
- #1: 基本となる8つの正規表現
- #2: 正規表現とは何か/ワイルドカードとの違い
- #3: 冒頭/末尾にマッチするメタ文字とセキュリティ、文字セットの否定と範囲
- #4: 先読みと後読みを極める
- #5(特別編)
|と部分マッチのワナ - #6: 文字セットのショートハンド(本記事)
主にRubyを中心としながらも、なるべく一般的な形で正規表現を解説しています。誤りやお気づきの点がありましたら@hachi8833までどうぞ 。
。
![⚓]() 文字セットの「ショートハンド」とは
文字セットの「ショートハンド」とは

本連載の#3 よく使われる文字範囲で、文字セット(文字クラス)を範囲で表現する方法をいくつかご紹介しました。
- 例: /
[a-zA-Z0-9]/(Rubular)
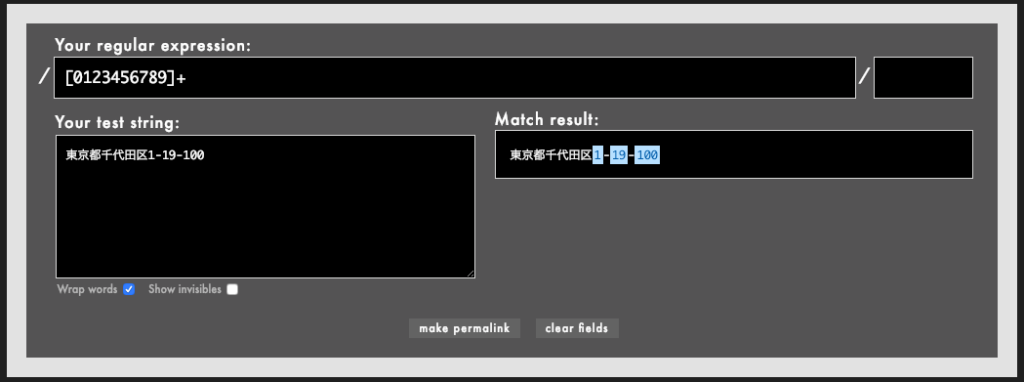
上の/[a-zA-Z0-9]/は、「英小文字」「英大文字」「数字」を表す文字セット範囲です。
異論もあるかと思いますが、私としては原則として上のように省略なしの文字セット範囲で記述することをおすすめしたいと思います。もちろん、使い捨ての正規表現であればそこまで丁寧にやる必要はありません。
理由は、ショートハンドの挙動が実装によって細かく異なっている可能性があるためです。すべてのライブラリをみっちり調べたわけではありませんが、ショートハンドは正規表現ライブラリごとのばらつきが比較的多いと感じています。
私は同じ正規表現を複数の正規表現ライブラリで動かすことが多いので、ショートハンドを当てにしてハマるのを避けるため、よほど有用なもの以外は省略なしの文字セット列挙を使う癖がついています。
