
概要
原著者の許諾を得て翻訳・公開いたします。
- 英語記事: Configuring Puma, Unicorn and Passenger for Maximum Efficiency
- 原文公開日: 2017/10/12
- 著者: Nate Berkopec (@nateberkopec): Railsのパフォーマンスコンサルタントです。
- 主著: The Complete Guide to Rails Performance

画像はすべて元記事からの引用です。
Rails: Puma/Unicorn/Passengerの効率を最大化する設定(翻訳)
まとめ: アプリのサーバー設定はRuby Webアプリのスループットやコストあたりのパフォーマンスに大きな影響を与えます。設定の中でも最も重要なものについて解説します(2846 word、13分)
RubyのWebアプリサーバーは、ある意味で自動車のガソリンに似ています。よいものを使ってもそれ以上速くなりませんが、粗悪なものを使えば止まってしまいます。実際にはアプリサーバーでアプリを著しく高速化することはできません。どのサーバーもだいたい同じようなものであり、取っ替え引っ替えしたところでスループットやレスポンスタイムが向上するわけではありません。しかしダメな設定を使ったりサーバーで設定ミスしたりすれば、たちまち自分の足を撃ち抜く結果になります。クライアントのアプリでよく見かける問題のひとつがこれです。

本記事では、3つの主要なRuby アプリサーバーであるPuma、Unicorn、Passengerについてリソース(メモリやCPU)の使用状況の最適化やスループット(要するに1秒あたりのリクエスト数です)の最大化について解説します。本記事では仮想環境に特化した話はしませんので、「サーバー」と「コンテナ」という言葉を同じ意味で使います。
3つのサーバーの設計は本質的に同じなので、1つのガイドで3つの著名なアプリサーバーをカバーできます。どのサーバーもfork()システムコールを使っていくつもの子プロセスを生成してからリクエストを処理します1。これらサーバーの違いのほとんどは細かい部分にとどまります(本記事ではパフォーマンス最大化が重要な箇所でこうした詳細にも触れる予定です)。
本ガイドを通じて、コストあたりのサーバースループットの最大化を試みます。サーバーリソース(とキャッシュも)が最小の状態から、サーバーが扱える秒あたりのリクエスト数を最大化したいと思います。
パフォーマンス最大化でもっとも重要な設定
アプリサーバーには、パフォーマンスやリソース消費を決定する基本的な設定が4つあります。
- 子プロセスの数
- スレッドの数
- Copy-on-Write
- コンテナのサイズ
それぞれの設定を見ていきましょう。
* 看護師: 「あなたは31秒前からdynoですね」
* 患者: 「マジで!すぐユーザーのところに戻って、せっかく作ったこのレスポンスを返しに行かなきゃ…」
タイムアウトもそれなりに重要ですが、スループットにはそれほど関連しません。私は今後のためにタイムアウトは変更しないでおきます。

子プロセスの数
Unicorn、Puma、Passengerは、いずれもforkを使う設計になっています2。つまり、アプリのプロセスを1つ作成し、そこから多数のコピーを作成します。これらのコピーは子プロセスと呼ばれます。サーバーごとの子プロセス数は、コストあたりのスループット最大化でおそらく最も重要な設定でしょう3。
