こんにちは、hachi8833です。マカーな皆さまはHigh Sierraアップデートお済みでしょうか。
続報: macOS High Sierra脆弱性パッチに別の不具合、ファイル共有できなくなる恐れ。ただし修正は簡単
12月最初のウォッチ、いってみましょう。
Rails: 今週の改修
MemCacheStoreでexpiringカウンタに機能追加
expires_in: [seconds]に#incrementと#decrementオプションが追加されました。
Rails.cache.increment("my_counter", 1, expires_in: 2.minutes)のように使えます。
# activesupport/lib/active_support/cache/mem_cache_store.rb#125
options = merged_options(options)
instrument(:increment, name, amount: amount) do
rescue_error_with nil do
- @data.incr(normalize_key(name, options), amount)
+ @data.incr(normalize_key(name, options), amount, options[:expires_in])
end
end
end
アイドリング中のDB接続を解除
# activerecord/lib/active_record/connection_adapters/abstract/connection_pool.rb#959
+ # Disconnects all currently idle connections.
+ #
+ # See ConnectionPool#flush! for details.
+ def flush_idle_connections!
+ connection_pool_list.each(&:flush!)
+ end
つっつきボイス: 「これまではとりあえずconfigで設定したpool数分だけ常にDBのconnction poolを確保していたのが、idle_timeoutの間使われていないconnectionは切断するようになったということかな」「大規模なシステムだと影響ありそう: abstractの中で定義されているので、ほぼすべてのDBMSに影響するのかも」
ActiveRecordのDB接続のfork周りを改善
# activerecord/lib/active_record/connection_adapters/abstract/connection_pool.rb より
+ # Discards all connections in the pool (even if they're currently
+ # leased!), along with the pool itself. Any further interaction with the
+ # pool (except #spec and #schema_cache) is undefined.
+ #
+ # See AbstractAdapter#discard!
+ def discard! # :nodoc:
+ synchronize do
+ return if @connections.nil? # already discarded
+ @connections.each do |conn|
+ conn.discard!
+ end
+ @connections = @available = @thread_cached_conns = nil
+ end
+ end
つっつきボイス: 「これは上の#31221に関連する修正のようだ」「最近DBアダプタ周りの改修が目につきますね」
form_withヘルパーでデフォルトでidを生成するよう変更
configでid生成を無効にすることもできるそうです。
# actionview/lib/action_view/helpers/form_helper.rb#1676
def initialize(object_name, object, template, options)
@nested_child_index = {}
@object_name, @object, @template, @options = object_name, object, template, options
- @default_options = @options ? @options.slice(:index, :namespace, :skip_default_ids, :allow_method_names_outside_object) : {}
+ @default_options = @options ? @options.slice(:index, :namespace, :allow_method_names_outside_object) : {}
convert_to_legacy_options(@options)
つっつきボイス: 「あ…これform_forをform_withに代えたときにはまった気がする」「今度からはデフォルトでidが有効ですね」
ActiveRecord::RecordNotFoundに引数を追加
# activerecord/lib/active_record/associations/collection_association.rb#79
def find(*args)
if options[:inverse_of] && loaded?
args_flatten = args.flatten
- raise RecordNotFound, "Couldn't find #{scope.klass.name} without an ID" if args_flatten.blank?
+ model = scope.klass
+
+ if args_flatten.blank?
+ error_message = "Couldn't find #{model.name} without an ID"
+ raise RecordNotFound.new(error_message, model.name, model.primary_key, args)
+ end
+
つっつきボイス: 「これはデバッグでありがたい: どのidで失敗したかがわかるのは親切」
「その代わり今後はこういう雑なコード↓を書くとリクエストidがお漏らししてしまいますけどね」
raise => e
render :index, alert: e.inspect
variable_size_secure_compareをpublicに変更
publicに変更してもSHA256ダイジェストの長さは暴露されないからという理由です。長さを手がかりにした攻撃方法があった気がします。
# actionpack/lib/action_controller/metal/http_authentication.rb#70
before_action(options.except(:name, :password, :realm)) do
authenticate_or_request_with_http_basic(options[:realm] || "Application") do |name, password|
