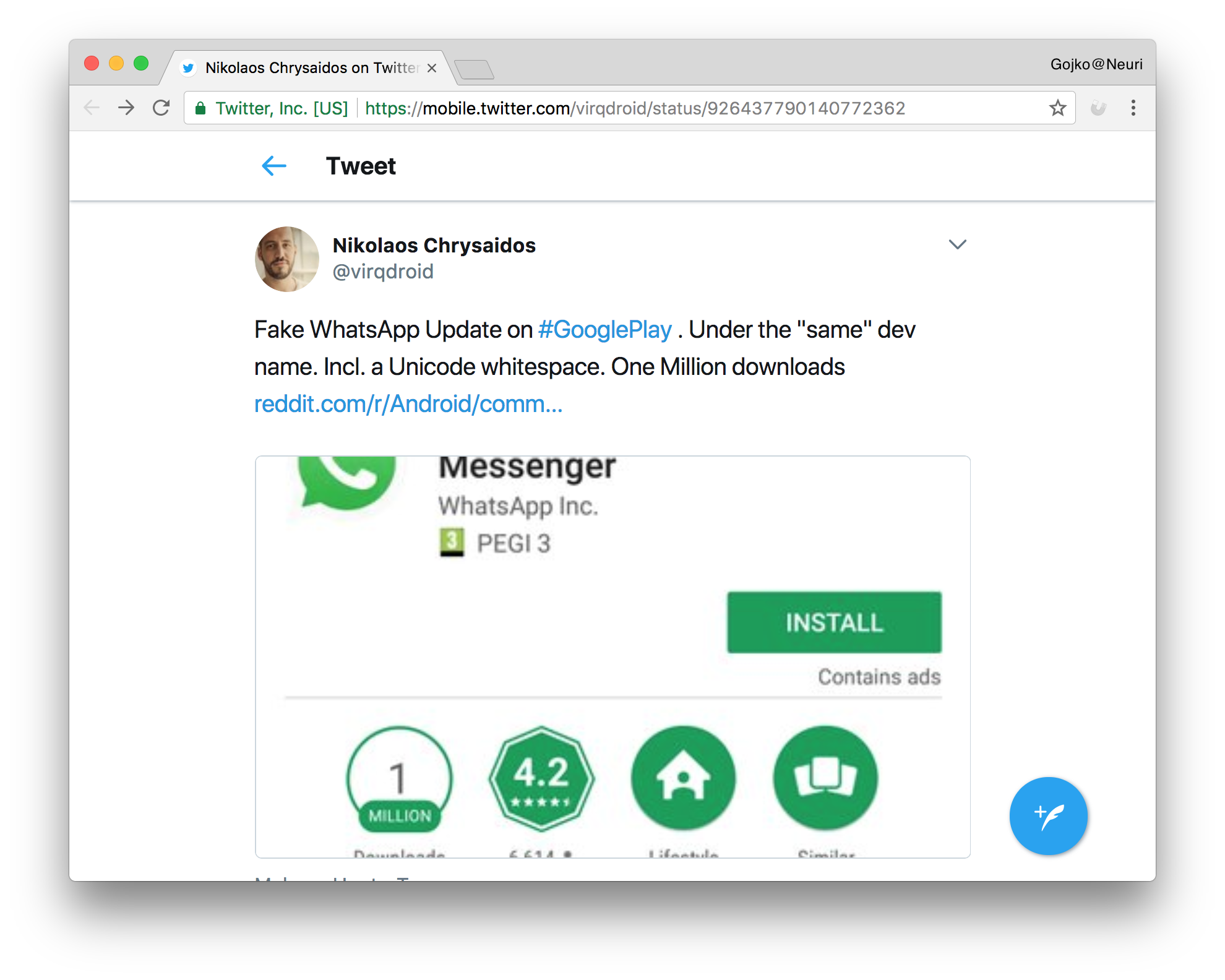
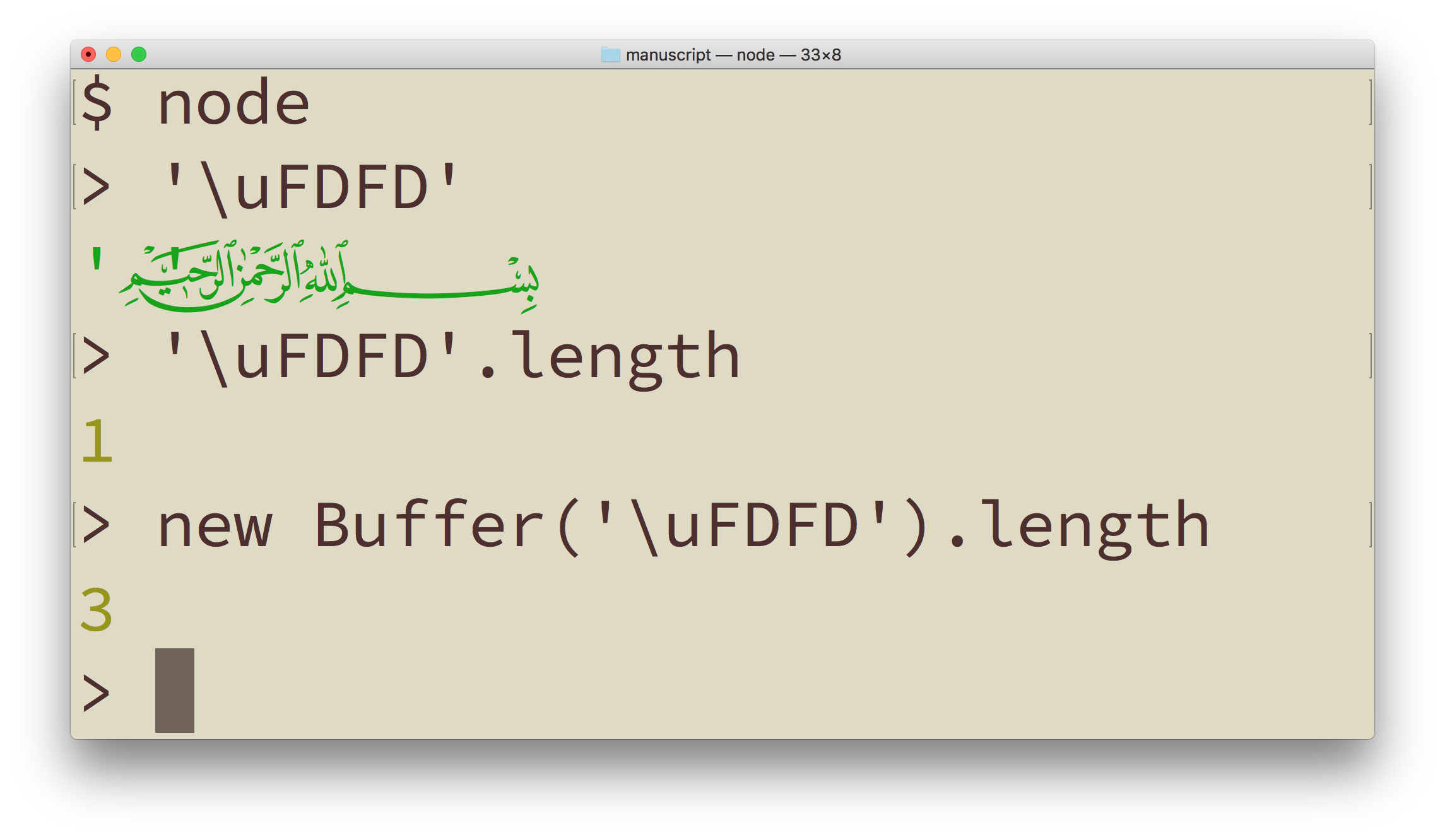
こんにちは、hachi8833です。先週は文化の日でウォッチをお休みいたしました。
11月最初のウォッチ、いってみましょう。
RubyWorld Conference 2017無事終了
2017.rubyworld-conf.orgより

