こんにちは、hachi8833です。Rubyスタイルガイドを読むシリーズは今回で最終回となります。
今後総集編として修正・アンカー追加などを行って1本の記事にまとめますので、今後はそちらをご覧ください。原文末尾のツールなどの記述は総集編に含めます。
Rubyスタイルガイド: 正規表現、%リテラル、メタプログラミングなど
正規表現
ひとつの問題に突き当たると「おっしゃ、正規表現の出番だ」と考えるタイプの人は、問題を2つに増やす。
— Jamie Zawinski
「文字列変数['テキスト']」で単純な文字列を検索するのであれば正規表現にしないこと
Don’t use regular expressions if you just need plain text search in string:
string['text']
正規表現厨の私も少々反省をうながされてしまいました。コードのシンプルさにおいてもパフォーマンスにおいても正規表現による検索は単なる文字列の場合と比べて見劣りします。上の指示は、「正規表現は本当に必要なときにだけ使うこと」を含意していると思います。
原文にないコード例を以下に追加してみました。
str = "Hello, Ruby!"
# 不可
if str[/Hello/].nil?
(省略)
end
# 可
if str['Hello'].nil?
(省略)
end
#良好(よりRubyらしい)
if str.includes? 'Hello'
(省略)
end
単純な文字列の存在チェックであれば#match?で文字列を指定するほうがシンプルな気もします。
補足: 文字列変数に配列っぽくアクセスする
Rubyでは、文字列変数に[ ]を追加することで配列「風」にアクセスできます。インデックスにあたる部分には単なる数値以外に範囲も指定できます。
str = 'Hello, Ruby!'
puts str[0] #=> H
puts str[0, 4] #=> Hell
puts str[0..4] #=> Hell
私も今回初めて知りましたが、この配列風文字列のインデックスには数値以外に文字列や正規表現を直接書くこともできます。文字列を直接書けるのであれば、必要もないのにわざわざ正規表現で書くこともありませんね。
str = 'Hello, Ruby!'
puts str['Hell'] #=> Hell
puts str['Hi'] #=> nil
puts str[/[Hh]ell/] #=> Hell
puts str[/^Hi$/] #=> nil
補足: 文字列置換の場合
文字列置換によく使われる#gsubや#subでは、正規表現でない文字列でも使えます。
また、特定の目的については便利なメソッドが既にあります。
以下も原文にないコード例です。
# 不可
'test.rb'.gsub(/\.rb/, '')
' Hello, Ruby! '.gsub(/^[ ]+|[ ]+$/, '')
# 良好
'test.rb'.tr('.rb', '') # 文字列を取り除くならtrなどがよい
'test.rb'.gsub('.rb', '') # 正規表現を使わないgsubでもよい
' Hello, Ruby! '.strip # 先頭・末尾の空白を取り除くならstripがよい
コードをシンプルにするために、文字列のインデックスに正規表現を直接書いてもよい
For simple constructions you can use regexp directly through string index.
上述の項で補足した「文字列のインデックスに正規表現を直接書く」方法も選択肢に含めてよいということですね。
コード例は原文のままだと少々わかりにくいので変更しました。
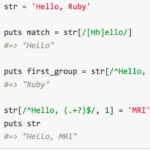
str = 'Hello, Ruby'
puts match = str[/[Hh]ello/] # 正規表現にマッチする部分文字列をstrから取り出す
#=> "Hello"
puts first_group = str[/^Hello, (.+?)$/, 1] # キャプチャグループ1を取り出す
#=> "Ruby"
str[/^Hello, (.+?)$/, 1] = 'MRI' # strのキャプチャグループ1を置き換える
puts str
#=> "Hello, MRI"
正規表現でキャプチャの結果が不要な場合はキャプチャなしグループ(?:)を使うこと
Use non-capturing groups when you don’t use the captured result.
