
Rubyオブジェクトの未来をつくる「シェイプ」とは(翻訳)
これはRubyKaigi 2021で行ったセッションの原稿につき、スライドやコードを見ながら話しているかのような口語体で書きました。
皆さんこんにちは、Chris Seatonです。ShopifyのシニアスタッフエンジニアとしてRubyのパフォーマンス研究に従事しており、非常に高度に最適化されたRuby実装であるTruffleRubyを立ち上げました。また、Rubyに関する研究のまとめサイト『The Ruby Bibliography(rubybib.org)』も運営しています。
本日は、TruffleRubyがRubyオブジェクトを実装するのに用いている既存のいくつかのアイデアのうち、MRIや他のRubyの実装への応用が見込めるものについて紹介したいと思います。これらのアイデアの由来や歴史の解説、TruffleRubyがオブジェクトをどのような形で実装しているか、それによって達成できたこと、どうすれば同じことをMRIで実現できるかについてお話しいたします。
それから将来も視野に入れ、こうしたアイデアの上にどんなものを構築できるかについてお話しいたします。
Rubyの「もしも〜だったら」とは
Rubyが他の言語に比べてときどき遅くなることがある理由を聞かれたら、私なら「もしも〜だったら」を筆頭の理由に挙げます。
Rubyの実装では、プログラムを実行するときに「もしもこうだったら、ああだったら」を考えるのに多くの時間を費やします。足し算のたびに「オーバーフローしたらどうするか」、メソッドを呼び出すたびに「メソッドがモンキーパッチされていたらどうするか」、コードの1行1行で「トレースが有効にされていたらどうするか」といったことを判断しなければなりません。
大量の「もしも〜だったら」のコストを削減するために、現在も多くの作業が進められており、MJIT、JRuby、Sorbet Compiler、YJIT、TruffleRubyなど、いずれも何らかの形でこの問題に取り組んでいます。しかしJRubyとTruffleRubyを除けば、Rubyオブジェクトの扱いはどれも同じであり、そこではRubyオブジェクトの「もしも〜だったら」は未だに解決していません。
Rubyのオブジェクトには「もしも〜だったら」が多数関連付けられています。オブジェクトがfrozenだったらどうするか、欲しいインスタンス変数がオブジェクトになかったらどうするか、オブジェクトが複数のRactorで共有されていたらどうするかなど、常に判断を下さなければなりません。今から説明する「オブジェクトシェイプ(object shape)」というアイデアは、可能な限りこうした「もしも〜だったら」の排除を試みる手法です。オブジェクトシェイプという次なる手段によって、MJITやSorbet CompilerやYJITなど、Rubyでその他のパフォーマンス向上に取り組むときの効果も高まると考えている方が何人もいます。
この後説明するように、オブジェクトシェイプは時間的なパフォーマンス向上のみならず、Rubyプログラムの実行に必要なメモリ空間上のメリットも得られる可能性があります。
Rubyオブジェクトとは
ここでお話しするRubyのオブジェクトは、特に「インスタンス変数を持つオブジェクト」を指します。また、インスタンス変数がオブジェクト内にどのように格納される方法についても解説します。オブジェクトには他にも興味深い点がたくさんあり、本セッションを通じてより詳しく説明しますが、「ビッグアイデア」の部分ではインスタンス変数に絞ってお話しいたします。