今年も盛り上がったようです。皆様お疲れさまでした。
https://t.co/OjRtmuJenC RWC 2017のtogetter、分量がすごい。#rubyworld
— sho-h (@sho_hashimoto) November 6, 2017
つっつきボイス: 「今年は残念ながら行けなかったんで、松江の馴染みのおでん屋食べられなかった(´・ω・`)」「今回はクックパッドの発表がいつもより多かったみたいでした」
Rails: 今週の改修
改良: beforeSendを付けずにRails.ajaxを呼び出せるようになった
// actionview/app/assets/javascripts/rails-ujs/utils/ajax.coffee
- unless options.beforeSend?(xhr, options)
+ if options.beforeSend? && !options.beforeSend(xhr, options)
// 変更前
Rails.ajax({
type: 'get',
url: '/',
beforeSend: function() {
return true
},
success: function() {
// do something
}
// 変更後
Rails.ajax({
type: 'get',
url: '/',
success: function() {
// do something
}
つっつきボイス: 「以前は使わないときにもbeforeSend:書かないといけなかったのか」
改善: rescue画面でソースが改行されないようになった

つっつきボイス: 「行数表示と実際の行が一致するようになったのね」「エディタではワードラップする方が好きなんですが、英語圏だとエディタをワードラップしない人が割りと多い気がします」
Railsから非推奨コードを削除
以下の非推奨コードが削除されました。
- erubis: 今後はerubiになります。
- evented Redisアダプタ
- ActiveRecordの以下を削除
#sanitize_conditions#scope_chain.error_on_ignored_order_or_limit設定#verify!の引数#indexesのname引数ActiveRecord::Migrator.schema_migrations_table_namesupports_primary_key?supports_migrations?initialize_schema_migrations_tableとinitialize_internal_metadata_table- dirty recordへの
lock!呼び出し - 関連付けでクラスに
:class_nameを渡す機能 index_name_exists?のdefault引数- ActiveRecordオブジェクトの型変換時の
quoted_idサポート
- ActiveSupportの以下を削除
halt_callback_chains_on_return_false- コールバック用文字列フィルタの
:ifと:unlessオプション
改良: ActionDispatch::SystemTestCaseにフックを追加
y-yagiさんです。
# actionpack/lib/action_dispatch/system_test_case.rb
+
+ ActiveSupport.run_load_hooks(:action_dispatch_system_test_case, self)
#redirect_backにallow_other_hostを追加
# actionpack/lib/action_controller/metal/redirecting.rb
- def redirect_back(fallback_location:, **args)
- if referer = request.headers["Referer"]
- redirect_to referer, **args
else
- redirect_to fallback_location, **args
- end
+ def redirect_back(fallback_location:, allow_other_host: true, **args)
+ referer = request.headers["Referer"]
+ redirect_to_referer = referer && (allow_other_host || _url_host_allowed?(referer))
+ redirect_to redirect_to_referer ? referer : fallback_location, **args
end
つっつきボイス: 「redirect_backはリファラを見て前画面に戻るやつですね」「前は他のサイトに戻れないよう設定できなかったのか」
Rails
dry-rbでRailsにForm Objectを作る

cucumbersome.netより
# 同記事より
PostcardSchema = Dry::Validation.Schema do
required(:address).filled
required(:city).filled
required(:zip_code).filled
required(:content).filled
required(:country).filled
end
つっつきボイス: 「実は今、dry-rbシリーズにどんなgemがあるのかざっくりチェックする記事を準備しているんですが、そのきっかけは同じ作者の@solnicさん(Ruby Prize 2017受賞者)のvirtusのReadmeで以下の記述を見たことでした: よく見たらもう何年も更新されてなくて、最新Rubyでの動作も確認されてないみたいなので」
さらなる進化へ
Virtusを作ったことで、Rubyにおけるデータの扱い、中でもcoercion/型安全/バリデーションについて多くのことを学べました。このプロジェクトは成功を収めて多くの人々が役立ててくれましたが、私はさらによいものを作ることを決心しました。その結果、dry-types、dry-struct、dry-validationが誕生しました。これらのプロジェクトはVirtusの後継者と考えるべきであり、考慮点やより優れた機能がさらにうまく分割されています。Virtusが解決しようとした同種の現代的な問題について関心がおありの方は、ぜひdryシリーズのプロジェクトもチェックしてみてください。@solnic
https://github.com/solnic/virtus より抄訳
「なるほど、virtusはとってもいいgemだけど今後はdry-rb系gemがメンテされそう: 次にFormObject作るときはこれ参考にしよう」
「dry-validationはActiveRecordのバリデーション+strong parametersより数倍速いと謳ってますね」「でも本家のバリデーションはRailsの記法にマッチしているからそっちを使いたい」
Service Objectにちょっとうんざり(Awesome Rubyより)
avdi.codesより

# 同記事より
module Perkolator
def self.process_ipn(params:, redemption_url_template:, email_options:)
# ...
end
end
post "/ipn" do
demand_basic_auth
redemption_url_template =
Addressable::Template.new("#{request.base_url}/redeem?token={token}")
Perkolator.process_ipn(
params: params,
redemption_url_template: redemption_url_template,
email_options: settings.email_options)
# Report success
[202, "Accepted"]
end
つっつきボイス: 「Service Objectにクラスメソッドを実装する的な話か」
「Service Objectのメソッドをインスタンスメソッドとして実装するかどうかはケースバイケースなんだけど、一度クラスメソッドとして実装してしまうと後からインスタンスメソッド化するのがものすごく面倒になるのが特に厄介」
「クラスメソッドにしてしまってマルチスレッドが効かなくなるとか、あるあるですな」
「自分の場合、形はクラスメソッドだけど内部でself.newして事実上インスタンスメソッドにすることある」
ほぼほぼすべてのプロジェクトで使う25のgem(RubyFlowより)
hackernoon.comより