私が推奨する設定は、すべてのRuby Webアプリで1つのサーバーにつきプロセスを3つ以上実行することです。この設定によってルーティングで最大のパフォーマンスを得られます。PumaとUnicornは、どちらも複数の子プロセスが1つのソケットで直接リッスンする設計になっており、プロセス間のロードバランシングはOSが行います。PassengerはnginxやApacheなどのリバースプロキシを用いて多数のリクエストを1つの子プロセスにルーティングします4。どちらのアプローチも効率はかなり高く、リクエストはアイドリング中のワーカーに素早くルーティングされます。同じことを上位レイヤでのルーティング(ロードバランサーやHerokuのHTTPメッシュを指します)で効率よく行うのは、ルーティング先のサーバーがビジーかどうかをロードバランサー側から確認できないことが多いため、かなり難しくなります5。
サーバーが3個、1サーバーあたり1プロセス(つまりプロセスは全部で3個)の編成で考えてみましょう。このときロードバランサーはどのようにして1つのリクエストを3つのサーバーのいずれかに適切にルーティングするのでしょうか。「ランダムに選ぶ」方法や「ラウンドロビン」方式でも可能ですが、その場合アイドリング状態のサーバーへのルーティングは保証されません。たとえばラウンドロビン戦略で、リクエストAがサーバー#1にルーティングされるとします。リクエストBはサーバー#2にルーティングされ、リクエストCはサーバー#3にルーティングされます。
子プロセスが全部ビジーな状態でリクエストを1つ受け取ったときの私の顔。

ここで4つ目のリクエストDが来たとします。リクエストBとCの処理が首尾よく完了したおかげでサーバー#2と#3が暇になっているのに、リクエストAは誰かがCSVをエクスポートしようとしていて完了までに20秒かかるとしたらどうでしょう。ロードバランサーはサーバー#1がビジーであることには構わずリクエストを投げつけるので、リクエストAが完了するまで処理できません。サーバーが完全に死んでいるかどうかを確認する手段はどんなロードバランサーにもありますが、そうした手段はほとんどの場合かなりのタイムラグを伴います(遅延が30秒以上など)。1つのサーバーで実行するプロセス数をもっと増やせば、サーバーレベルではリクエストがビジーなプロセスに割り当てられなくなるため、多くの子プロセスが処理に時間のかかるリクエストで手一杯になってしまうリスクを断ち切ることができます。代わりに、リクエストはワーカーが空くまでソケットレベルまたはリバースプロキシでバックアップされます。これを達成するには、私の経験上1サーバーあたり3プロセス以上が最小値として適切です。リソースの制約のために1サーバーで最小3プロセスを実行できないのであれば、もっと大きなサーバーにしましょう(後述)。
つまり、1つのコンテナでは子プロセスを少なくとも3つは実行すべきです。しかし最大値はどうすればよいでしょうか。これについてはリソース(メモリとCPU)で制限されます。
まずはメモリから考えてみましょう。各子プロセスはある量のメモリを利用します。明らかに、サーバーのRAMがサポートできる個数を上回る子プロセスを追加するべきではありません。
Rubyプロセスの実際のメモリ使用量は対数的に増加します。メモリ断片化が発生するため、増加は水平にならず、単に上限に向かって増加し続けます。
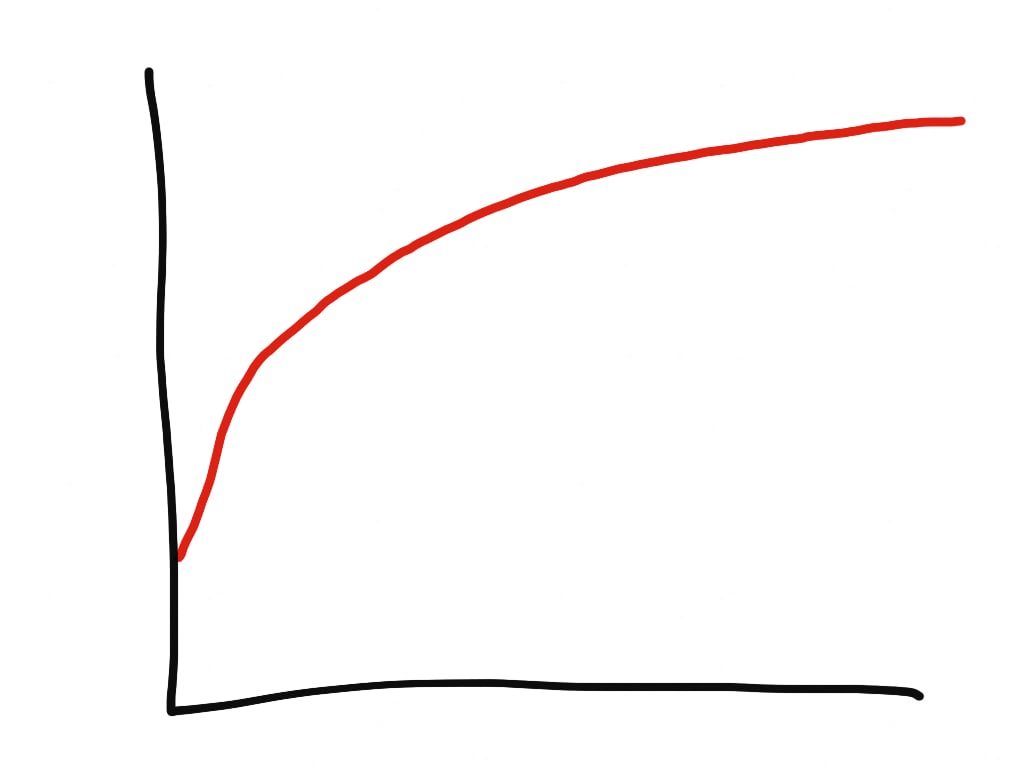