とはいうものの、忙しい人は以下にご紹介するショートハンドをよく使っているようです。まずはバックスラッシュ\で始まるショートハンドを最小限ご紹介します。
![⚓]() ショートハンド:
ショートハンド: \b
\b- 単語の境界にマッチする(スペース区切り言語が対象の場合)
\bは有能なショートハンドです。たとえば\bair\bは「air」という単語にマッチします。単語の直前や直後がスペースでなくても、たとえば行頭、行末、記号、数値であっても単語の境界と認識してくれます。
仮に\bを雑に先読みで表すと(?=[ !"#$%&'()*,\-.\/:;<>?@\[\\\]\^```{|}~])、後読みで表すと(?<=[ !"#$%&'()*,\-.\/:;<>?@\[\\\]\^```{|}~])と表した感じです(WordPressのシンタックスハイライトが崩壊しそう )。
)。
こんなに長い正規表現を短く\bで表せるのですから、有用性の高いショートハンドと言えます。
\bの例
- 例: モビルスーツ(ジオン公国軍、U.C.0079 – 0080)の型番にマッチする正規表現:
\b(YMS-07B|MAN-(0[378]|X[38])|MAM-07|MSN-[0X]2|MAX-03|MSM-(07S|04F|0[347]|10)|YMS-1[45][AS]?|MS-(0[5679][BFJRS]?|1[14][AS]?)|MS-X1[06]|MS-R09|MA-(0[58]|04X|05H))\b)(Rubular)
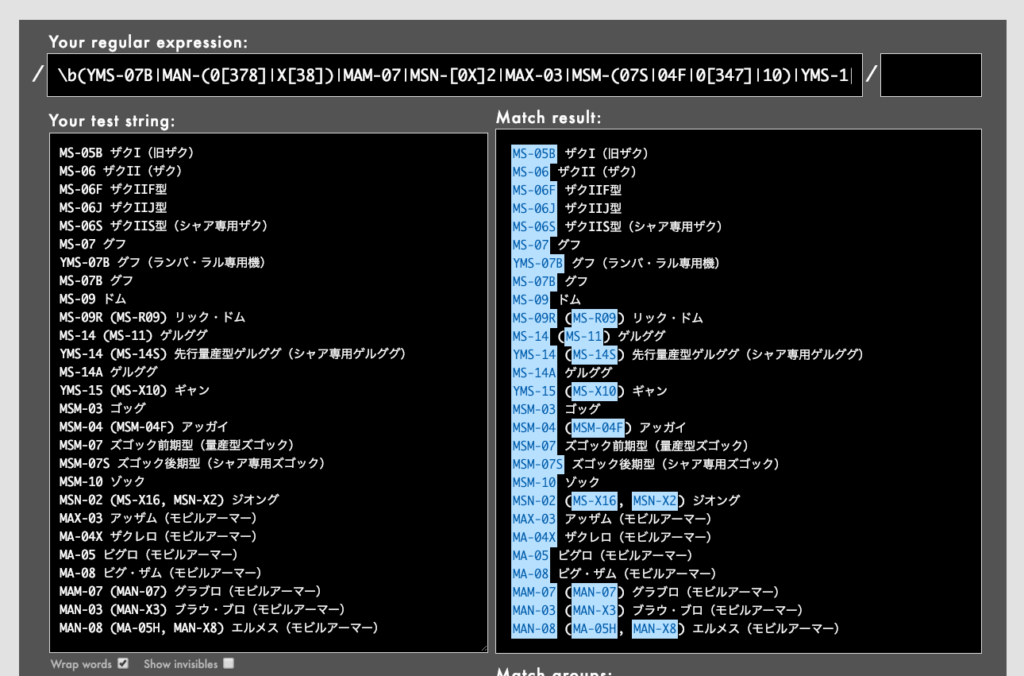
急に正規表現が長くなって恐縮ですが、冒頭と末尾に\bが置かれていることにご注目ください。これによって、かっこ()や文頭文末や記号を超えることなく、単語の境界を指定できます。