Rubyのオブジェクトは目的に応じたさまざまなキーバリューペアの入れ物になります。Rubyの Hashと異なり、これらのキーはすべてシンボルで、キーバリューペアはいかなる方法でも順序付けられません。
インスタンス変数は@構文で読み出したり設定したりできますが、instance_variable_getメソッドやinstance_variable_setメソッドでも同じことができます。また、instance_variables などのメソッドですべてのキーを取得することも、defined?などのキーワードでキーが設定されているかどうかを知ることもできます。こうしたインスタンス変数の取得や設定に使える同様のツールはデバッガにも装備されていることがあります。理想的には、これらの構文やメソッドの重要性や最適化の価値はどれも同じであると考えたいと思います。それによって、どの方法が速いかを気にすることなく、自分が解決しようとする問題に適したツールを使えるようになります。
ここでぜひとも強調しておきたいのですが、Rubyのインスタンス変数は「概念的にはオブジェクトの中に存在する」ことが重要なポイントです。つまり、インスタンス変数はオブジェクトのクラスやメタクラスの一部でもなければクラスの中で定義されるのでもなく、そのまま使われるということです。
Ruby実装でのオブジェクトの扱い
オブジェクトとインスタンス変数の動作について、いくつかのRubyの実装を見てみましょう。
MRI
(なお、このセッションでお見せするコードは、わかりやすくするために大幅に簡略化されており、クラスインスタンス変数、埋め込みインスタンス変数、ジェネリックインスタンス変数といった議論と無関係な多くのエッジケースや最適化を省略してあります。)
MRI(CRuby)は,C言語で実装されたRubyの標準的な実装です.最初にMRIのデータ構造を見てみましょう.
struct RObject {
VALUE klass;
int numiv;
VALUE[] ivptr;
};
struct RClass {
struct st_table *iv_index_tbl; // Hash of Symbol -> index
};
オブジェクトには、「クラスへの参照」「オブジェクト内にある多数のインスタンス変数への参照」「インスタンス変数の値の配列への参照」があります。
クラスはインスタンス変数名のハッシュを、インデックス(ivptr)へのシンボルの形でオブジェクト内に持ちます。
それでは、これらのデータ構造にアクセスするMRIのコードを見てみましょう。ここでは、すべてが順調な場合に実行される「高速パス(fast path)」すなわち「ハッピーパス」にのみ注目します。なお、Rubyらしく書かれたコードはほとんどがこのパスを通ります。それ以外のすべてを処理する「低速パス」すなわち「フォールバック」コードもありますが、ここでは扱いません。
このコードでは、class_serialが前回のアクセス時に記録された「期待されるclass_serial」と同じであることを確認していることがわかります。class_serialはクラスのバージョン番号で、クラスが変更されるとインクリメントされます。また、オブジェクトのサイズが同じクラスの他のインスタンスのサイズと異なる可能性もあるので、必要な数のインスタンス変数スロットがオブジェクトにあるかどうかもチェックする必要があります。
VALUE vm_getivar(VALUE obj, IVC inline_cache) {
if (inline_cache && inline_cache->class_serial == obj->klass->class_serial) {
int index = inline_cache->index;
if (obj->type == T_OBJECT) && index < obj->numiv) {
return obj->ivptr[index];
} else {
// 低速パス
}
} else {
// 低速パス
}
}
VALUE vm_setivar(VALUE obj, VALUE val, IVC inline_cache) {
if (inline_cache && inline_cache->class_serial == obj->klass->class_serial) {
int index = inline_cache->index;
if (obj->type == T_OBJECT) && index < obj->numiv) {
obj->ivptr[index] = val;
} else {
// 低速パス
}
} else {
// 低速パス
}
}
理解しやすさのために以下のような疑似Rubyコードで考えてもかまいません。
訳注
上のパラグラフは以下のように詳しく説明されています。
so to get an ivar we have a cache which is passed by the interpreter and we have the receiving object that contains instance variable we check that the cache’s serial number is the same as the object’s actual serial number at the moment
and we check that the expected number of instance variables is less than the number that has and then we can go ahead and read it
otherwise we use a slow path
and the code for setting is very similar
just instead of returning reading from ivptr we write into it
and again we have a slow path for writing
6:06字幕より(整形)
def vm_getivar(cache, obj)
if cache.serial == obj.klass.serial && cache.index < obj.numiv
obj.ivptr[cache.index]
else
# 低速パス
end
end
def vm_setivar(cache, obj, val)
if cache.serial == obj.klass.serial && cache.index < obj.numiv
obj.ivptr[cache.index] = val
else
# 低速パス
end
end
JRuby
JRubyは、RubyのJava再実装です。MRIのさまざまなJITと異なり、オブジェクトの振る舞いについても再実装されています。
JRubyは、@構文で参照される変数についてすべてのメソッド(継承されたメソッドを含む)を探索することで、クラスで使われる可能性のあるインスタンス変数を静的に推測します。そして実行時に、Rubyのインスタンス変数ごとに1つのJavaフィールドを含む新しいJavaクラスを生成します。生成されたこれらのJavaクラスは、同じ個数の変数を含むすべてのRubyクラスで共有されます。
続いて各Rubyクラスは、インスタンス変数名とそれに対応するJavaフィールドのマップを持ちます。
class TwoVariablesObject {
Object var0;
Object var1;
}
JRubyでは、コードがこれらの変数に効率的にアクセスするためにinvokedynamicと呼ばれるJVMのメカニズムを利用しています。ここではJavaのコードには触れずに、効果的な結果をRuby擬似コードでスケッチしてみましょう。
訳注
上のパラグラフに続いて以下も説明しています。
so for the java version of vm get ivar
we check that the caches id which is like a class serial is the same as the
meta classes
real classes id
and then again we can object we can index into the object
and again there’s a slow path
動画7:59字幕より(整形)
def vm_getivar(cache, obj)
if cache.id == obj.getMetaClass().getRealClass().id
obj[cache.index]
else
# 低速パス
end
end
このアプローチのメリットは、インスタンス変数の個数が静的に割り当てられるため、オブジェクトのクラスが期待どおりであることだけを確認すればよく、MRIで行われていた「オブジェクトがインスタンス変数のための十分なメモリー領域が確保されているかどうかの確認」を削減できることです。オブジェクトのクラスidは、キャッシュされている値と比較されます。残念ながら、これはオブジェクトから3ホップ離れています。これが効率よく処理されるには、「オブジェクト」と「そのメタクラス」および「その論理クラス」がすべてCPUキャッシュに乗っていることを期待しなければなりません。
もうひとつの制限は静的な推測です。変数やクラスがメタプログラミングで設定されたために推測を誤ると、インスタンス変数を読み書きする低速パスにフォールバックしてしまいます。この振る舞いはRubiniusでも同じです。
JRubyによるこのトレードオフには賛否両論ありますが、私たちは「シェイプ(shape)」を用いることで両方の長所を最大限に活かせると考えています。
シェイプの歴史
オブジェクトシェイプの歴史は、プログラミング言語「Smalltalk」と「Self」までさかのぼります。この2つの言語は言語設計や歴史の話によく登場すると思いますが、シェイプはこれらの言語を研究していた研究者によって生みだされた技術の好例です。
訳注
動画では上のパラグラフの途中で以下も言及されています。
people are always very keen to say their language is inspired by self and smalltalk in the same way they’re keen to say it’s inspired by haskell
動画09:41字幕より(整形)
私たちの分野の歴史について多くを語るつもりはありませんが、この機会にこのアイデアの元となった論文を少し見てみましょう。
そもそもの出発点はSmalltalkでした。

