOS CoreTextは正しい異体字を取り出そうとしてパニックになり、iOSがクラッシュしました。このトリックはダイレクトメッセージやグループチャットの他、共有連絡先カードにも通用し、iPadや一部のMacbookまでこの問題の影響を受けました。この悪用によるクラッシュの防止策はほとんどありませんでした。
この種のバグは数年に1度は発生します。2013年には、アラビア文字の処理でOS XやiOSをクラッシュさせる可能性のあるバグが見つかりました。こうしたバグはOSのテキスト処理モジュールの奥底に潜んでいるため、一般のクライアントアプリ開発者には防止策がまったくありません。
その他の興味深い処理インストラクションについては、GitHubで公開されているAwesome Codepointsリストで確認できます。Unicodeによって引き起こされる問題についてもっと詳しくお知りになりたい方は、拙著『Humans vs Computers』をぜひチェックしてください。
(image credits: Amador Loureiro)

関連記事
The post Unicodeで絶対知っておくべきセキュリティ5つの注意(翻訳) first appeared on TechRacho.
概要
原著者の許諾を得て翻訳・公開いたします。
画像はすべて元記事からの引用です。