このモビルスーツ型番マッチ用の正規表現は今後もサンプルに使おうと思います。
\bの注意
- ここで言う単語は、英語を含むアルファベット語圏における「スペース区切り」の文字列が原則として対象となります。スペース区切りでない日本語では基本的に無力です。
-
\bは文字そのものにはマッチしない点にご注意ください。#4 先読みと後読みと同じく、文字ではなく位置を指定するショートハンドです。 -
「スペース」「記号」があると、そこが単語の境界と認識されます。文字列の「冒頭」や「末尾」、そして「改行」や「タブ」も境界と認識されます。
-
ただし、英文字に接している「数字」や「アンダースコア」は境界と認識されません。
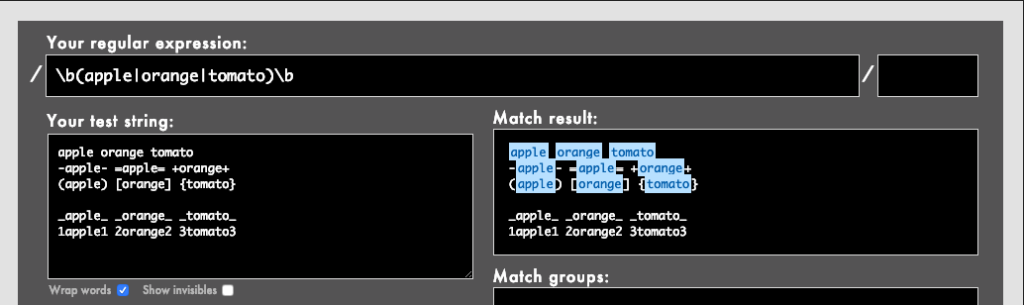
- 例: /
\b(apple|orange|tomato)\b/(Rubular)
- 例: /
- 特に注意: 少なくとも「非アルファベット文字」や「全角記号」は、実装によって境界扱いされるかどうかが異なることがあります↓。
例: \bMS\bの挙動がライブラリで異なる(Rubular)(Regex101)
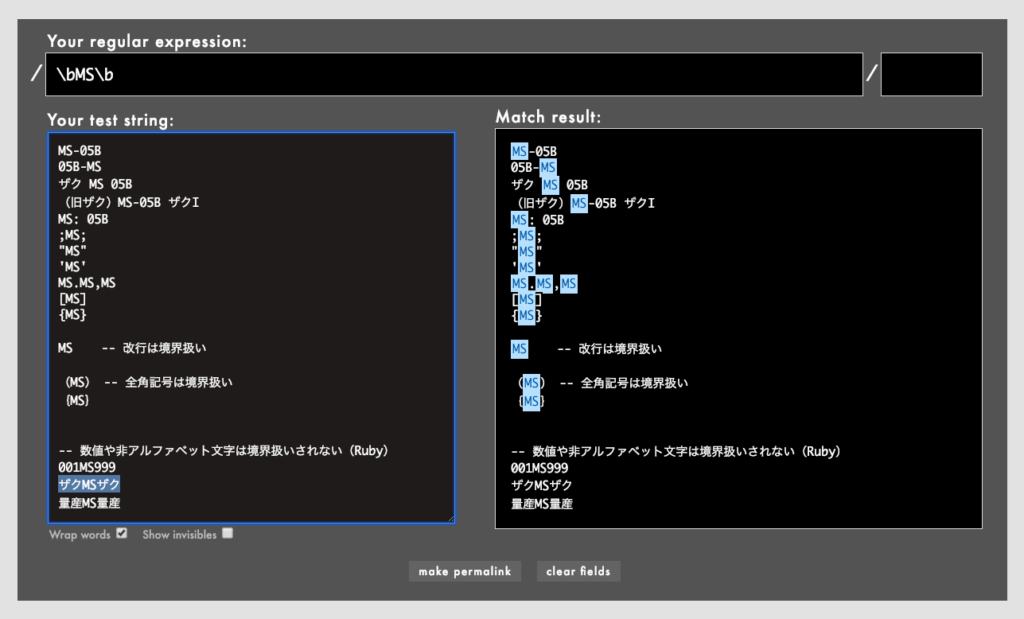
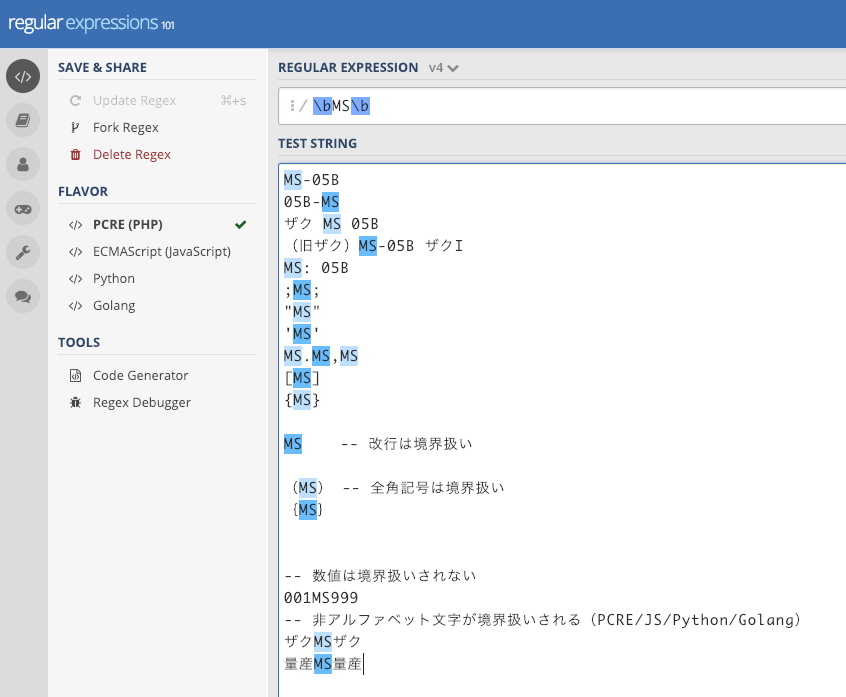
「ザクMSザク」「量産MS量産」とマッチするかどうかが、Ruby 2.5.3とそれ以外(PCRE/JS/Python/Golang)で違っていることがおわかりかと思います。怖いですね 。
。
![⚓]() ショートハンド:
ショートハンド: \d
\d[0123456789]と同等
\dというショートハンドを使うと、[0123456789]を簡潔に表記できます。dは「digitの最初の文字」なのでしょう。