# This comparison uses & so that it doesn't short circuit and
- # uses `variable_size_secure_compare` so that length information
+ # uses `secure_compare` so that length information
# isn't leaked.
- ActiveSupport::SecurityUtils.variable_size_secure_compare(name, options[:name]) &
- ActiveSupport::SecurityUtils.variable_size_secure_compare(password, options[:password])
+ ActiveSupport::SecurityUtils.secure_compare(name, options[:name]) &
+ ActiveSupport::SecurityUtils.secure_compare(password, options[:password])
end
end
end
つっつきボイス: 「長さを手がかりにした攻撃って何て名前だったかなー」「んーと」「そうだ、timing attack」
以下の記事によると、アプリの応答時間がパスワード比較の前方一致に比例してしまうとパスワードが推測されやすくなってしまうので、それを防ぐためにRails 4.2.5.1でvariable_size_secure_compareが導入されたという経緯でした。
参考: Rails CVE-2015-7576 で見る タイミングアタック(Timing Attack)
既存の認証情報をデフォルトで上書きしないよう修正
昨日mergeされていました。
# railties/lib/rails/generators/rails/credentials/credentials_generator.rb#8
module Generators
class CredentialsGenerator < Base
def add_credentials_file
- unless credentials.exist?
+ unless credentials.content_path.exist?
template = credentials_template
say "Adding #{credentials.content_path} to store encrypted credentials."
...
def add_credentials_file_silently(template = nil)
- credentials.write(credentials_template)
+ unless credentials.content_path.exist?
+ credentials.write(credentials_template)
+ end
end
つっつきボイス: 「うっぷ、これは普通にバグ」「y-yagiさんが秒殺で修正」
Rails
Decorator/Presenter gem 6種を比較(Awesome Rubyより)
以下の6つを比較していますが、他にもあるそうです。Lulalalaは手作りなようです。
- ActiveDecorator
- Draper
- Oprah
- Display-case
- Lulalala Presenter
- RailsCasts
つっつきボイス: 「RailsCast?と思ったらgemじゃなくて本当にRailsCastsだった」「↓この図、DecoratorとPresenterの違いがよくわかってとてもいい」「Presenterは機能を絞り込んでる感じ」「Decoratorは強力な分ビューで無茶なことできちゃったりする」
![]()
lulalala.logdown.comより
Rails 5.2を待たずにActiveStorageを使ってみる(Ruby Weeklyより)
すぐ使える手順です。
# 同記事より
Rails.application.routes.draw do
resources :posts
end
Rails 5.2ベータがリリース!内容をざっくりチェックしました
JSON-PatchでRailsのパフォーマンスを向上(Ruby Weeklyより)
見出しから単にJSONにパッチを当てるのかと思ったら、RFC6902: JSON Patchを元に実装したfast-JSON-Patchというnpmパッケージでした。hanaというgemで導入しています。
![]()
// 同記事より
import { compare as jsonPatchCompare } from 'fast-json-patch'
if (!Immutable.is(template.fields, previousTemplate.fields)) {
data.fields_patch = jsonPatchCompare(
previousTemplate.fields.toJS(), template.fields.toJS())
}
つっつきボイス: 「おー、JSONを毎回まるごと投げる代わりに差分だけを投げるのか」
ブラウザごとのsession cookie上限を調べてみた(Ruby Weeklyより)
Rack::Protection::MaximumCookieというRackミドルウェアの利用を勧めています。
# mwpastore/rack-protection-maximum_cookie より
use Rack::Protection::MaximumCookie
つっつきボイス: 「巨大なsession cookie食わせると普通にぶっ壊れますね」「クライアント側で対処しないといけなくなるとつらいです」
Amazon API GatewayでRuby SDK生成をサポート(Ruby Weeklyより)
![]()
aws.amazon.comより
# 同記事より
gem install pet-sdk-1.0.0.gem
つっつきボイス: 「おー、gemとして生成してくれるのがよさそう」「そういえば昔SOAPとかでこういうSDK生成的なのが流行った気がする: Java界隈とかで特に」
RailsEventStore.orgで監査ログを無料で取得
![]()
railseventstore.orgより
RailsEventStore.orgはオープンソースをベースにしています。
つっつきボイス: 「これ使いみちあります?」「悪くなさそう: 某社案件で使いたかったなこれ」「pub/sub好きな人にはいいかも」「Auditingは大体以下の2つをやりたいケースが多い:」