しかし、Rubyアプリの単体プロセスにおける実際のメモリ使用量を調べる方法は単純ではありません。PCやproduction環境でプロセス起動直後の個数を調べる方法では不十分です。理由はいろいろありますが、Ruby Webアプリのプロセスは時間とともにメモリ使用量が増加するからです。ときには生成後の2倍から3倍に達することもあります。Rubyアプリのプロセスで使われるメモリ使用量を正確に測定するには、プロセスの再起動(ワーカーキラー)を無効にしてから、12時間から24時間待ってからpsコマンドで測定します。Herokuユーザーなら、新しい[Heroku Exec]を使って実行中のdynoでpsを実行するか、単にHerokuのメモリ使用量の測定値を1 dynoあたりのプロセス数で割って求めます。多くのRubyアプリは1プロセスあたり200 MBから400 MBのメモリを使いますが、ときには1 GBに達することがあります。
Pumaのワーカーはしばらく経つと…かなり太ります。

メモリ使用量には必ず余裕を見ておいてください。何か子プロセス数を求める公式が欲しいのであれば、(TOTAL_RAM / (RAM_PER_PROCESS * 1.2))を目安にしてください。
レアキャラ「ドット絵DHH」が現れた!
5000デヴィッドに1度だけ出現し、一生使える適切なメモリ使用量を5秒かそこらで受け取る
1いいね = お祈り1回

サーバーやコンテナの上限メモリ量を超えると、メモリが限界に達してスワップが始まるため、速度が大きく低下します。アプリのメモリ使用量を予測可能かつスパイクのない平らな状態にしておきたい理由がこれです。メモリ使用量の急増は、私が「メモリ膨張」と呼んでいる条件です。この問題の解決はまたの機会に別記事で扱いますが、The Complete Guide to Rails Performanceでも扱っています。
次に、サーバーの利用可能なCPUキャパシティを超えないようにしたいと思います。理想的には、CPU使用率100%になる総割り当て時間の5%を超えないことです。これを超えている場合、利用可能なCPUキャパシティでボトルネックが発生していることを示します。多くのRuby on Railsアプリは、クラウドプロバイダのほとんどでメモリリソースがボトルネックになる傾向がありますが、CPUリソースもボトルネックを生じることがあります。どうやって検出すればよいでしょうか。それには、お好みのサーバー監視ツールが使えます。おそらくAWSのビルトインツールなら、CPU使用率が頻繁に上限に達してないかどうかのチェックは十分可能でしょう。
OSのコンテキストスイッチはコストが高いと言っとったじゃないか。productionで実際に使った結果を見ると、あんたがウソ言ってたってことだな。

「CPUの個数より多くの子プロセスを1サーバーに割り当てるべきではない」とよく言われます。その一部は本当ですし、出発点としては適切です。しかし実際のCPU使用率は、自分で監視と最適化を行うべき値です。実際には、多くのアプリのプロセス数は、利用できるハイパースレッド数の1.25〜1.5倍に落ち着くでしょう。
Herokuでは、ログに出力されたCPU負荷の測定値をlog-runtime-metricsで取得します。私は5分間〜15分間の平均負荷をチェックします。値が常に1に近かったり超えたりすることがあるようなら、CPU使用率を超えているので子プロセス数を減らす必要があります。
子プロセス数の設定はどのサーバーでも割りと簡単です。
# Puma
$ puma -w 3 # コマンドラインオプションの場合
workers 3 # config/puma.rbに書く場合
# Unicorn
worker_processes 3 # config/unicorn.rbに書く
# Passenger (nginx/Standalone)
# Passengerのワーカー数は自動で増減します: この設定はあまり便利とは思えなかったので
# 単にmaxとminを一定の数に設定しています。
passenger_max_pool_size 3;