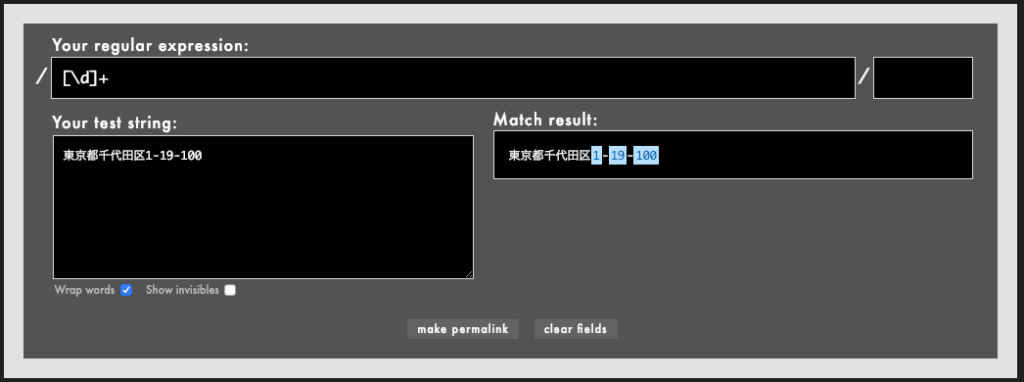
なお、私の書き方では[\d]のようになっていることにお気づきでしょうか。
多くの正規表現ライブラリでは\dと書くだけで使えるのですが、私は次の理由から[\d]のようにあえて文字セット[ ]に入れるようにしています。
\で始まるショートハンドは、正規表現の中で視覚的に埋もれやすいと感じる\dが文字セットであることを意識したい[\d]とすることで\dが文字セットであることを明示できる[\dぁ-ん]などのように、後から文字セットを自然に追加できる
実際の私は、[\d]すら使わず、[0-9]と明示的に書いています。長さ的にほとんど変わりませんし、視覚的に捉えやすいので。
我ながら少々潔癖とも言えますので、皆さんは無理にそうしなくても構いませんが、思うところのある方は参考にしていただければと思います。
![⚓]() ショートハンド
ショートハンド\w
\w- 任意の単語(1文字)にマッチ
\wは単独で使うことはまずありません(単独だとaのような1文字の単語にしかマッチできないので)。\w+のように量指定子を加えて使うのが普通です。
\bだと単語の前後に置かなければなりませんので、任意の単語1つを表そうとすると\b[a-zA-Z]+?\bとなりますが、\w+?ならさらに簡潔です。もちろん、英語を含むアルファベット圏のテキストが前提である点は\bと同じです。
![⚓]()
\wの注意
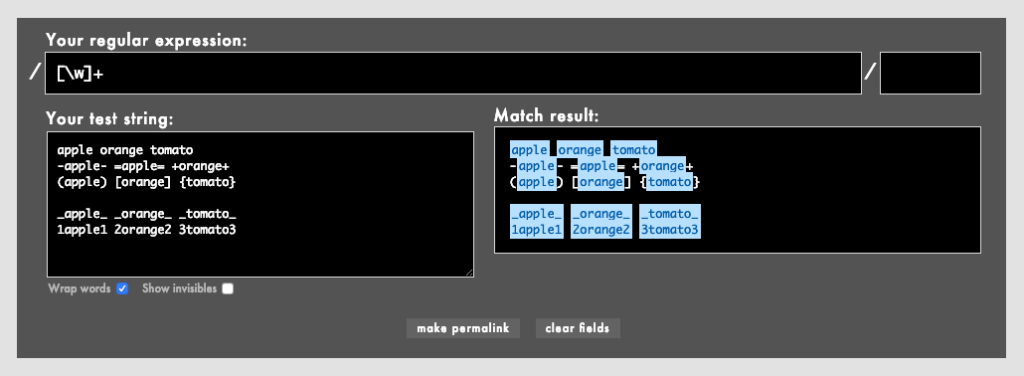
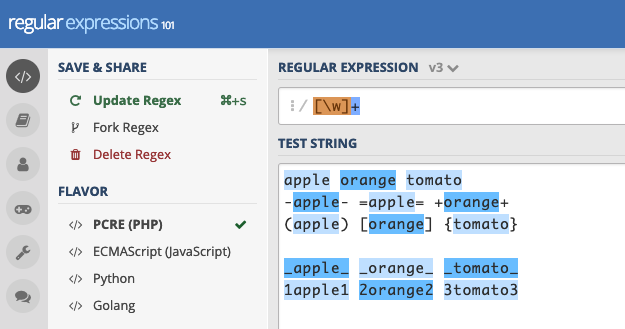
_apple_や1apple1全体にマッチしているのがおわかりかと思います。
![⚓]() 他のショートハンドは?