- データに対する参照や変更ログを自動で網羅的に取りたい
- 特定の操作に対して手動で特別なログを出したい
「前者はARのModelに対してであればpaper_trailとかがメジャーで、良い」「後者は正直あんまり決め手がないというかLoggerでよくね?という話になったりする」
後でRailsのPublish/Subscribeについて検索したところ、The Publish-Subscribe Pattern on Rails: An Implementation Tutorialという記事でwisperというgemがあるのを知りました。RailsのActionCableにもPub/Subがありますね。
Knapsack Pro: 複数のCIノードにテストを分散するサービス
![]()
knapsackpro.comより
つっつきボイス: 「Knapsack Pro、以下がとりあえずわかりやすかった」
参考: CircleCI + KnapsackProでRailsのテストを高速化させる
comfortable-mexican-sofa: Rails 5.1対応のマルチリンガルCMSエンジン(RubyFlowより)
以前からあったようです。★2100超え。
![]()
github.com/comfy/comfortable-mexican-sofaより
つっつきボイス: 「名前が凄いな: comfyという略し方も」「mexican sofaってこういう形なのか」「Railsエンジンのようだけどルーティングは自分で足すのかな↓」「マルチリンガル対応みたいだし、使いどころがありそうならチェックしてもいいかも」
# 同記事より
comfy_route :cms_admin, path: "/admin"
comfy_route :cms, path: "/"
derailed_benchmarks: Railsアプリ全体のベンチマークgem
Railsのベンチマークをさっと取れます。作者はRichard Schneemanさんです。
$ bundle exec derailed bundle:mem
TOP: 54.1836 MiB
mail: 18.9688 MiB
mime/types: 17.4453 MiB
mail/field: 0.4023 MiB
mail/message: 0.3906 MiB
action_view/view_paths: 0.4453 MiB
action_view/base: 0.4336 MiB
つっつきボイス: 「gem名はちょっとひねりすぎかなー」「『脱線』w」「自分でもちょっとだけ動かしてみました」
![]()
duckrails: Rails APIのモックを急いで作りたいときに(Ruby Weeklyより)
GUIでAPIモック作れます。docker pull iridakos/duckrailsでお試しできます。
![]()
github.com/iridakos/duckrailsより
つっつきボイス: 「これ教育用にならいいかもしれない」
enumerize: ActiveRecordなどの属性をi18n化
class User < ActiveRecord::Base
extend Enumerize
enumerize :sex, :in => [:male, :female], scope: true
enumerize :status, :in => { active: 1, blocked: 2 }, scope: :having_status
end
User.with_sex(:female)
# SELECT "users".* FROM "users" WHERE "users"."sex" IN ('female')
User.without_sex(:male)
# SELECT "users".* FROM "users" WHERE "users"."sex" NOT IN ('male')
User.having_status(:blocked).with_sex(:male, :female)
# SELECT "users".* FROM "users" WHERE "users"."status" IN (2) AND "users"."sex" IN ('male', 'female')
つっつきボイス: 「名前からenumの拡張かと思ったら、enumerizeのkeyはstringとしてDBに保存されるということかな」
「なお、自分はこのkeyをstringのままenumとして扱う方が好き: DBでSELECTしたときにわかるので」「keyが0とか1とかだと見たときにわからないですしね」「そういえば今のRailsはenumで_prefixと_suffixが使えるのでとても助かってます↓」「enumってRails 4.1からだったのか」
参考: Rails Enum with prefix/suffix
social-share-button: Railsに各種SNSボタンを追加するgem(Awesome Rubyより)
![]()
github.com/huacnlee/social-share-buttonより
つっつきボイス: 「今ならgemよりWebpackでインストールしたいですね」
本当にあったRailsの怖い話
Ruby trunkより
提案: attr、attr_reader、attr_writerをpublicに変えよう
2.5で採用されるようです。
Here are 15k+ examples of send :attr_accessor in the wild:
https://github.com/search?utf8=%E2%9C%93&q=language%3Aruby+%22send+%3Aattr_accessor%22&type=Code
15k+ examples of send :attr_writer in the wild:
https://github.com/search?utf8=%E2%9C%93&q=language%3Aruby+%22send+%3Aattr_writer%22&type=Code
15k+ examples of send :attr_reader in the wild:
https://github.com/search?utf8=%E2%9C%93&q=language%3Aruby+%22send+%3Aattr_reader%22&type=Code
つっつきボイス: 「send :attr_accessorとかでやっている事例がこんなにたくさんあるとは↑」「それならpublicにしてもよさそうですね」
提案: Exception#displayのエラー出力をフォーマットしたい(継続)
def the_program
# ...
raise "failure!"