つっつきボイス: 「これまでRailsウォッチでいろんなgemを取り上げてきたせいか、初めて見るgemがほとんどありませんでした: それだけ定番ってことですね」「こうやって何度も見ていると、もう見ただけで機能を思い出すようになってくる」
「そうそう、ところでmoney-railsの#monetizeってメソッド、これが言いたくて作ったとしか思えない」「『誰がうまいこと言えと』的なやつですね」
class Product < ActiveRecord::Base
monetize :price_cents
end
RailsでPostgreSQLのパーティショニングを使ってみる(RubyFlowより)
evilmartians.comより

# 同記事より
CREATE OR REPLACE FUNCTION orders_partitioned_view_insert_trigger_procedure() RETURNS TRIGGER AS $BODY$
DECLARE
partition TEXT;
partition_country TEXT;
partition_date TIMESTAMP;
BEGIN
...
つっつきボイス: 「もうパーティショニングどうこうというより、PostgreSQLの機能がそもそも凄すぎてそっちに驚く」「『こんな機能があったのか』みたいなのが次から次に出てくるし」
「記事タイトルはCommand & Conquerのもじりかな」「あー、ゲームネタなのか(ゲーム音痴なので)」
⭐rails-sqli.org: RailsのSQLインジェクション手法を一覧できるサイト⭐
rails-sqli.orgより

今気づきましたが、Rails 5、Rails 4、Rails 3それぞれでSQLインジェクション手法をどっさり紹介しています。
# pluckを使ったインジェクション
params[:column] = "password FROM users--"
Order.pluck(params[:column])
Query
SELECT password FROM users-- FROM "orders"
Result
["Bobpass", "Jimpass", "Sarahpass", "Tinapass", "Tonypass", "supersecretpass"]
つっつきボイス: 「おお、これ( ・∀・)イイ!!: チェックに使える」「いろんなインジェクションがあるんだなー」「何にしろparamsに入力を直接突っ込む時点でアウトですな」「翻訳したい気もするけど翻訳するところがないw」「見ればわかりますからねー」
今週の⭐を進呈いたします。おめでとうございます。
barbeque: Dockerでジョブを実行する、クックパッド製ジョブキューgem
- リポジトリ: cookpad/barbeque
barbeque、その他の会社でも多く利用していただきたい
— k0kubun (@k0kubun) November 2, 2017
RubyWorld Conference 2017でも言及されていたようです。
つっつきボイス: 「クックパッドは多分ここ最近マイクロサービス化を進めているので、その中でバッチジョブもdocker containerの実行にすればより分散しやすくなるということかな」「Aaron Pattersonさんのインタビュー↓でもGitHubがマイクロサービス化を進めているという話がありましたね」「分散しないとRailsアプリ本体の起動が死ぬほど遅くなる」
RailsでのStripe.com決済処理をRSpecでテストする(RubyFlowより)
hackernoon.comより
# 同記事より
require 'rails_helper'
include ActiveJob::TestHelper
RSpec.describe Payments::InvoicePaymentSucceeded, type: :mailer do
let(:plan) { @stripe_test_helper.create_plan(id: 'free', amount: 0) }
before(:each) do
@admin = FactoryGirl.create(:user, email: 'awesome@dabomb.com')
PaymentServices::Stripe::Subscription::CreationService.(
user: @admin,
account: @admin.account,
plan: plan.id
)
@event = StripeMock.mock_webhook_event(
'invoice.payment_succeeded',
customer: @admin.account.subscription.stripe_customer_id,
subscription: @admin.account.subscription.stripe_subscription_id
)
end
it 'job is created' do
ActiveJob::Base.queue_adapter = :test
expect do
Payments::InvoicePaymentSucceeded.email(@event.id).deliver_later
end.to have_enqueued_job.on_queue('mailers')
end
it 'email is sent' do
expect do
perform_enqueued_jobs do
Payments::InvoicePaymentSucceeded.email(@event.id).deliver_later
end
end.to change { ActionMailer::Base.deliveries.size }.by(1)
end
つっつきボイス: 「Stripeは有名な決済サイトですね: こういうところにはテスト用のサンドボックス的環境が用意されているのが普通」
「そういえばPayPalのサンドボックスはよくできてるんですが、惜しいことにドキュメントがものすごく読みづらい」「私も以前試したけど結局よくわからんかった」
stripe.comより
Fat Free CRM: Railsで作られたOSSカスタマーリレーション管理(Awesome Rubyより)
- リポジトリ: fatfreecrm/fat_free_crm
- サイト: http://www.fatfreecrm.com/
- お試し: http://demo.fatfreecrm.com/(id: aaron、pw: aaronでログイン)

www.fatfreecrm.comより
つっつきボイス: 「日本でこれをカスタマイズして使うのは考えにくいけど、ソースコードが結構きれいでよく書けている感じなので、実際に業務で動くアプリとしてソース読むとかテストコードの書き方や設計を学ぶのにいいかも」
「あまり大きくなさそうだし、git cloneしてIDEでじっくり読んでみようかな」「RedmineやGitLabだと巨大すぎて追うのが大変ですからね」「Rails 5.0.4か」

github.com/fatfreecrm/fat_free_crmより
flipper: 特定の機能を動的にオン/オフ/状態確認できるgem(RubyFlowより)
- 元記事: Flippin’ Features at Runtime
- リポジトリ: jnunemaker/flipper
# github.com/jnunemaker/flipperより
require 'flipper'
require 'flipper/adapters/memory'
Flipper.configure do |config|
config.default do
# pick an adapter, this uses memory, any will do
adapter = Flipper::Adapters::Memory.new
# pass adapter to handy DSL instance
Flipper.new(adapter)
end
end
# 検索が有効かどうかをチェック
if Flipper.enabled?(:search)
puts 'Search away!'
else
puts 'No search for you!'
end
puts 'Enabling Search...'
Flipper.enable(:search)
# 検索が有効かどうかをチェック
if Flipper.enabled?(:search)
puts 'Search away!'
else
puts 'No search for you!'
end
有料版のFlipper::Cloudもあるようです。
- サイト: featureflipper.com

つっつきボイス: 「クックパッドのchanko gemみたいなやつかな」
cookpad.github.io/chankoより

「ところで、flipperがなぜイルカなのかわかります?」「わかんね」「わかんね」「Officeイルカじゃなさそうだけど」「私が子供の頃『わんぱくフリッパー』っていう米国制作の番組が放映されてたんです(年即バレ)」
モデルになったとされるイルカは、不機嫌になるとすぐ芸の道具を全部ひっくり返す癖があったのでflipperというあだ名になったというのを何かで読んだ覚えがあります。
年に1度だけ起きるバグ(RubyFlowより)