今でこそSmalltalkはシンプルでエレガントな言語と考えられていますが、当時は複雑すぎるという意見もありました。その反動で、開発者の表現力や生産性の向上(今で言う「開発者の幸せ」)を目的としたSelfというよりシンプルな言語が開発されました。

Selfでシンプルさを追求するために行われた改善のひとつが、クラスの代わりにプロトタイプを追加することでした(プロトタイプはJavaScriptのオブジェクトと同じように振る舞います)。Rubyにもクラスはありますが、個別のインスタンスメソッドやインスタンス変数の依存先は論理的なクラスだけではありませんので、(訳注↓)
訳注
上のパラグラフ1文目は実際には以下のように話しています。
one of the improvements for simplicity they added was prototypes instead of classes
and that’s prototypes as in the way javascript objects work if you have experience with javascript as well
so javascript doesn’t have classes it simply has objects which have properties
and to inherit you point to another object as your fallback for reading properties if they’re not in the object you directly access
動画10:39字幕より(整形)
また、同パラグラフの末尾では以下が補足されています。
so ruby is somewhat more like prototypes than pure objects
動画11:04字幕より(整形)
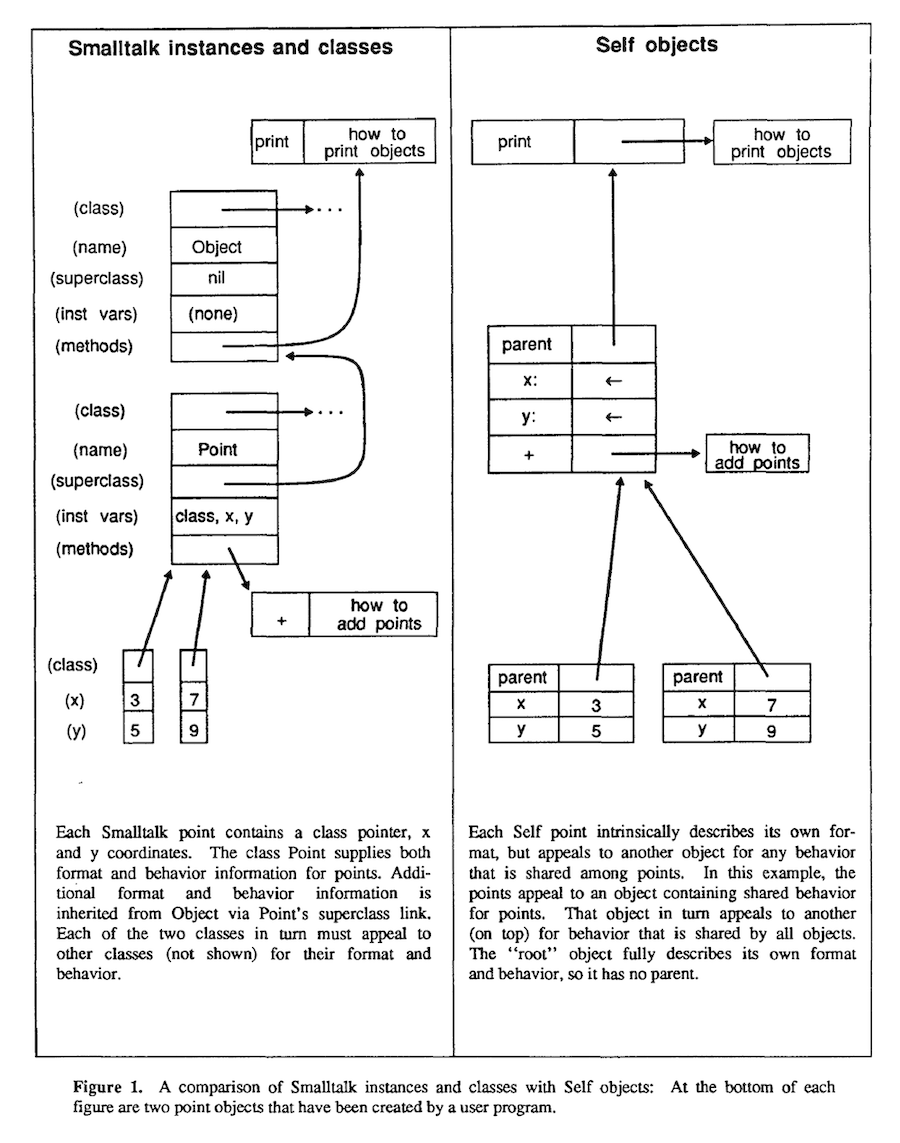
当初のSelfは、開発者の幸せを優先したことと引き換えに低効率でした。開発者の幸せを優先する言語は、残念ながらパフォーマンスで多少の犠牲を払うことになりますが、その点はRubyと似ているかもしれません。しかしこれが研究者たちにとって、Selfの効率を高め、導入されたコストを克服して自分たちの望む設計を実現する方法を見出そうとするモチベーションにつながりました。