正規表現で丸かっこ()を使った部分はキャプチャされ、番号を指定して後で取り出すことができます。
番号の代わりに(?'名前'パターン)などのようにグループに名前を付けることもできます。
キャプチャが発生するとその分パフォーマンスが下がることが考えられるため、それを避けるためにキャプチャなしグループ(?:)を使うのだと思います。
# 不可
/(first|second)/
# 良好
/(?:first|second)/
(?:pat)という記法を使うとキャプチャせずにグループ化することができます。 性能が多少改善する場合がありますが、多少見にくくなります。
Rubyリファレンスマニュアル: 正規表現より
ループ内などで正規表現を頻繁に使う場合は考慮しておくとよいと思います。
最後にマッチしたグループの取り出しにPerl由来の$記法($1や$2など)を使わないこと
Don’t use the cryptic Perl-legacy variables denoting last regexp group
matches ($1,$2, etc). UseRegexp.last_match(n)instead.
代わりにRegexp.last_match(n)を使うよう指示しています。
$%や$^や$#といったいかにも間に合わせでこしらえたような$記法は、どうしてもクイズになってしまい可読性が落ちますね。
Perlとは無関係に、$が多い記法は個人的にも目にイガイガを感じてしまいます。LaTeXとか。
/(regexp)/ =~ string
...
# 不可
process $1
# 良好
process Regexp.last_match(1)
$を使わない記法については以下の記事をご覧ください。
キャプチャグループは番号での指定ではなく名前付きグループでの指定が望ましい
Avoid using numbered groups as it can be hard to track what they contain. Named groups can be used instead.
番号でのキャプチャグループは、キャプチャ数が増えたりネストしたりしたときに追うのが本当につらいので、自分のためにもなるべく名前付きキャプチャを使いましょう。
# 不可
/(regexp)/ =~ string
# (何かする)
process Regexp.last_match(1)
# 良好
/(?<meaningful_var>regexp)/ =~ string
# (何かする)
process meaningful_var
文字クラス[ ]の中ではドット.やかっこの類をエスケープしないこと
Character classes have only a few special characters you should care about:
^,-,\,], so don’t escape.or brackets in[].
文字クラスを表す[ ]の中でエスケープが必要なのは、実は以下の文字だけです。これら以外の文字・記号は文字クラス内ではただのリテラルとして扱われます。
^- 文字クラスの否定を表すのに使う
[^0-9]: (0から9以外のすべての文字) -- 文字の範囲を表すのに使う
[0-9a-zA-Z0-9a-zA-Z]: (全角半角英数字) \- エスケープ文字
[@#$%\^&*\\]: (^と\を\でエスケープしている) ]- 文字クラスの終了を表す
[[\]]: (実は]だけエスケープすればよい)
上はもちろん、文字クラス[ ]の中だけの話です。
重要: パターンの冒頭と末尾は^や$ではなく、\Aと\zで表すこと
Be careful with
^and$as they match start/end of line, not string endings. If you want to match the whole string use:\Aand\z(not to be confused with\Zwhich is the equivalent of/\n?\z/).
有名な話ですが、Ruby、PHP、Perlなどの言語で使われている正規表現ライブラリで文の冒頭と末尾を^と$で表すと、改行文字\nを含むパターンを食べさせるインジェクションに対して脆弱になることがあります。
これを避けるために、パターンで文頭と文末を表すときは必ず\Aと\zを使いましょう。
string = "some injection\nusername"
string[/^username$/] # マッチしてしまう
string[/\Ausername\z/] # マッチしない
少々紛らわしいのですが、後者は大文字ではなく小文字の\zにしなければなりません。大文字の\Zにしてしまうと、末尾に改行がある場合にマッチしてしまうので対策として不完全です。
- 参考: 正規表現によるバリデーションでは ^ と $ ではなく \A と \z を使おう — 徳丸浩先生のブログです
念のため、Rubyリファレンス・マニュアルから引用します。
アンカーは幅0の文字列にマッチするメタ文字列です。 幅0とは文字と文字の間、文字列の先頭、文字列の末尾、などを意味します。ある特定の条件を満たす「位置」にマッチします。
・^行頭にマッチします。行頭とは、文字列の先頭もしくは改行の次を意味します。
・$行末にマッチします。 行末とは文字列の末尾もしくは改行の手前を意味します。
・\A文字列の先頭にマッチします。
・\Z文字列の末尾にマッチします。 ただし文字列の最後の文字が改行ならばそれの手前にマッチします。
・\z文字列の末尾にマッチします。
・\b単語境界にマッチします。 単語を成す文字と単語を成さない文字の間にマッチします。 文字列の先頭の文字が単語成す文字であれば、文字列の先頭 の位置にマッチします。
・\B非単語境界にマッチします。\bでマッチしない位置にマッチします。
Rubyリファレンスマニュアル: 正規表現より
複雑な正規表現ではx修飾子を使うこと
Use
xmodifier for complex regexps. This makes them more readable and you can add some useful comments. Just be careful as spaces are ignored.