とても短い記事です。
# 同記事より
event = test_organizer.create_published_event(starts_at: 25.hours.from_now)
つっつきボイス: 「年1バグとか普通にあるけど、これはどういうやつかな?以前のウォッチで扱ったActiveSupport::Durationでもなさそうだし」「25?」「あーサマータイムか」「サマータイムがある国の開発者(´・ω・)カワイソス」
週刊Railsウォッチ(20170120)Ruby 2.5.0 devリリース、古いMySQLのサポート終了、uniqメソッドが削除ほか
「そういえば米国ではsummer timeではなくDSTって書きますね: 自分もsummertimeというとスタンダードナンバーを連想します」
ジュニア開発者へのRails設計アドバイス(Awesome Rubyより)
以下は見出しから。
- 純粋なRubyオブジェクトとデザインパターンを恐れず使うべし
- (暗黙的でない)明示的なコードにすべし
- アプリを水平分割すべし
- 機能以外の本当の要件を満たす設計を
- テストは徹底的に行うべし
- 継承よりコンポジションを優先すべし
- 制御フローを尊重すべし
つっつきボイス: 「うん、悪くなさそう: Railsに限らない話もいろいろある」「after_create/after_update/after_destroy/after_commitを避けろというのは大事: after_系フックを使うならちゃんと値を返すべきだし、自分自身を変えないこと」
reek: 「コードの匂い」を検出するgem(Awesome Rubyより)
- リポジトリ: troessner/reek
github.com/troessner/reekより

gem install reekしてオレオレRailsアプリにかけてみたらこんな感じで出ました。ドキュメントのURLも出力してくれます。Rubyに絆創膏。
app/controllers/patterns_controller.rb -- 12 warnings:
[41, 43]:DuplicateMethodCall: PatternsController#create calls 'format.html' 2 times [https://github.com/troessner/reek/blob/master/docs/Duplicate-Method-Call.md]
[80, 87]:DuplicateMethodCall: PatternsController#update calls '@pattern[:id]' 2 times [https://github.com/troessner/reek/blob/master/docs/Duplicate-Method-Call.md]
[80, 87]:DuplicateMethodCall: PatternsController#update calls 'edit_pattern_path(@pattern[:id])' 2 times [https://github.com/troessner/reek/blob/master/docs/Duplicate-Method-Call.md]
[80, 82]:DuplicateMethodCall: PatternsController#update calls 'format.html' 2 times [https://github.com/troessner/reek/blob/master/docs/Duplicate-Method-Call.md]
[7]:InstanceVariableAssumption: PatternsController assumes too much for instance variable '@pattern' [https://github.com/troessner/reek/blob/master/docs/Instance-Variable-Assumption.md]
[35]:TooManyStatements: PatternsController#create has approx 11 statements
...
つっつきボイス: 「rubocopのcopにして欲しいー: rubocopと他のツールのwarningを調整するの大変だし」
activerecord-import: 一括インポートgem+バリデーション(Awesome Rubyより)
# wikiより
columns = [ :title, :author ]
values = [ ['Book1', 'FooManChu'], ['Book2', 'Bob Jones'] ]
# Importing without model validations
Book.import columns, values, :validate => false
# Import with model validations
Book.import columns, values, :validate => true
# when not specified :validate defaults to true
Book.import columns, values
つっつきボイス: 「前にもウォッチで触れたことありましたが一応」「activerecord-importはbulk insert gemとしては使いやすくて有能なやつですね: バリデーションもやってくれるし」「お、ちょうど今の案件に使えそうダナ」
dckerize: RailsアプリのDockerイメージを作るgem(RubyFlowより)
- リポジトリ: pacuna/dckerize
# 同リポジトリより
$ rails new myapp --database=postgresql
$ cd myapp
$ dckerize up myapp
# DBファイルを設定
$ docker-compose build
$ docker-compose up
つっつきボイス: 「とりあえず動かしてみたんですが、PostgreSQLのコンテナのところでつっかえてしまいました」「うーん、PostgreSQL 9.5.3のバージョンべた書きだったり、/var/lib/postgresqlに直接つっこんだりしてるしなー: 自分専用なんじゃ?」「そんな感じですね: 自分でdocker-compose書くのがよさそう」「Dockerやったことない人がお試しに動かすきっかけにはなるかも」
Ruby trunkより
提案: Enumerator#next?
class Enumerator
def next?
peek
true
rescue StopIteration
false
end
end
a = [1,2,3]
e = a.to_enum
p e.next? #=> true
p e.next #=> 1
p e.next? #=> true
p e.next #=> 2
p e.next? #=> true
p e.next #=> 3
p e.next? #=> false
p e.next #raises StopIteration
つっつきボイス: 「へー、next?って今までなかったのか」「採用されるかどうかはmatz次第みたいです」
2つのArrayの間にカンマがないとnilになる => 仕様どおり(却下)
[2, 2][3, 3] # => nil
つっつきボイス: 「これ、仕様どおりですよね」「Stackoverflowレベルの内容をRubyバグに投げるのは勇者」
Ruby
RubyGems 2.7.0がリリース
RubyGems 2.7.0 Released: https://t.co/mF9JRK2s4l
— Ruby Inside (@RubyInside) November 3, 2017
今見たらもう2.7.2になっています。
- 2.7.0
- Update vendored bundler-1.16.0. Pull request #2051 by Samuel Giddins.
- Use Bundler for Gem.use_gemdeps. Pull request #1674 by Samuel Giddins.
- Add command signin to gem CLI. Pull request #1944 by Shiva Bhusal.
- Add Logout feature to CLI. Pull request #1938 by Shiva Bhusal.
- 2.7.1
- Fix gem update –system with RubyGems 2.7+. Pull request #2054 by Samuel Giddins.
- 2.7.2
- Added template files to vendoerd bundler. Pull request #2065 by SHIBATA Hiroshi.
- Added workaround for non-git environment. Pull request #2066 by SHIBATA Hiroshi.
#2065と#2066、ちょうど昨日踏んでしまいましたが、gem update --systemで即修正完了でした。
Ruby 2.5で速度が改善された点(RubyFlowより)
rubyguides.comより

- 式展開
String#prependEnumerableのメソッドRange#minとRange#maxString#scan
つっつきボイス: 「式展開の改善は目覚ましい」「他のは誤差っぽいかなー」「何にしろRuby 3×3に向けて着々と進んでいる感じですね」
Ruby3x3のオリジナルの読み方は「ruby three times three」だったのだが、発音しにくいので、最近は「ruby three by three」って読んでる。提唱元のAppFolioで雇用されてるNoah Gibbsもそう読んでるし、いいかな。
— Yukihiro Matsumoto (@yukihiro_matz) October 30, 2017
メモリを意識したRubyプログラミング
link: Memory Conscious Programming in Ruby – gettalong's web home: https://t.co/OXttukLDoK
— Yukihiro Matsumoto (@yukihiro_matz) October 31, 2017
gettalong.orgより