この研究が、現在も影響の大きい「ポリモーフィックインラインキャッシング(polymorphic inline caching)」などの主要な開発をリードしました。ここではこの技術について説明しませんが、現代のJavaやJavaScriptの高パフォーマンスの鍵となっています。TruffleRubyでは、Rubyのメタプログラミングを最適化するために「ディスパッチチェイン(dispatch chain)」と呼ばれる新しい形のポリモーフィックインラインキャッシングを採用しています。
私たちの興味をそそった主要な開発は「シェイプ」です。Selfでは「マップ(map)」と呼ばれていますが、現代のJavaScriptの文脈では「隠しクラス(hidden class)」と呼ばれることもあります(「マップ」だとハッシュと混同される可能性があるので私たちは「シェイプ」という用語を使っています)。
ここで用いたのは「インスタンス変数のキーと値の分離」というアイデアでした。キーは「マップ」に保存され、これによってオブジェクト内の値のインデックスを取得できます。オブジェクトはマップを参照しているので、ある変数にどの値を読み込めばいいのかはマップを用いて調べられます。
なお、元々このアイデアが導入された動機の一部は、実際にはスピードではなくメモリ空間でした。各オブジェクトがキーのコピーを保持する必要がなくなるからです。
訳注
上のパラグラフ後半は実際には以下のように話していました。
because when they switched to prototypes they realized all objects had a full set of keys as well as the values
and they realized that by separating them out they no longer needed to keep all those copies because of objects with the same keys could share them
動画13:10字幕より(整形)
ビッグアイデア
以上が、元の研究者たちによって記述された歴史です。ここからは、もっと具体的にRubyと関連する用語や図を用いてこのビッグアイデアをひととおり説明していきます。

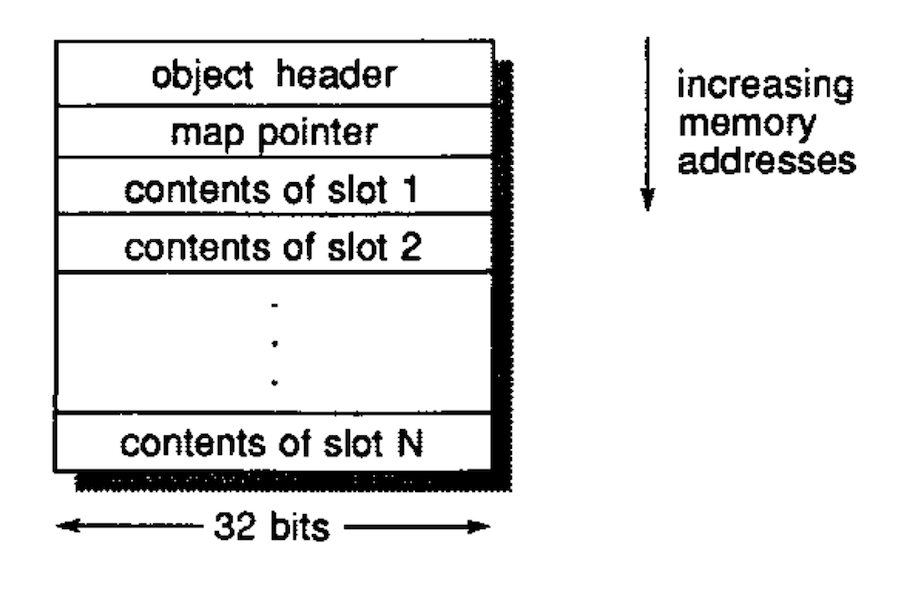
ここでは「シェイプ」と呼ばれるものを使います。ひとつのシェイプには、インスタンス変数名から、そのシェイプを持つすべてのオブジェクトにおけるインデックスへのマップが含まれます。上の図ではシェイプを破線で、オブジェクトを実線で表しています。このオブジェクトはクラス(ここでは重要ではありません)とシェイプを参照します。
訳注
上のパラグラフ後半は動画でもう少し詳しく説明されています。
so there’s an arrow from the object to the shape
and the the class and the shape pointers together represent the header of the object with same the object then contains just the values
and the shape contains this mapping from names to indexes so it doesn’t contain a value of instance variables
it just contains an index saying where to find them
動画14:12字幕より(整形)
各オブジェクトには必ず「シェイプ」があります1。オブジェクトにシェイプが与えられると、そのシェイプで必要となる適切な量のメモリ空間も与えられます。空間がどのように使われるかはシェイプによって記述されます。
訳注
上のパラグラフは動画でもう少し詳しく説明されています。
every object has a shape
so objects initially created with a special empty shape for example
when an object is given a shape is also given the right amount of space that shape requires
so it may require resizing the object or using a separate data structure such as an object array to store if the shape needs to be if the object needs to be increased in size
how the space in the object is used is described by the shape so you think of the shape as metadata something that describes the the data and how it can be used or you can think of it as a schema from a database context
動画14:39字幕より(整形)
あるインスタンス変数を取得するには、概念上はシェイプのインデックスを探索してからそのスロットをオブジェクトから読み取ります。
index = obj.shape[:name]
obj[index]
以前に設定されたことのあるインスタンス変数を設定する場合、概念上は同じことを行いますが、値を書き込む点が異なります。
index = obj.shape[:name]
obj[index] = value
オブジェクト内で未設定のインスタンス変数を設定した場合の挙動については後述します。
これはMRIの振る舞いとどう違うのでしょうか?
訳注
動画では上と下のパラグラフのつながりを以下のように話しています。
so how is this different to what mri is doing because it seems sort of similar
well the key differences start with that shapes are immutable and we know that immutability is often a good way to do design software
動画16:26字幕より(整形)
主な違いは、シェイプはイミュータブル(不変)という点です。つまり、過去のある時点でどんなシェイプだったかがわかれば、以後そのシェイプに関するすべてを確実に把握できるようになります。しかもこの仮定はハードコードできます。
また、シェイプはクラスから切り離されており2、同じクラスの2つのインスタンスがそれぞれ異なるシェイプを持つことも可能です。つまり、他のインスタンスが変更されたからといって背後のオブジェクトを変更する必要はありません。
以上のすべてが、あるシェイプを自分が期待するシェイプと比較できることを示しています(おそらくプロセッサ上のシンプルなワード比較が使えるでしょう)。シェイプは、MRIでクラスのインスタンス変数テーブルが変更されるときのような形では変更できません。
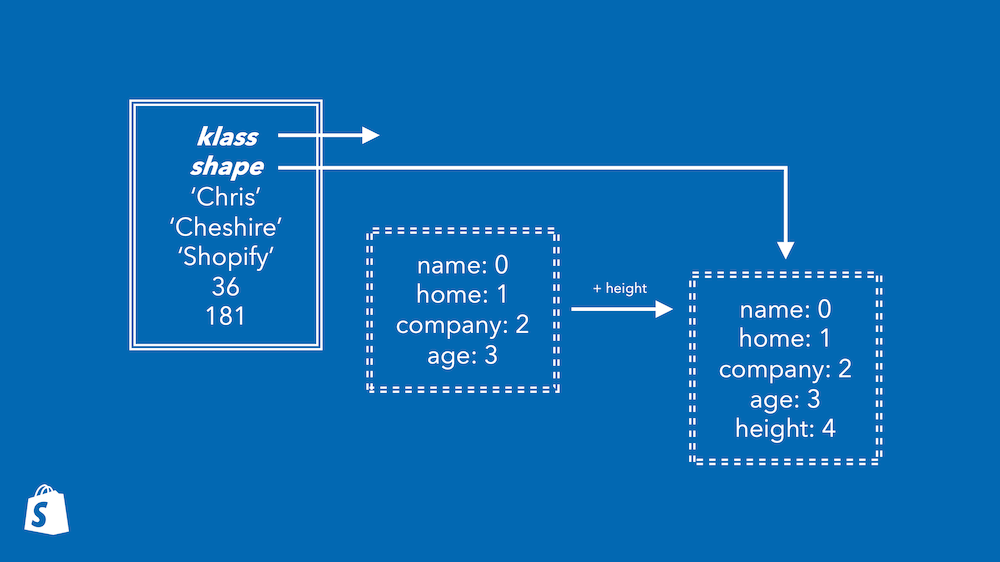
未設定のインスタンス変数を設定する場合は、「遷移(transition)」と呼ばれるものを使います。シェイプは、インスタンス変数を追加・削除・変更したときにどのようなシェイプになるかについても認識しています。この図の場合、このシェイプは「height変数が追加されたら別のシェイプに遷移する」ことを認識しています。これで、このプログラムで行われる時間遷移をすべて記述するシェイプのグラフを得られます。
オブジェクトの遷移は低速パスではありません。既に得られたシェイプの情報のみを用いて素早く実行できます。
new_shape = obj.shape.transitions[:add_height]
index = new_shape[:height]
obj.shape = new_shape
obj.resize
obj[index] = value
以上のすべてのしくみは、マシンコードへのコンパイルと組み合わせたときに最大の効果を発揮します。マシンコードにはハードコードされた値を含められるので、比較するオブジェクトシェイプのアドレスをハードコードでき、利用するインデックスもそれに基づいてハードコードできます。これによって、マシン語のワード比較と読み取りが利用可能になります。比較に失敗した場合は、プロセッサが比較の成功を事前に予測して読み取りを続行可能なので、遠くを参照する低速パスのコードも同時に実行されます。
slow_path unless obj.shape == 0x12345678
obj[4]
TruffleRubyはシェイプをどう扱うか
TruffleRubyにおけるシェイプの実装方法については、研究論文『An Object Storage Model for the Truffle Language Implementation Framework』(Andreas Wößほか)に記載されています。