他のショートハンドは?
ここでは\dや\bや\w以外を紹介しません。その理由は、前述のとおり、これら以外のショートハンド表記は他にもライブラリによる違いを含む可能性があるのと、量が多すぎるためです。
この3つは比較的どのライブラリでもまあまあ共通に使えます。それでも\bは挙動が違っていましたね。
それ以外にもその場で思いつきで実装されたようなショートハンドはライブラリごとに山ほどありますので、各自でググってください。
参考: Regular Expressions Quick Reference — さまざまなライブラリのショートハンドや拡張書式を一望に見渡せるスグレモノのページです。
regular-expressions.infoより

![⚓]() 別のショートハンド:
別のショートハンド: [: :]や[[: :]]など
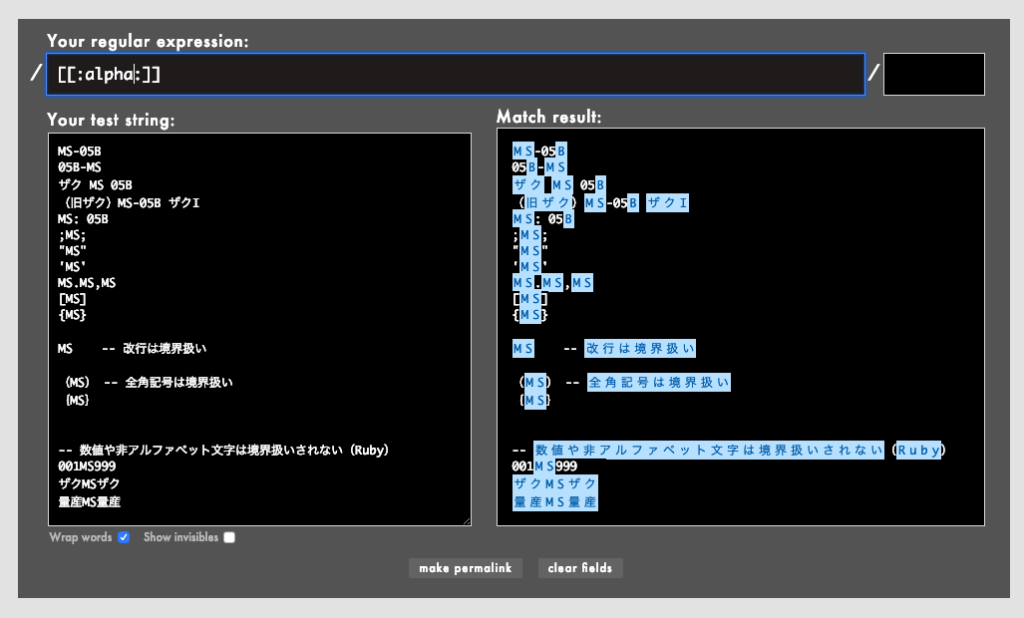
[: :]や[[: :]]はPOSIX風の記述ですが、個人的には普遍性が低いと思うので正直おすすめしません。単に私が怖がりなのかもしれませんが、Unicode UTF-8の対応にも疑問が残ります。
少なくとも[[:alpha:]]や[[:alnum:]]は、Rubyでは漢字やひらがなにもマッチしてしまうことは覚えておきましょう。しかも、PCRE(PHP)、Golangでは漢字やひらがなにマッチしませんし、PythonやJavaScriptではそもそも[[: :]]表記が使えません(regex101)。
- 例: /
[[:alpha:]]/(Rubular)
ショートハンドは、他にも\g<-1>のような書式や、(?(?=regex)then|else)などのように(?なんちゃら)と書く拡張機能なども含めると本当にきりがありません。
- #1: 基本となる8つの正規表現
- #2: 正規表現とは何か/ワイルドカードとの違い
- #3: 冒頭/末尾にマッチするメタ文字とセキュリティ、文字セットの否定と範囲
- #4: 先読みと後読みを極める
- #5(特別編)
|と部分マッチのワナ - #6: 文字セットのショートハンド(本記事)