x修飾子を指定するとスペースが無視されるので、以下のようにパターンを分解して行別に記述し、読みやすくできます。さらに#でコメントを書くこともできますので、使わない手はありませんね。私も今回初めて知りました。
その代わりスペースを直接書けなくなるので、\sなどで表す必要があります。なお私は個人的に[\p{Zs}]を使っています。
regexp = /
start # テキスト
\s # スペース文字
(group) # 最初のキャプチャグループ
(?:alt1|alt2) # 文字列のいずれかに一致
end
/x
なお、/xオプションを指定しない場合のコメントは(?# )で書けます。
regexp = /(?#ここにコメントを書く)Hello/
複雑な置換では、#subや#gsubにブロックやハッシュを与えてもよい
For complex replacements
sub/gsubcan be used with a block or a hash.
うまく使うと可読性が上がりそうですね。いいことを知りました。
words = 'foo bar'
words.sub(/f/, 'f' => 'F') # => 'Foo bar' (ハッシュを与える場合)
words.gsub(/\w+/) { |word| word.capitalize } # => 'Foo Bar' (ブロックを与える場合)
%リテラル
二重引用符を含む1行の文字列を式展開する場合は%()(%Qの省略形)を使う: 複数行ならヒアドキュメントを使う
Use
%()(it’s a shorthand for%Q) for single-line strings which require both interpolation and embedded double-quotes. For multi-line strings, prefer heredocs.
以下の3つの条件を満たす場合は%( )を使います。
- 式展開(
#{ })を含む - 二重引用符(
")を含む - 1行に収まる
# 不可(式展開がないなら'<div class="text">Some text</div>'とすべき)
%(<div class="text">Some text</div>)
# 不可(二重引用符がないなら"This is #{quality} style"とすべき)
%(This is #{quality} style)
# 不可(複数行ならヒアドキュメントにすべき)
%(<div>\n<span class="big">#{exclamation}</span>\n</div>)
# 良好(式展開が必要かつ二重引用符を含む1行の文字列は条件を満たす)
%(<tr><td class="name">#{name}</td>)
%()(または同等の%q())は、一重引用符と二重引用符を両方含む文字列以外では使わないこと
Avoid %() or the equivalent %q() unless you have a string with both
'and"in it. Regular string literals are more readable and should be preferred unless a lot of characters would have to be escaped in them.
エスケープしなければならない文字がたくさんあるのでなければ、読みやすい普通の文字列リテラルを使います。
# 不可
name = %q(Bruce Wayne)
time = %q(8 o'clock)
question = %q("What did you say?")
# 良好
name = 'Bruce Wayne'
time = "8 o'clock"
question = '"What did you say?"'
quote = %q(<p class='quote'>"What did you say?"</p>)
正規表現リテラル%rは、正規表現に/文字が含まれていなければ使わないこと
Use
%ronly for regular expressions matching at least one ‘/’ character.
確かに、必要もないのにわざわざ%rで可読性を下げることはありませんね。
# 不可
%r{\s+}
# 良好
%r{^/(.*)$}
%r{^/blog/2011/(.*)$}
コマンドリテラル%xは、コマンド自体にバッククォートが含まれているのでなければ避けること
Avoid the use of
%xunless you’re going to invoke a command with backquotes in it(which is rather unlikely).
コマンドリテラルにさらにバッククォートを含めないといけないようなシチュエーションは、そうなさそうです。
# 不可
date = %x(date)
# 良好
date = `date`
echo = %x(echo `date`)
シンボルリテラル%sの利用は避けること
Avoid the use of
%s. It seems that the community has decided:"some string"is the preferred way to create a symbol with spaces in it.
Rubyコミュニティでは、スペース含みのシンボル作成は原則として:"some string"のような方法で行うこと、と決定したそうです。
%リテラルで使うかっこは、リテラルの種類に応じて使い分けること
Use the braces that are the most appropriate for the various kinds of percentliterals.