# ...
rescue RuntimeError => e
$stderr.puts "#{e.message} (#{e.class})\n\t#{e.backtrace.join("\n\t")}"
retry
end
# こう書けば済むようにしたい
rescue RuntimeError => e
e.display
#
つっつきボイス: 「sorahさんからの提案だ」「『そらは』って読むのか」
今年3月の大江戸Ruby会議でキーノートスピーチを務めたのがsorahさんでした。
大江戸Ruby会議 06 に行ってまいりました
Ruby
クラスメソッドをclass << selfで定義する理由(Awesome Rubyより)
RubocopのRubyスタイルガイドではdef self.methodが推奨されていることを踏まえた記事です。いかにも議論になりそうです。
つっつきボイス: 「わかるー: 自分もclass << selfにしたい派」「self.だとクラスのどこにでもクラスメソッドを書けてしまうから散らかりそう」「self.使うこともあるかな」「個数にもよるかも: 1つのクラス内でself.が3つ以上になると耐えられなくなりそう」
【保存版】Rubyスタイルガイド(日本語・解説付き)総もくじ
Ruby 2.5の新機能: Dir.childrenとDir.each_child(Ruby Weeklyより)
# 同記事より
> Dir.each_child("/Users/mohitnatoo/Desktop/test") { |child| puts child }
.config
program.rb
group.txt
test2
つっつきボイス: 「Dir.childrenとDir.each_child、なぜ今までなかったんだと思っちゃいますね」
Rubyでfreezeやfrozen?を使うタイミング
# 同記事より
MY_CONSTANT = "foo".freeze
MY_CONSTANT << "bar" # => RuntimeError: can't modify frozen string
平易で読みやすい内容です。
つっつきボイス: 「Ruby最近始めた人やPHPとかから来た人には読んでおいて欲しいですね」
chewy: Ruby製Elasticsearchフレームワーク(Awesome Rubyより)
Elasticsearch公式のelasticsearch-rubyのODMでありラッパーだそうです。
# toptal/chewyより
class UsersIndex < Chewy::Index
define_type User.active.includes(:country, :badges, :projects) do
field :first_name, :last_name # multiple fields without additional options
field :email, analyzer: 'email' # Elasticsearch-related options
field :country, value: ->(user) { user.country.name } # custom value proc
field :badges, value: ->(user) { user.badges.map(&:name) } # passing array values to index
field :projects do # the same block syntax for multi_field, if `:type` is specified
field :title
field :description # default data type is `string`
# additional top-level objects passed to value proc:
field :categories, value: ->(project, user) { project.categories.map(&:name) if user.active? }
end
field :rating, type: 'integer' # custom data type
field :created, type: 'date', include_in_all: false,
value: ->{ created_at } # value proc for source object context
end
end
つっつきボイス: 「インターフェースが素直で普通っぽく書けるのがよさそう」
bunny: RabbitMQのRuby製クライアント
![]()
rubybunny.infoより
ドキュメントがかなり充実しているようです。
# ドキュメントより
require "bunny"
conn = Bunny.new
conn.start
ch = conn.create_channel
q = ch.queue("", :exclusive => true)
x = ch.fanout("logging.events")
q.bind(x)
つっつきボイス: 「RabbitMQはメッセージングミドルウェアとして有名」「そういえばIBMのWebSphere MQというのもありますね」
![]()
www.rabbitmq.comより
参考: RabbitMQを導入すると… “依存しないカンケイ”でもっと幸せになれる!?