ここでは、TruffleRubyがRubyプログラムの解釈と最適化に利用する一種の内部グラフデータ構造(「中間表現」と呼ばれます)を示す形でTruffleRubyの機能を紹介します。グラフの可視化にはShopifyが開発したSeafoamというツールを用いました。

def getter
@ivar
end
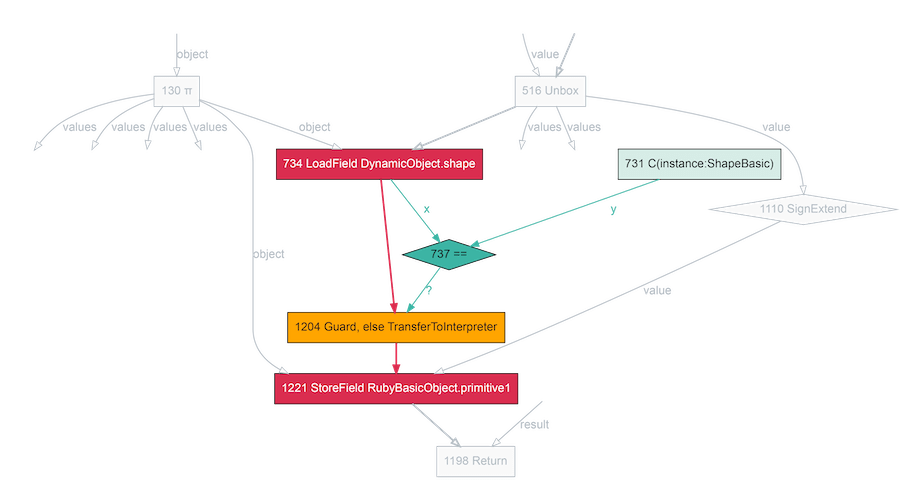
上のコンパイラグラフ断片では、ノードが操作を、太い赤線が制御フローを、細い緑の線がデータフローをそれぞれ表しています。これは、Rubyの暗黙の部分を明示的に表したRubyコードのフローチャート版です。
ここでのインスタンス変数の読み込みは、シェイプの読み込みと既知のシェイプとの比較に続いて、「ガード」または「比較が失敗した場合は低速パスへのジャンプ」のいずれかを経て、オブジェクト内の既知の場所primitive1を読み込む形で行われていることがわかります。
対応するマシンコードでは、予測されたシェイプとの比較、同じでない場合は低速パスにジャンプ、変数の読み込みと進むことがわかります。以下の3つのマシン語インストラクションがそれです。
0x1242ec600: cmp dword ptr [rax*8 + 0xc], expected_shape
0x1242ec60b: jne slow_path
0x1242ec611: mov r10d, dword ptr [rax*8 + index]
上のグラフ断片には、既にオブジェクト内に存在するインスタンス変数を設定するセッターコードがあるので、ここではシェイプの変更が不要であることがわかります。このコードはゲッターと同じですが、最後の2つのオペランドが読み込みではなく書き込みになっている点が異なります。
def setter(value)
@ivar = value
end
0x11fd28a00: cmp dword ptr [rsi*8 + 0xc], expected_shape
0x11fd28a0b: jne slow_path
0x11fd28a1f: mov qword ptr [rsi*8 + 0x20], r10
![]()
インスタンス変数がまだ存在していない場合は、現在のシェイプからの遷移に沿う形でシェイプを変更します。シェイプにあるものはすべてハードコードされているので、遷移もハードコードされます。つまり新しい値を書き込むのと同様に新しいシェイプを書き換えればよくなります。
class Klass
def initialize(a)
@a = a
end
def transition(value)
@b = value
end
end
loop do
instance = Klass.new(14)
instance.transition rand(100)
end
0x12b53bb00: cmp dword ptr [rax*8 + 0xc], expected_shape
0x12b53bb0b: jne slow_path
...
0x12b53bb33: mov dword ptr [rax*8 + 0xc], new_shape
...
シェイプに型付けする
これで、Ruby でシェイプを適用するためのより高度なアイデアについて説明する準備が整いました。TruffleRubyのシェイプは、インスタンス変数名と保存場所のマッピング(対応付け)を行うほかに、それらの型についてもマッピングできます。
現在のMRIでは、あらゆるインスタンス変数が完全なVALUEオブジェクトとして保存されます。小さな整数は、インスタンス変数として保存するためにタグ付け(tagged)されなければならず、取り出すときにはタグ解除(untagged)されます。コンパイラはタグ付けやタグ解除を避けたいので、インスタンス変数が常に整数であることをシェイプに書き込んでおけば、そこに保存する値にタグ付けする必要もなく、取り出す値をタグ解除する必要もないことがわかります。後でその変数が別の何かに変わった場合は、新しい変数を追加するときと同じようにシェイプを遷移させます。
この動作はTruffleRubyで確認できます。
以下のaddルーチンは1個のオブジェクト内に置かれ、2つのインスタンス変数は常に小さな整数です。生成されたマシンコードは、シェイプをチェックしてからオブジェクトから値を読み取りますが、タグ解除もアンボクシング(unboxing: 開封)も行わず、シンプルに値を利用していることがわかります。これが可能なのは、これらの変数が小さい整数型であることをシェイプからコンパイラに伝えているからです。シェイプをチェックするときに型もチェックされるので、1回のチェックで2つの変数を同時にカバーできました。これで「Cコンパイラから出力したかのようなコードが得られます。
訳注
アンボクシングについて動画では以下のように補足しています。
unboxing is java’s version of untagging
動画30:12字幕より(整形)
また、上のパラグラフの「これが可能なのは〜」以後は実際には以下のように話しています。
so it reads from the object into esi and eax which are two registers
then it does an add operation on them
but it doesn’t untag them normally you’d have to shift the value
to get rid of the tag data
so it knows when they come out they’re untagged
and they can do whatever you need to do for that point
you can just use them as it is in this case
um or it might want to tag them again to pass them on somewhere else
when we checked the shape we also checked the types right so that one check covered both variables at the same time and checked covering their types
because of the the shape includes the type information of all the variables
so just checking the shape checks all the types at once