# 同記事より
2.4.2 > require 'objspace'
=> true
2.4.2 > ObjectSpace.memsize_of(nil)
=> 0
2.4.2 > ObjectSpace.memsize_of(true)
=> 0
2.4.2 > ObjectSpace.memsize_of(false)
=> 0
2.4.2 > ObjectSpace.memsize_of(2**62-1)
=> 0
2.4.2 > ObjectSpace.memsize_of(2**62)
=> 40
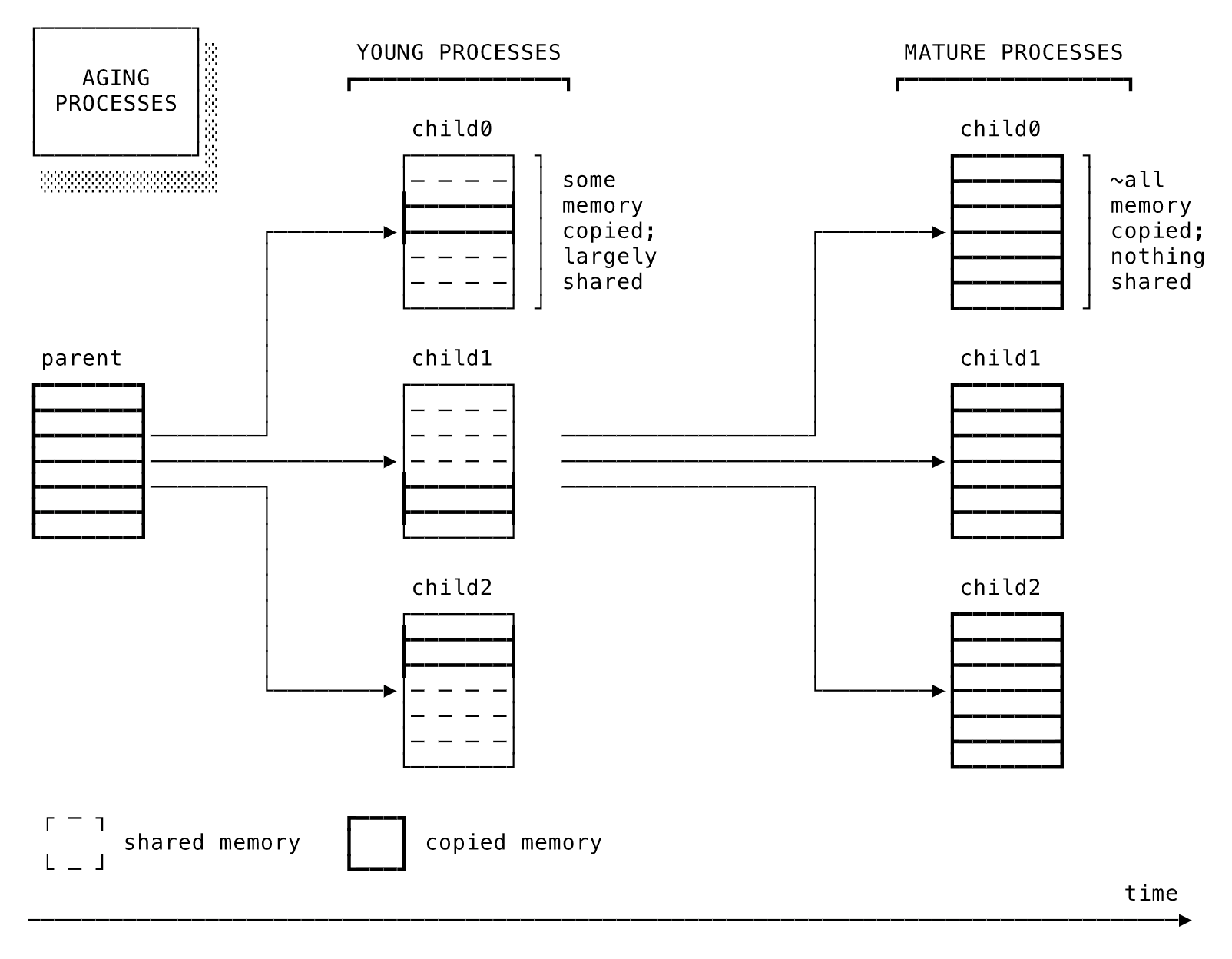
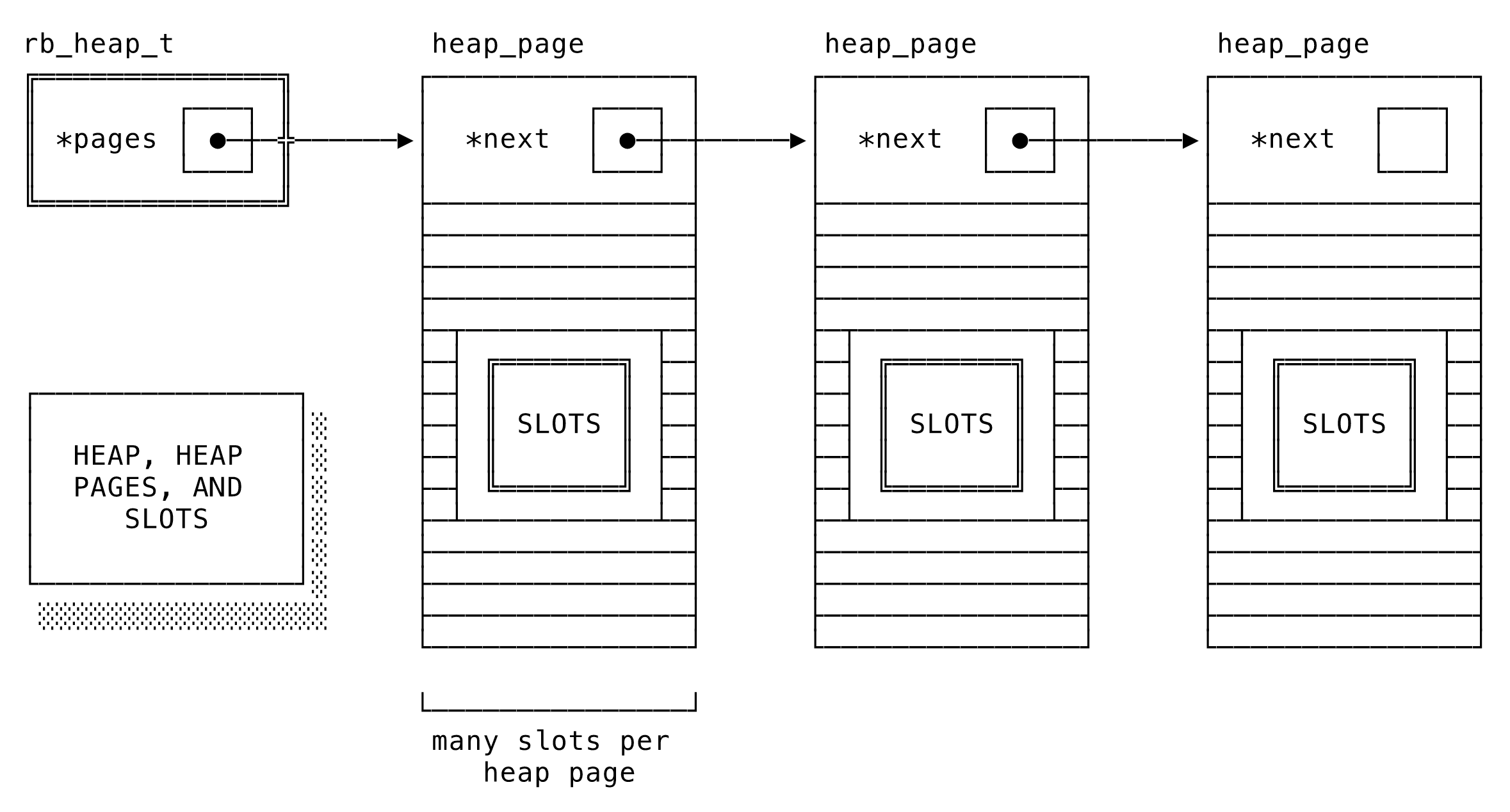
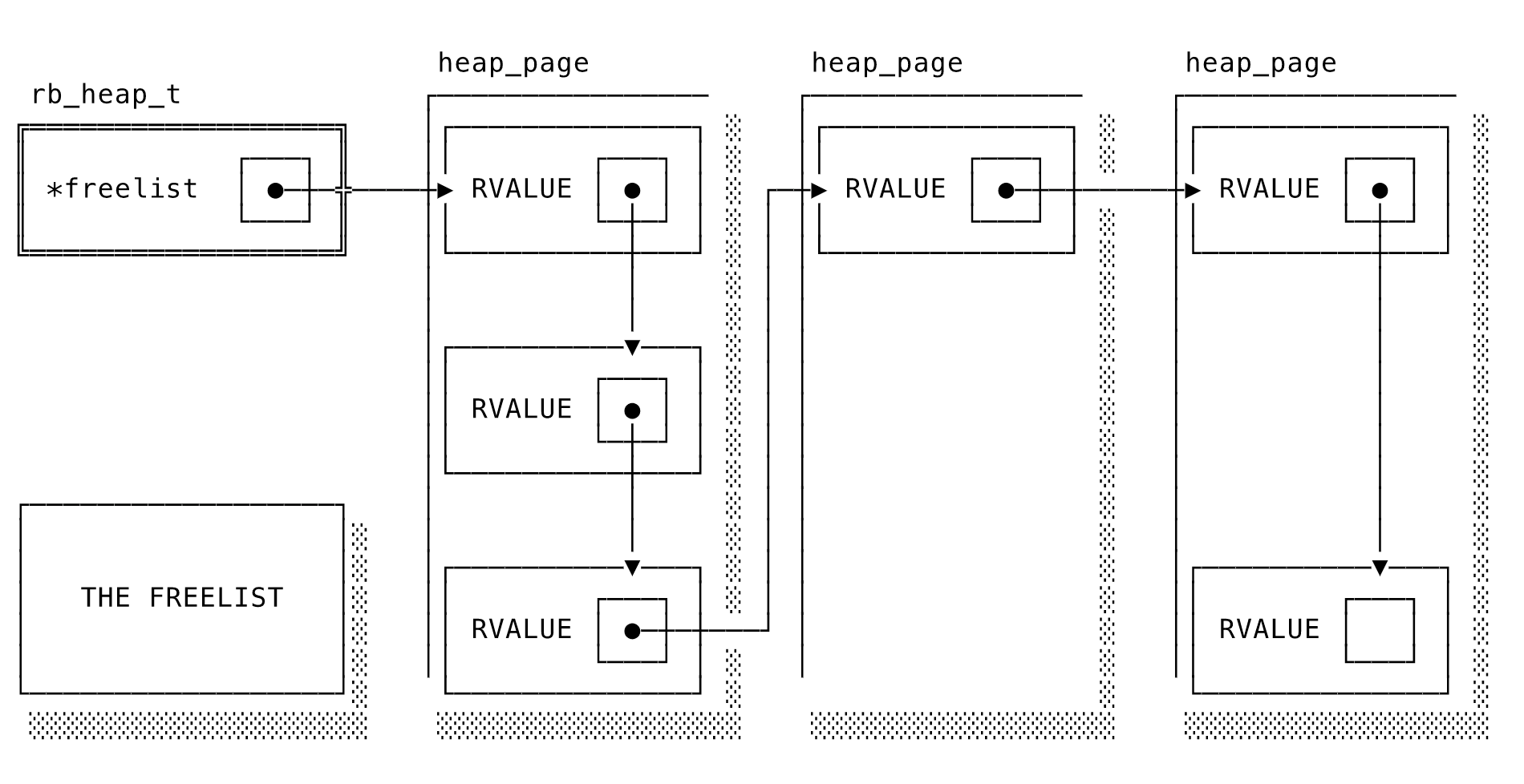
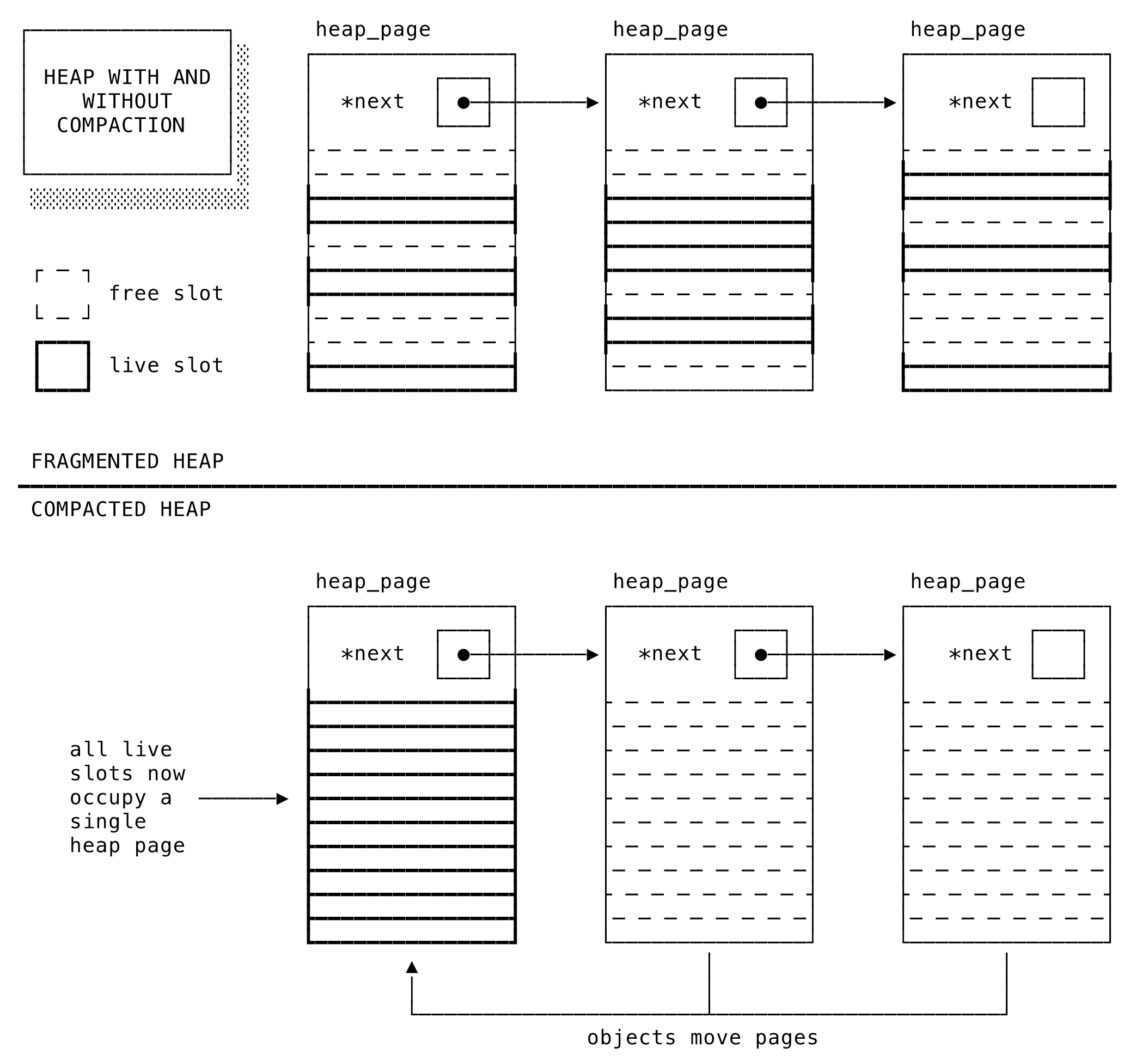
つっつきボイス: 「おー、オブジェクトサイズの変わる境界がいろいろ示されていて面白い」「文字列は23バイト目から変わる、と」「ここらへんはRubyのRVALUEみたいな内部構造に関わってるはず」「近々それ系の翻訳記事出します」「この記事見てて、k0kubunさんのこのツイートを思い出しました↓: 最速のメソッドを身体がつい選んでしまうとかもう常人じゃない感」
僕はRubyに関しては完全にユーザー側のつもりで生きてるけど、実装の都合で速くなってるメソッドを呼吸をするように選択したり、「お前は–dump=insnsを見たことがあるか?」と思いながらrubocopの指摘を容赦なくdisableしたりしているのでもう実装に精神を毒されてそう
— k0kubun (@k0kubun) October 23, 2017
RubyとPythonで文字列分割対決(Awesome Rubyより)
- 元記事: Splitting Strings
chriszetter.comより