passenger_min_instances 3;
数値を設定ファイルに書く代わりに、WEB_CONCURRENCYなどの環境変数に設定することもできます。
workers Integer(ENV["WEB_CONCURRENCY"] || 3)
まとめると、多くのアプリは使えるリソース量に応じて1サーバーあたり3〜8プロセスを割り当てます。メモリ制約の厳しいアプリや、95パーセンタイル時間(5〜10秒以上)のアプリなら、利用可能なハイパースレッド数の4倍までプロセス数を増やしてもよいでしょう。多くのアプリでは、子プロセスの数を、利用可能なハイパースレッド数の1.5倍を超えないようにすべきです。
スレッド数
PumaやPassenger Enterpriseはアプリでマルチスレッドをサポートするので、このセクションではこの2つのサーバーを対象にします。
スレッドは、アプリの並列性(ひいてはスループット)を軽量なリソースで改善する方法です。Railsは既にスレッドセーフであり、独自のスレッドを作るとかデータベース接続などの共有リソースにグローバル変数でアクセスする($redisのことだよ!)といった妙なことをするアプリはあまりありません。つまり、多くのRuby Webアプリはスレッドセーフということになります。本当にスレッドセーフかどうかを知るには、実際にやってみるしかありません。Rubyアプリのスレッドバグは例外のraiseという派手な方法で顕在化する傾向があるので、簡単に試して結果を見ることができます。
ではスレッド数はいくつにすべきでしょうか。並列性を追加して得られるスピードアップは、プログラムがどの程度並列に実行されるかに依存します。これはアムダールの法則として知られています。MRI(CRuby)の場合、IO待ち(データベースの結果待ちなど)だけが並列化可能です。これは多くのWebアプリでおそらく総時間の10〜25%を占めるでしょう。自分のアプリで、リクエストごとにデータベースで使われる総時間をチェックできます。残念なことに、アムダールの法則によれば、並列性の占める割合が小さい(50%未満)の場合、手頃なスレッド数をさらに増やすメリットはほとんど(あるいはまったく)ありません。そしてこのことは私の経験とも整合します。Noah GibbsもDiscourseホームページのベンチマークでこれをテストした結果、スレッド数は6に落ち着いたそうです。
アムダールの法則
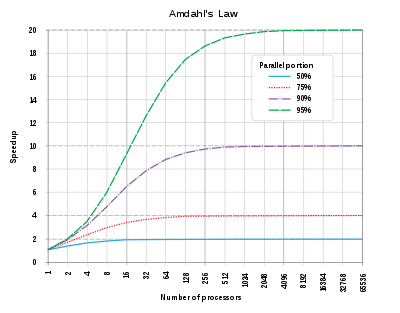
プロセス数の場合は現在の設定による測定値を定期的にチェックして適切にチェックすることをおすすめしますが、スレッド数の場合はそれとは異なり、アプリサーバーのプロセスごとのスレッド数を5に設定して「後は忘れる」でもたいてい大丈夫です。
「設定したら忘れよう」

MRI(CRuby)の場合、スレッド数はメモリに驚くほど大規模な影響を与えることがあります。これはホスト側に複雑な理由がいくつもあるためです(これについては今後別記事を書こうかと思います)。アプリのスレッド数を増やす場合、その前後でメモリ消費を必ずチェックしましょう。各スレッドがスタック空間で余分に消費するメモリが8 MBにとどまると期待しないことです。総メモリ使用量はしばしばこれよりずっと多くなります。
スレッド数の設定方法は次のとおりです。
# Puma: 繰り返しますが、私は「自動」スピンアップ/スピンダウン機能は本当に使わないので
# minとmaxには同じ値を設定しています
$ puma -t 5:5 # コマンドライン・オプション