and also checks the layout of the object
and also that that a shape check is already there for the layout
so we get it for free for checking the rest of them
so when we check this shape we also checked the types
and that one check covered both variables at the same time
so now we’re getting code that looks more like it came out of a c compiler than that it came out of a ruby
動画30:19字幕より(整形)
def add
@a + @b
end
0x12258d380: cmp dword ptr [rax*8 + 0xc], expected_shape
0x12258d38b: jne slow_path
0x12258d391: mov esi, dword ptr [rax*8 + index_a]
0x12258d398: mov eax, dword ptr [rax*8 + index_b]
0x12258d39f: mov r10d, eax
0x12258d3a2: add r10d, esi
0x12258d3a5: jo overflow
シェイプの他の使いみち
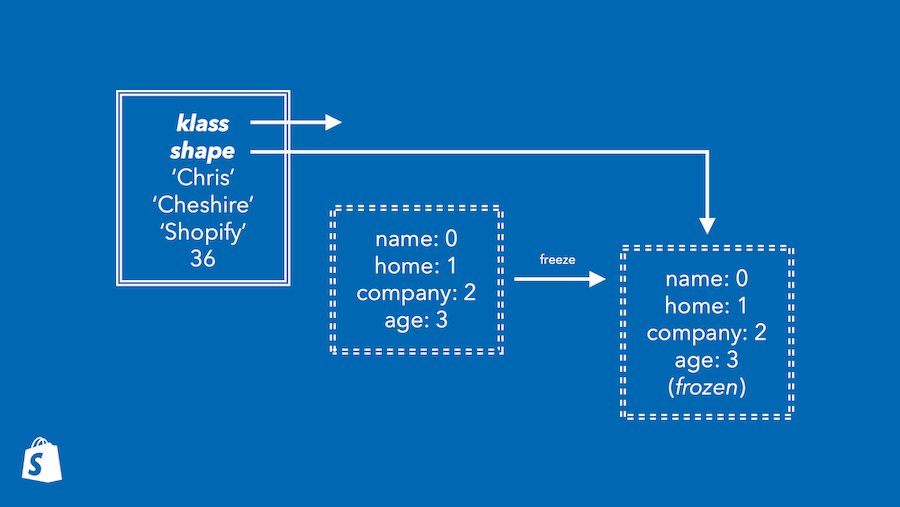
さらに工夫を重ねるとすれば、他にどんなものをシェイプに移せるでしょうか。インスタンス変数と「同型(isomorphic: ここではインスタンス変数と少し似ているというニュアンス)」のオブジェクトのプロパティは、他にもクラスへの参照やfrozenステートなどがあります。これらをシェイプに保存すると2つのメリットが得られます。1つ目は、オブジェクトに保存するワードとビットが1つずつ減り、スペースを節約できることです。2つ目は、メソッド呼び出しでの「クラスチェック」「frozenチェック」「インスタンス変数書き込みチェック」という3種類のチェックをシェイプチェック一発で完了できることです。
TruffleRubyでは既にfrozenチェックをシェイプに取り込んでいます。上述のセッターの例で言うと、オブジェクトがfrozenかどうかをチェックするコードは以下のどこにも見当たりません。
0x11fd28a00: cmp dword ptr [rsi*8 + 0xc], expected_shape
0x11fd28a0b: jne slow_path
0x11fd28a11: mov eax, dword ptr [rdx + index]
しかしチェックはしっかり行われています。この expected_shapeは統計的にfrozenでないことが判明しています。オブジェクトがfrozenの場合は、このシェイプではなく、frozenとマークされた別のシェイプということになります。これは、Ruby言語機能のオーバーヘッドを「完全に」取り除けることが示された素晴らしい例です。
現在のTruffleRubyは、シェイプにクラスを取り込んでいません。理由は、メソッド呼び出しで「クラスチェック」と「インスタンス変数のチェック」を混同するのはよろしくないと考えられているからです。つまり、複数のオブジェクトが異なるインスタンス変数を持っているという無関係な理由で、メソッド呼び出しでポリモーフィズムが発生してしまう可能性があるということです。
訳注
上のパラグラフに続いて以下も述べられています。
so two objects which you could dispatch the method called in the same way
you’d be looking differently just because they’re different instance variables which is unrelated
動画30:29字幕より(整形)
TruffleRubyでは、オブジェクトがスレッド間で共有されているかどうかについてもシェイプでマークしており、該当する場合は同期のためにロックを有効にします。同じアイデアはRactorのチェックでも利用可能でしょう。
オブジェクトで他に何かできるか
一般に、Rubyの最適化作業の多くは、Rubyの実行モデルの最適化です。MJIT、YJIT、Sorbet Compilerは、インタープリタをJITコンパイルされたマシンコードに置き換えますが、VMの他の部分には手を付けません。MJITとSorbet Compilerは、標準のMRIに接続するためにコードから事実上のC拡張を生成しており、YJITもだいたい似たような感じですが、(訳注↓)
私は、Ruby最適化を頑張るなら、もっとオブジェクトに目を向ける必要があると考えています。Shopifyではガベージコレクタのコンカレント圧縮やオブジェクトの可変長アロケーション(VWA: variable width allocation)、新しいガベージコレクタといったホットなアイデアに取り組んでいます。TruffleRubyではハッシュや配列がさらに最適化されたことで、サイズや内容に応じた特殊化が可能になりました。TruffleRubyでは、partial escape analysisと呼ばれる非常に強力な最適化をいくつか行っています。これにより、小さなメソッドグループ内でしか使われないオブジェクトが仮想化され、決してアロケーションされないようになります。
実用的な提案
私からの実用的な提案の筆頭は「MRIにオブジェクトシェイプを実装しよう」というものです。実際には実装の複雑さは比較的小さいと思いますし、現在のMRIインタプリタの高速化にも即効性が期待できるでしょう。今後MJITやYJITの開発を進める上でもきっと役に立つはずです。
このアイデアがうまくいくことはTruffleRubyで示されていますし、さらにすごいものを構築できる可能性もあります。この実践的な実装の詳細については先ほど紹介したTruffleRubyの論文で述べられており、そこで達成されたパフォーマンスについても他のいくつかのRubyメソッドと比較されています。
これについて解決の必要となる大きな問題はないと思います。本当に必要なのは、1980年代初頭からの一連の研究成果を元に構築してくれる勇者たちでしょう。
訳注
上に続いて以下も述べられています。