# ruby
"".split("-") #=> []
# python
"".split("-") #=> [""]
つっつきボイス: 「Rubyが空の[]を返すのはAWKに近いのか」「著者はPythonにstr.splitの挙動をAWKに近づけるよう提案したけど通らなかったらしいです」
商用で使われるRubyのバージョン分布
link: Ruby Versions Used in Commercial Projects in 2017 – Semaphore: https://t.co/yu1RNWxF39
— Yukihiro Matsumoto (@yukihiro_matz) November 8, 2017
何となく年の瀬が近づいた感じがしてきました。
つっつきボイス: 「おー、1.8系はほぼ消滅か」「2.0以上でもう8割ですね」「Rubyが後方互換性を大事にしているおかげでみんな結構気軽にアップグレードしてる感ある」「frozen_string_literalのような変更にもちゃんと猶予期間を設けてますね」
k0kubunさんのyarv-mjitチューンアップ
fps 56.5 → 60.2 https://t.co/vXPePUoYk0
— k0kubun (@k0kubun) October 30, 2017
つっつきボイス: 「やっぱりoptcarrotでやってます」「60fps超えてるー」
SQL
「Mastering PostgreSQL」が発売
- 元記事: Mastering PostgreSQL
masteringpostgresql.comより

著者のメルマガで知りました。
つっつきボイス: 「タイムセールに乗って即買いました」「そういえば好評につきタイムセールを48時間伸ばしたって通知メールに書いてありました」
「PostgreSQL 10の後に出てるからそちらもカバーはしているけど、PostgreSQLそのものを掘り下げる内容」
「この本はボリュームディスカウントもあって、2冊分の価格(179ドル)で50人まで買えますね: 社内で3人以上買うならこれの方がお得」
PostgreSQL 10の嬉しい点5つ(Postgres Weeklyより)
10clouds.comより

- idカラムの指定がSQL準拠に
- ネイティブのパーティショニング機能
- 複数カラムのstatistics
- 並列性向上
- JSON/JSONBの全文検索
# 同記事より
# 9
CREATE TABLE foo (id SERIAL PRIMARY KEY, val1 INTEGER);
#10
CREATE TABLE foo (id INTEGER GENERATED ALWAYS AS IDENTITY PRIMARY KEY, val1 INTEGER);
つっつきボイス: 「おーやっぱすごい」「JSONの全文検索もうれしいけど、バッドプラクティスになりやすいので注意かな」
「ところでPostgreSQLのexplainって、MySQLのよりずっとずっと読みやすくて助かる」「全面同意します!」「PostgreSQLはindex作成中でもクエリかけられるし」
JavaScript
JavaScriptのasyncとawaitがひと目でわかる動画(15秒)
understanding async/await in 7 seconds pic.twitter.com/IJOQJ2DR35
— Wassim Chegham シ (@manekinekko) April 22, 2017
社内Slackに投下してもらって知りました。
つっつきボイス: 「これマジでわかりやすい」「マジ」
5分でわかるJavaScriptのpromise
codeburst.ioより

Angular.js 5.0.0リリース
blog.angular.ioより
更新情報がいっぱいありすぎて書ききれない感じです。
つっつきボイス: 「CLDR対応は大きいかも」
cldr.unicode.orgより

TestCafe: Selenium要らずのWeb結合テストサービス(JavaScript Liveより)
- 元記事: Integration tests with TestCafe on Gitlab.com
- サイト: http://devexpress.github.io/testcafe/
- リポジトリ: DevExpress/testcafe
devexpress.github.io/testcafeより