threads 5, 5 # config/puma.rbに書く場合
# Passenger (nginx/Standalone)
passenger_concurrency_model thread;
passenger_thread_count 5;
JRubyをお使いの方へ: スレッドは完全に並列化されるので、アムダールの法則によるメリットをすべて得られます。JRubyでのスレッド数の設定は、上述したMRIでのプロセス数の設定にむしろ似ていて、メモリやCPUリソースを使い切るところまで増やせば済みます。
Copy-on-writeの振舞い
あらゆるUnixベースのOSではメモリの挙動にcopy-on-writeが実装されています。copy-on-writeはかなりシンプルです。プロセスがforkして子プロセスが作成された時点では、その子プロセスのメモリは親プロセスと完全に共有されます。しかしメモリに変更が生じるとコピーが作成され、その子プロセス専用のメモリになります。子プロセスは(理論的には)共有ライブラリやその他の「読み取り専用」メモリを(独自のコピーを作成する代わりに)親プロセスと共有できるようになっているべきなので、(copy-on-writeは)forkを繰り返すWebサーバーでメモリ使用量を減らすうえで大変役に立ちます。
copy-on-writeは、単に発生するものです5。copy-on-writeは「オフにできません」が、効率を高めます。基本的に私達がやりたいのは、forkの前にアプリをすべて読み込むことであり、多くのRuby Webサーバーでは「プリロード」と呼ばれています。copy-on-writeがあることで変わる点は、アプリが初期化される前と後でfork呼び出しが変わるだけです。
fork後、利用しているデータベースへの再接続も必要です。ActiveRecordの例を以下に示します。
# Puma
preload_app!
on_worker_boot do
# Rails 4.1で`config/database.yml`を使って`pool`サイズを設定するのは有効
ActiveRecord::Base.establish_connection
end
# Unicorn
preload_app true
after_fork do |server, worker|
ActiveRecord::Base.establish_connection
end
# Passengerはデフォルトでプリロードを行うのでオンにする必要はない
# Passengerは自動でActiveRecordへの接続を確立するが、
# 他のDBの場合は以下を行わなければならない
PhusionPassenger.on_event(:starting_worker_process) do |forked|
if forked
reestablish_connection_to_database # DBによって異なる
end
end
理論上は、アプリで使われるすべてのデータベースに対してこれを行わなければなりません。しかし実際には、Sidekiqは実際に何か行うまでRedisへの接続を試行しないので、アプリ起動時にSidekiqジョブを実行しているのでなければ、fork後に再接続する必要はありません。
残念なことに、copy-on-writeのメリットには限りがあります。透過的で巨大なページでは、メモリが1ビット変更されただけでも2 MBものページ全体がコピーされますし、メモリ断片化によっても上限が生じます。しかしそれで問題が生じるわけではないので、プリロードはとにかくオンにしておきましょう。
コンテナのサイズ
もっとメモリよこせや(゚Д゚)ゴルァ!!