that we can follow that is proven that we can implement in ruby
and as we showed when we talked about the history
ruby is already philosophically aligned to the languages where it came from
and that the problems it’s trying to solve
both in terms of developer happiness and optimizing for that
but now trying to cover some of the performance
and we’re aligned to what ourselves are trying to do
so it makes sense to to keep using their techniques
動画36:42字幕より(整形)
MRIへのオブジェクトシェイプ導入について私からのお話は以上です。ご清聴ありがとうございました。
参考資料
- L. Peter Deutsch and Allan M. Schiffman. 1984. Efficient implementation of the Smalltalk-80 system. In Proceedings of the 11th ACM SIGACT-SIGPLAN symposium on Principles of programming languages (POPL ’84).
-
David Ungar and Randall B. Smith. 1987. Self: The power of simplicity. In Conference proceedings on Object-oriented programming systems, languages and applications (OOPSLA ’87).
-
Elgin Lee. Object Storage and Inheritance for Self. Engineer’s thesis, Electrical Engineering Department, Stanford University, 1988.
-
C. Chambers, D. Ungar, and E. Lee. 1989. An efficient implementation of SELF a dynamically-typed object-oriented language based on prototypes. In Conference proceedings on Object-oriented programming systems, languages and applications (OOPSLA ’89).
-
Urs Hölzle, Craig Chambers, David Ungar. Optimizing Dynamically-Typed Object-Oriented Languages With Polymorphic Inline Caches. In ECOOP ’91.
-
David Ungar and Randall B. Smith. 2007. Self. In Proceedings of the third ACM SIGPLAN conference on History of programming languages (HOPL III).
-
Andreas Wöß, Christian Wirth, Daniele Bonetta, Chris Seaton, Christian Humer, and Hanspeter Mössenböck. 2014. An object storage model for the Truffle language implementation framework. In Proceedings of the 2014 International Conference on Principles and Practices of Programming on the Java platform: Virtual machines, Languages, and Tools (PPPJ ’14).
-
Stefan Marr, Chris Seaton, and Stéphane Ducasse. 2015. Zero-overhead metaprogramming: reflection and metaobject protocols fast and without compromises. In Proceedings of the 36th ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI ’15).
-
Benoit Daloze, Stefan Marr, Daniele Bonetta, and Hanspeter Mössenböck. 2016. Efficient and thread-safe objects for dynamically-typed languages. In Proceedings of the 2016 ACM SIGPLAN International Conference on Object-Oriented Programming, Systems, Languages, and Applications (OOPSLA 2016).
-
本プレゼンテーションのスタイルの一部はBenoit Daloze氏による以下のシェイプに関する過去スライドにインスパイアされました。
メモ
撮影担当のSam Tamに感謝いたします。
ruby 3.0.2p107 (2021-07-07 revision 0db68f0233) [x86_64-darwin20]jruby 9.2.19.0 (2.5.8) 2021-06-15 55810c552b OpenJDK 64-Bit Server VM 11.0.2+9 on 11.0.2+9 +indy +jit [darwin-x86_64]truffleruby 21.2.0 (ruby 2.7.3に似ている)GraalVM CE JVM [x86_64-darwin]
関連記事
The post Rubyオブジェクトの未来をつくる「シェイプ」とは(翻訳) first appeared on TechRacho.