RubyHack.com: 米ソルトレイクシティで開催されるRubyカンファレンス
![]()
rubyhack.comより
昨年に続き、来年5月中旬に第2回が開催されます。詳細は未定のようです。
つっつきボイス: 「ソルトレイクシティというとロケットカーのイメージ」「ユタ州なのか」
@a_matsudaさんの福岡Ruby会議02スライド
つっつきボイス: 「a_matsudaさんの作ったライブラリこんなにある↓」
RubyConf 2017に参加しての雑感(Ruby Weeklyより)
ざっとしか見ていませんが、進むに連れてだんだん落ち込み気味になってきて、ちょっとどきどきしてしまいました。コメント欄の励ましが泣けます。
mruby向けIDE
ちょっとだけ動かしてみました。
![]()
つっつきボイス: 「組み込み分野でIDE欲しい人はそれなりにいると思うので、そういう人向けかも」
データベース
PostgreSQLの設定を1箇所変えたら速度が50倍になった(Postgres Weeklyより)
これだけ速くなったそうです。
![]()
amplitude.engineeringより
つっつきボイス: 「まさしくexplainが役に立つ例」
[Rails] RubyistのためのPostgreSQL EXPLAINガイド(翻訳)
PostgreSQLのAutovacuumのビジュアル表示とチューニング(Postgres Weeklyより)
つっつきボイス: 「Vacuumって何だろうと思って」「↓: うかつにVACUUM FULLすると終わるまでテーブル全部ロックされるから注意」「こ、怖」
参考: PostgreSQL: VACUUM
PostgreSQL標準のツールです。dry-runできる操作が増えたようです。
つっつきボイス: 「dry-runマジありがたい」「レプリケーション方向逆にして自爆するのを防げる」
PgBouncerとAWS RDSでデータベーストラフィックのセキュリティを向上(Postgres Weeklyより)
参考: PgBouncer とは何ですか
つっつきボイス: 「やっぱりPostgreSQLはいい情報あるなー」
JavaScript
JSのletとconst解説
ブラウザからBluetooth機器につないでみた
![]()
blog.vertica.dkより
つっつきボイス: 「こんなことできるのか!」
CSS/HTML/フロントエンド
Webサイトを簡単にPWA(Progressive Web App)に変える方法
Googleが推進しているProgressive Web Appの記事です。
![]()
pwa.rocksより
つっつきボイス: 「Progressiveといえばプログレ」「私もろその世代」「ピンク・フロイドとかキング・クリムゾンとかでしたっけ」「今はJoJoの影響でキング・クリムゾンの意味が全然違っちゃいましたね: 本家クリムゾンもそれに反応してたり」
参考: いまさら聞けないPWAとAMP
![]()
その他
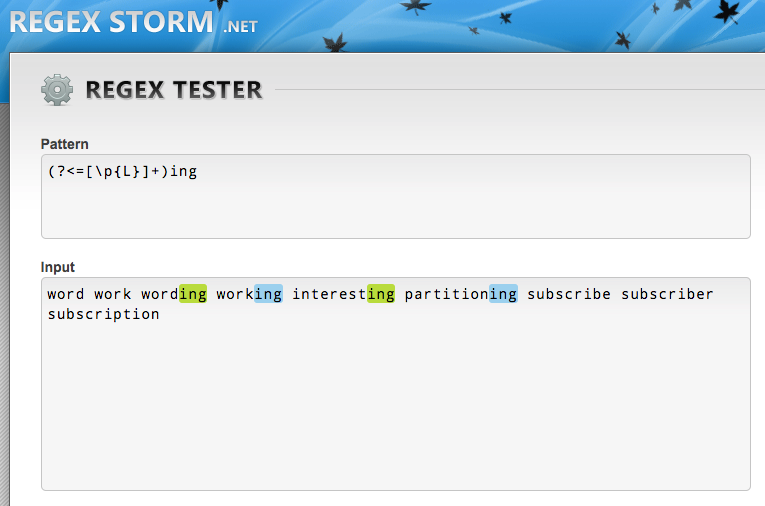
正規表現の背後を深掘り
つっつきボイス: 「この間翻訳したJSの正規表現記事より深い内容っぽいので、これも翻訳してみます」
VSCodeの表示をかっこよくするCSS
![]()
VSCodeをアップデートするとCSSが元に戻っちゃうそうです。
コーダーがスランプを理解して克服する方法
最初何のblockかと思ってしまいました。
- パソコンの電源を切ってみる
- あえて紙と鉛筆でやってみる
- などなど
つっつきボイス: 「紙と鉛筆はスランプ以外でも有効ですねー」
番外
どうぶつの森
100ドルで買えるミューオン検出器
12月
今週は以上です。
バックナンバー(2017年度)
今週の主なニュースソース
ソースの表記されていない項目は独自ルート(TwitterやRSSなど)です。
![]()
![]()
![]()
![160928_1638_XvIP4h]()
![postgres_weekly_banner]()
![frontendweekly_banner_captured]()






































 ][
][ ]ボタンで1度だけGood/Bad評価する
]ボタンで1度だけGood/Bad評価する





















 (@myuutasu)
(@myuutasu) 