Rubyでは%リテラルで使う囲み記号としてさまざまなものを使えますが、ともするとスタイルが不揃いになりがちなので、これで統一するということですね。
()丸かっこ- 文字列リテラル:
%qや%Q
その他のリテラル:%sや%x []角かっこ- 配列リテラル:
%w、%i、%W、%I
理由:通常の配列記法と整合するため {}波かっこ- 正規表現リテラル:
%r
理由:正規表現内では丸かっこ( )が多用されるため、正規表現での出現率が低い{ }が適切と判断
# 不可
%q{"Test's king!", John said.}
# 良好(文字列リテラルは丸かっこで)
%q("Test's king!", John said.)
# 不可
%w(one two three)
%i(one two three)
# 良好(配列リテラルは角かっこで)
%w[one two three]
%i[one two three]
# 不可
%r((\w+)-(\d+))
%r{\w{1,2}\d{2,5}}
# 良好(正規表現リテラルは波かっこで)
%r{(\w+)-(\d+)}
%r|\w{1,2}\d{2,5}|
メタプログラミング
本スタイルガイドでは、メタプログラミングについて全般に慎重な立場を取っています。
必要のないメタプログラミングは避けること
Avoid needless metaprogramming.
メタプログラミングは「やってみたかったから」という理由で導入されることがかなり多いように思えます。どんな場合に必要になるかですが、メタプログラミングでないとコードが書けないという事態は考えにくいので、ActiveRecordなど既存のメタプログラミングを拡張、改修する場合や、メタプログラミングの方がコードが簡潔かつ拡張しやすくなることが明らかな場合が主になるのかもしれません。
もちろん自分しか使わないことが確実なコードであれば存分に使ってもよいと思います。
モンキーパッチは使わないこと
Do not mess around in core classes when writing libraries. (Do not monkey-patch them.)
ライブラリを書くときにコアクラスを汚してはならない、だそうです。もっともです。
class_evalは文字列の式展開形式ではなくブロック形式が望ましい
The block form of
class_evalis preferable to the string-interpolated form.
- 文字列の式展開形式にする場合は、常に
__FILE__と__LINE__を追加してバックトレースを読みやすくすること
- when you use the string-interpolated form, always supply
__FILE__and__LINE__, so that your backtraces make sense:
class_eval 'def use_relative_model_naming?; true; end', __FILE__, __LINE__
define_methodの方がclass_eval{ def ... }よりも望ましい
define_methodis preferable toclass_eval{ def ... }
文字列の式展開でclass_evalなどのevalメソッドを使う場合は、式展開を具体的に示すコメントを追加すること
- When using
class_eval(or othereval) with string interpolation, add a comment block showing its appearance if interpolated (a practice used in Rails code):
以下はRailsのActiveSupportのコードです。右側のコメントで示されているのが#capitalizeメソッドを式展開した例です。
# activesupport/lib/active_support/core_ext/string/output_safety.rb より
UNSAFE_STRING_METHODS.each do |unsafe_method|
if 'String'.respond_to?(unsafe_method)
class_eval <<-EOT, __FILE__, __LINE__ + 1
def #{unsafe_method}(*params, &block) # def capitalize(*params, &block)
to_str.#{unsafe_method}(*params, &block) # to_str.capitalize(*params, &block)
end # end
def #{unsafe_method}!(*params) # def capitalize!(*params)
@dirty = true # @dirty = true
super # super
end # end
EOT
end
end
メタプログラミングは抽象度が高いので、こういう具体的な展開をコメントで添えておくことでずっと読みやすくなります。やっておかないと後できっと自分もつらくなります。
method_missingは避け、代わりに委譲、プロキシ、define_methodの利用を検討すること
Avoid using
method_missingfor metaprogramming because backtraces become messy, the behavior is not listed in#methods, and misspelled method calls might silently work, e.g.nukes.launch_state = false.
Consider using delegation, proxy, ordefine_methodinstead.
If you must usemethod_missing:
– Be sure to also definerespond_to_missing?
– Only catch methods with a well-defined prefix, such asfind_by_*— make your code as assertive as possible.