一般に、サーバーで利用可能なCPUやメモリの利用率は70〜80%ぐらいにとどめておきたいものです。こうしたニーズはアプリによって異なりますし、CPUコア数とメモリのGB数の比率によっても変わります。あるアプリでは、4 vCPU/4 GB RAMのサーバーでRubyプロセスが6つ動くのがもっとも良好かもしれませんし、メモリ要求がより少なくCPU負荷のより高いアプリなら8 vCPU/2GB RAMがよいかもしれません。コンテナのサイズに完全なものはありませんので、CPUとメモリの比率は実際のproductionでの測定値に基いて選択すべきです。
Rails(有名なWebフレームワーク)とHeroku(RAM 512MB)、どっちが勝つか

サーバーで利用可能な総メモリ容量は、チューニング可能なリソースのうちでおそらく非常に重要なものです。多くのプロバイダは極めて低い値が採用されており、Herokuの標準的なdynoでは512 MBとなっています。Rubyアプリ、特に複雑かつ成熟したアプリは多くのメモリを要求するので、与えるべき総メモリ容量はおそらく非常に重要なリソースでしょう。
多くのRailsアプリで使われるRAMは300 MB以下なので、1サーバーあたり3プロセス以上を常に実行しているとすれば、多くのRailsアプリのRAMは少なくとも1 GBになるでしょう。
サーバーのCPUリソースも同じくチューニング可能な設定として重要です。利用可能なCPUコア数を知る必要がありますし、同時に実行可能なスレッド数も知る必要があります(そもそもサーバーでハイパースレッディングをサポートしているかどうかも知る必要があります)。
子プロセス数のところで解説したように、コンテナは少なくとも子プロセスを3つ以上サポートすべきです。1サーバー(またはコンテナ)あたり8プロセス以上にできればさらに改善されるでしょう。1コンテナあたりのプロセス数を増やせば、リクエストのルーティング改善やレイテンシの逓減に効果を発揮します。
まとめ
Ruby Webアプリサーバーのスループットを最大化する方法の概要を以下にまとめました。短いリスト形式になっているので、以下の手順に沿って進められます。
- スレッド数5のワーカー1つが使うメモリ容量を特定する。Unicornをお使いの場合は、明らかにスレッドは不要です。production環境の単一サーバー上でいくつかのワーカーを実行して少なくとも12時間は再起動せずに動かし続けてから、典型的なワーカーのメモリ容量を
psで調べます。 -
コンテナサイズの値は、上のメモリ容量の少なくとも3倍以上にする。多くのRailsアプリでは1ワーカーあたり最大300 MB〜400 MBのRAMを使いますので、多くのRailsアプリは1コンテナ(サーバー)あたり 1 GB必要になります。これによって、1サーバーあたり3プロセスを実行する余裕のあるメモリ容量になります。実行できる子プロセス数は、
(TOTAL_RAM / (RAM_PER_PROCESS * 1.2))に等しくなります。 -
CPUコア/ハイパースレッド数をチェックする。コンテナのハイパースレッド数(AWSの場合はvCPU)が、メモリがサポート可能な数より少ない場合は、メモリが少なくCPUが多いコンテナに適したコンテナサイズを選択します。実行すべき子プロセス数は、ハイパースレッド数の1.25倍〜1.5倍が理想です。
-
デプロイ後にCPUとメモリの消費を監視する。使用量を最大化するのに適切な子プロセス数とコンテナサイズを調整します。
関連記事
https://techracho.bpsinc.jp/hachi8833/2017_06_15/41465
-
3つのアプリサーバーで子プロセスを作成する
masterプロセスは、いずれも実際にはリクエストを処理しません。Passengerでforkが最近実行されていない場合、実際にはしばらくしてからmasterのプリロード処理を終了します。 ↩ - JRubyの人なら次のセクションをスキップしてもよいでしょう。 ↩
- これはCRubyのGlobal VM Lock(GVL)が原因です。Rubyコードを実行できるのは1度に1つのスレッドに限られるので、Rubyの並行処理を達成するにはプロセスを複数実行する以外に方法はありません。私たちは、サーバーのリソースを超えないようにしながら、サーバーあたりのプロセス数をできるだけ多く実行したいのです。 ↩
- 私はPassengerの「least-busy-process-first」ルーティングが実は大好きです。 ↩
- メモリをもっと効果的に節約するためにcopy-on-writeをさらに「サポートする」といったことはできません。 ↩ ↩