 )。
)。


 でパーマリンクを置いてあります: 社内やTwitterでの議論などにどうぞ
でパーマリンクを置いてあります: 社内やTwitterでの議論などにどうぞ

 | Riding Rails
| Riding Rails 」「Changelogには逆の関連付けにスコープがあると動かないと書かれていますね」「単純なものなら手動で書けば動かせますけど、逆の関連付けにスコープが付いていると自動でコードを生成するのは簡単ではなさそう」
」「Changelogには逆の関連付けにスコープがあると動かないと書かれていますね」「単純なものなら手動で書けば動かせますけど、逆の関連付けにスコープが付いていると自動でコードを生成するのは簡単ではなさそう」


 」「気持ちわかります」「Active Jobは抽象化されている分機能が少な目なので、生のSidekiqを使う方が話が早い」
」「気持ちわかります」「Active Jobは抽象化されている分機能が少な目なので、生のSidekiqを使う方が話が早い」










 」
」
 」
」






 」「
」「 」
」












 」
」 」「そうそう
」「そうそう



、高いほどよい")



 ngrock is an amazing tool to share localhost urls with teammates or touch devices
ngrock is an amazing tool to share localhost urls with teammates or touch devices 

 )。今使っているライブラリに同じようなソリューションがあるかどうかチェックするとよいでしょう。
)。今使っているライブラリに同じようなソリューションがあるかどうかチェックするとよいでしょう。








 Halloween Edition: Zeitwerk migration guide, selenium-webdriver, and some Ruby 3.1 snacks | Riding Rails
Halloween Edition: Zeitwerk migration guide, selenium-webdriver, and some Ruby 3.1 snacks | Riding Rails

 |gihyo.jp … 技術評論社
|gihyo.jp … 技術評論社








概要
原著者の許諾を得て翻訳・公開いたします。
日本語タイトルは内容に即したものにしました。本記事はRubyKaigi Takout 2021 Day2キーノートのスピーチ原稿につき、最終的な発表内容はこのとおりでない部分もあります。流れを把握するために必要と思われる部分については訳注で補足いたしましたが、わかりにくい場合は動画と合わせてご覧ください。
本記事ではshapeの仮訳として「シェイプ」を採用しています。