– Callsuperat the end of your statement
– Delegate to assertive, non-magical methods:
method_missingによるメタプログラミングはバックトレースが非常に追いづらく、#methodsでメソッドリストを取ることもできません。nukes.launch_state = falseのようなスペルの間違ったメソッド名が正規表現をすり抜けて思わぬ動作を引き起こす可能性すらあります。
IDEのコード定義ジャンプも効かなくなりますね。
method_missingの利用がどうしても避けられない場合は、以下を必ず守らなければなりません。
respond_to_missing?も定義することfind_by_*など、確実に定義されたプレフィックスだけをキャッチすること- 文の最後で
#superを呼ぶこと - 明示的に定義された(=黒魔術系でない)メソッドに委譲すること
# 不可
def method_missing?(meth, *params, &block)
if /^find_by_(?<prop>.*)/ =~ meth
# ここでがんばってfind_byを長々と実装する
else
super
end
end
# 良好
def method_missing?(meth, *params, &block)
if /^find_by_(?<prop>.*)/ =~ meth
find_by(prop, *params, &block) # 黒魔術でないメソッドを呼んでいる
else
super
end
end
# ただし検索可能な属性を宣言できるdefine_methodがやはりベスト
sendは避け、public_sendを使うこと
Prefer
public_sendoversendso as not to circumventprivate/protectedvisibility.
public_sendはprivateやprotectのスコープをすり抜けないことがその理由です。
# OrganizationというActiveModelがあり、Activatableというconcernがあるとする
module Activatable
extend ActiveSupport::Concern
included do
before_create :create_token
end
private
def reset_token
# コード
end
def create_token
# コード
end
def activate!
# コード
end
end
class Organization < ActiveRecord::Base
include Activatable
end
linux_organization = Organization.find(...)
# 不可(privateを呼べてしまう)
linux_organization.send(:reset_token)
# 良好(期待どおり例外が発生する)
linux_organization.public_send(:reset_token)
sendよりもアンダースコア付きの__send__が望ましい
Prefer
__send__oversend, assendmay overlap with existing methods.
sendは既存のメソッドをオーバーライドする可能性があるためです。
require 'socket'
u1 = UDPSocket.new
u1.bind('127.0.0.1', 4913)
u2 = UDPSocket.new
u2.connect('127.0.0.1', 4913)
# レシーバーオブジェクトにメッセージを送信しない
# 代わりにUDPソケット経由でメッセージを送信する
u2.send :sleep, 0
# レシーバーオブジェクトに実際にメッセージを送信する
u2.__send__ ...
その他
ruby -wオプションを使って安全なコードを書くこと
Write
ruby -wsafe code.
警告を無視してはならないということですね。忙しいときでも一度はやっておきましょう。
オプションパラメータにハッシュを使うことは避ける
Avoid hashes as optional parameters. Does the method do too much? (Object initializers are exceptions for this rule).
大量のハッシュオプションが必要になるほどメソッドの機能が多いのは、設計に問題があると考える方がよさそうです。オブジェクトの初期化メソッドでのオプションハッシュは認められます。
これはまさに「Railsフレームワークで多用される「options = {} 」引数は軽々しく真似しない方がいいという話」で書いた話ですね。
1つのメソッドのコードは10行以内に収めること
Avoid methods longer than 10 LOC (lines of code). Ideally, most methods will be shorter than 5 LOC. Empty lines do not contribute to the relevant LOC.
理想は5行以内だそうです。
空行、メソッド定義とそれに対応するendはカウントしません。コメント行もカウントしなくてよいと思います。
5個以上のパラメータリストは避ける
Avoid parameter lists longer than three or four parameters.
パラメータ数は現実には多くなってしまいがちなので、「避ける」どまりになっています。パラメータが多いということはメソッドの機能が過剰になっている可能性があるので、メソッドの分割も必要かもしれません。
以下は原文にないサンプルです。
def deliver_mail(
to: 'ex@example.com',
from: 'exa@example.com',
subject: 'My message',
header:,
body: )
...
end
「グローバルな」メソッドがどうしても必要な場合は、Kernelクラスのprivateメソッドにすること
If you really need “global” methods, add them to Kernel and make them private.
具体的な書き方については以下をご覧ください。
参考
グローバル変数は使わないこと: 必要な場合はモジュールのインスタンス変数を使う
Use module instance variables instead of global variables.