Node.js用です。
www.dedicatedcode.comより

つっつきボイス: 「この元記事の方、コードの配色がすごく読みにくい…」
Frappé Charts: GitHub風グラフ表示ライブラリ(Frontend Focusより)
- サイト: Frappé Charts
- リポジトリ: frappe/charts
依存関係なしで使えるそうです。

github.com/frappe/chartsより
CSS/HTML/フロントエンド
フロントエンドチェックリスト
codeburst.ioより
メタタグ/CSS/画像などのチェック項目リストです。
つっつきボイス: 「長い…ここまで増えたら自動化したい」
CSSだけでできる新しめのフォームデザイン(Frontend Focusより)
jonathan-harrell.comより

プレースホルダ文字を動的に移動するなどのテクニックが紹介されています。
jonathan-harrell.comより

FlexGrid: 有料のテーブル作成ライブラリ(Frontend Focusより)
- サイト: Wijmo FlexGrid
- デモ: demos.wijmo.com
grapecity.comより

非常に凝ったテーブルを作れるJSライブラリです。これも依存なしに使え、AngularとReactでも使えるそうです。
demos.wijmo.comより

その他
最も嫌われているプログラミング言語
![]()
stackoverflow.blogより
みっちりと書かれています。
stackoverflow.blogより

つっつきボイス: 「これも面白い記事」「Perlが圧勝」「CoffeeScript…(´・ω・)カワイソス」
番外
ダイヤルアップモデムの音と波形(HackerNewsより)
これはもうリンク先をご覧ください。
つっつきボイス: 「テレホタイム思い出した」「この音知らない人増えたでしょうね(年バレ)」「音は聞いたことあります」
最初のフック音が米国の電話のトーンだったので、大昔にどきどきしながら国際電話かけたときのことをつい思い出してしまいました。
足を鍛えると知能も鍛えられる?
【2015年 BBC News】
足の筋肉力は脳の健康の良い指標なのだhttps://t.co/HikHZehAGw
足が元気な女性は脳が若いぞ〜双子比較研究より— 科学に佇む一行読書心 (@endBooks) November 5, 2017
鍛えるなら足というか下半身かなと思いました。
ニューラルネットワークをだます
Fooling Neural Networks in the Physical World: https://t.co/FzW26UNrBX pic.twitter.com/Q3mnZ4VWfo
— labsix (@labsixresearch) November 2, 2017
この亀のフィギュアを銃と誤認させることに成功したそうです。
今週は以上です。
バックナンバー(2017年度)
週刊Railsウォッチ(20171026)factory_girlが突然factory_botに改名、Ruby Prize最終候補者決定、PhantomJS廃止、FireFoxのFireBug終了ほか
- 20171020 Rubyが来年で25周年、form objectでサニタイズ、コアなString解説本ほか
- 20171013 Ruby 2.5.0-preview1リリース、RubyGems 2.6.14でセキュリティバグ修正、Bootstrap 4.0がついにBetaほか
- 20171006 PostgreSQL 10ついにリリース、Capybaraコードを実画面から生成するnezumiほか
- 20170929 特集: RubyKaigi 2017セッションを振り返る(2)Ruby 2.3.5リリースほか
- 20170922 特集: RubyKaigi 2017セッションを振り返る(1)、Rails 4.2.10.rc1リリースほか
- 20170915 Ruby 2.4.2リリースで脆弱性修正、strong_migrations gemでマイグレーションチェック、書籍『Mastering PostgreSQL』ほか
- 20170908 Rails 5.1.4と5.0.6リリース、コード書換え支援gem「synvert」、遅いテストを分析するTestProfほか
- 20170818 RailsとYarnでTypeScript、Rails新コミッタにkamipoさんも、CSVにSQLクエリをかけられるツールほか
- 20170804 Rails 5.1.3と5.0.5が正式リリース、GitHubでローカライズ基盤サービス、正規表現で迷路を解くほか
- 20170623 gemを見極める7つのコツ、mixinがよくない理由、重いページをrender_asyncで軽減ほか
- 20170616 railsdiff.orgはアップグレードに便利、RubyのDSLとかっこの省略、TerraformをRubyで制御ほか
- 20170609 ついにtherubyracerからmini_racerへ、注意しないとハマるgem、5.1でのVue.jsとTurbolinksの共存ほか
- 20170602 チームが喜ぶ19のgem、Bundler 1.15が高速化&機能追加、Deviseに挑戦する新認証gem「Rodauth」ほか
- 20170512 Rubyの不思議な挙動「シャドウイング」、コードレビュー作法を定めるDanger gemほか
- 20170428 Rails 6.xでの’#form_for’と
#form_tag廃止決定のその後、deviseの5.1対応はこれから、ほか - 20170421 RailsConfが来週アリゾナで開催、コントローラを宣言的に書けるdecent_exposure gemほか
- 20170414 サーバーを危うくする1行のコード、PostgreSQL 10の新機能ほか
- 20170407 N+1問題解決のトレードオフ、Capybaraのテスト効率を上げる5つのコツほか
- 20170331 PostgreSQLの制約機能を使えるRein gemはビューも使えるほか
- 20170324 Ruby 2.4.1リリース、GAEがついにRubyに対応、このgemがないと生きていけない27選ほか
- 20170317 Railsパフォーマンスチューニング本、DBレコード存在チェックの最速メソッド、RubyのUnicode正規化ほか
- 20170310 クールなDocker監視ツールCtop、RailsがGoogle Summer of Code 2017に正式参加、Unicode 10.0.0ドラフト発表ほか
- 20170303 5.0.2正式リリース、メタプログラミングに懲りた話、bundler 1.12のバグ、すぐ試せるWebアノテーションほか
- 20170227 Rails 4.2.8リリース、SHA-1コリジョンアタック、便利なハッシュ変換ツールほか
- 20170217 Rails 4.2.8.rc2リリース、Ruby 2.4正規表現とActiveSupportのnormalizeほか
- 20170210 JRubyやRubiniusの配列への追加はスレッドセーフではないほか
- 20170203 AnyLogin gemで開発中に楽々再ログイン、イベント数ベース課金の監視サービスRollbarほか
- 20170127 わかりやすいAWSサービス名、Rails DBは便利、TruffleRubyの驚異的速度ほか
- 20170120 Ruby 2.5.0 devリリース、古いMySQLのサポート終了、uniqメソッドが削除ほか
- 20170116 Ruby 2.4の詳細、範囲指定したsumメソッドは速い、rescueの挙動を動的に変更ほか
- 20170110 ReactをRailsに置き換える、Ruby 2.4の新機能ほか
今週の主なニュースソース
ソースの表記されていない項目は独自ルート(TwitterやRSSなど)です。

















 ][
][ ]ボタンで1度だけGood/Bad評価する
]ボタンで1度だけGood/Bad評価する




 ]ボタンを数回クリックしてサポートをお願いします。⬇⬇
]ボタンを数回クリックしてサポートをお願いします。⬇⬇











 dies
dies 














 (@y_yagi)
(@y_yagi) 







 。
。