ただ「グローバル変数を使うな」としか書いてないと回避方法がばらついてしまうので、回避方法をスタイルガイドで統一している点が重要ですね。
# 不可
$foo_bar = 1
# 良好
module Foo
class << self
attr_accessor :bar
end
end
Foo.bar = 1
コマンドラインオプションが複雑になったらOptionParserを使い、細かなオプションではruby -sを使う
Use
OptionParserfor parsing complex command line options andruby -sfor trivial command line options.
OptionParserはRuby標準のコマンドライン解析ライブラリです。ruby -sを使うと、スクリプト名の後にもオプションを書けるようになります。
この種の解析ライブラリはたくさんあるので、もっとよいものがあればそちらを使い、開発者の間でばらつくようなら標準のものを使うということでよいと思います。
- Rubyリファレンスマニュアル: optparseライブラリ
特に理由がない限り、状態を持つことを避けて関数型っぽく書くこと
Code in a functional way, avoiding mutation when that makes sense.
原文がえらく走り書きなのですが、次の文ともからめておおよそ上のような意図だと思います。
破壊的なメソッドを書く場合を除き、受け取ったパラメータを変更しないこと
Do not mutate parameters unless that is the purpose of the method.
ついでに、破壊的なメソッド名の末尾には!を付けるようにしましょう。
ブロックの4重以上のネストは避ける
Avoid more than three levels of block nesting.
ブロックのネストが増え過ぎたら、ブロックをメソッドとして切り出すなどで回避します。
コーディングスタイルを一貫させること
Be consistent. In an ideal world, be consistent with these guidelines.
言うまでもないことですね。
過去のコードをそのままに途中からスタイルを変えるのはよくありません。
常識を働かせること
Use common sense.
たった一言ですが、スタイルガイドに盲目的に従うものではないと警告していると私は考えます。
本スタイルガイドには3つの側面があります。
- A. 必須・禁止事項を示す(やるべきこと、やってはならないこと)
- B. スタイルを示す(書き方がばらつかないために、ある程度合理的な理由に基づいた指針)
- C. コーディング上の便利なヒント
Aはもちろん守るべきですが、Bはデフォルトのスタイルとして使うほかに、書き方に迷った場合や開発者同士で意見が割れた場合の指針にも使えます。
Bは案件によって細かな点が違うのが普通なので、スタイルを守ろうとするあまり無理な書き方になっては元も子もありません。
Cはそれらとは別に有益な技術情報として利用できます。
A、B、Cがスタイルガイドに分類なしで盛り込まれていてやや雑然としているので、元のドキュメントでもそうした情報が項目ごとに示されるとよいですね。きれいに分類できるとも限らないので難しいとは思いますが。
ご愛読いただきありがとうございました。
関連記事
- Rubyスタイルガイドを読む: ソースコードレイアウト(1)エンコード、クラス定義、スペース
- Rubyスタイルガイドを読む: ソースコードレイアウト(2)インデント、記号
- Rubyスタイルガイドを読む: 文法(1)メソッド定義、引数、多重代入
- Rubyスタイルガイドを読む: 文法(2)アンダースコア、多重代入、三項演算子、if/unless
- Rubyスタイルガイドを読む: 文法(3)演算子とif/unless
- Rubyスタイルガイドを読む: 文法(4)ループ
- Rubyスタイルガイドを読む: 文法(5)ブロック、proc
- Rubyスタイルガイドを読む: 文法(6)演算子など
- Rubyスタイルガイドを読む: 文法(7)lambda、標準入出力など
- Rubyスタイルガイドを読む: 文法(8)配列や論理値など
- Rubyスタイルガイドを読む: 命名
- Rubyスタイルガイドを読む: コメント、アノテーション、マジックコメント
- Rubyスタイルガイドを読む: クラスとモジュール(1)構造
- Rubyスタイルガイドを読む: クラスとモジュール(2)クラス設計・アクセサ・ダックタイピングなど
- Rubyスタイルガイドを読む: クラスとモジュール(3)クラスメソッド、スコープ、エイリアスなど
- Rubyスタイルガイドを読む: 例外処理
- Rubyスタイルガイドを読む: コレクション(Array、Hash、Setなど)
- Rubyスタイルガイドを読む: 数値、文字列、日時(日付・時刻・時間)