こんにちは、hachi8833です。仙台疲れが今になって来たような気がしないでもありません。雨の降らない国に行きたいです。
晴耕雨読のウォッチ、いってみましょう。
各記事冒頭には![⚓]() でパーマリンクを置いてあります: 社内やTwitterでの議論などにどうぞ
でパーマリンクを置いてあります: 社内やTwitterでの議論などにどうぞ
今回も主に公式のコミット情報からです。
![⚓]()
TableDefinition#columnでカラム定義が重複すると例外を出すように修正
# activerecord/lib/active_record/connection_adapters/abstract/schema_definitions.rb#L354
def column(name, type, options = {})
name = name.to_s
type = type.to_sym if type
options = options.dup
- if @columns_hash[name] && @columns_hash[name].primary_key?
- raise ArgumentError, "you can't redefine the primary key column '#{name}'. To define a custom primary key, pass { id: false } to create_table."
+ if @columns_hash[name]
+ if @columns_hash[name].primary_key?
+ raise ArgumentError, "you can't redefine the primary key column '#{name}'. To define a custom primary key, pass { id: false } to create_table."
+ else
+ raise ArgumentError, "you can't define an already defined column '#{name}'."
+ end
end
index_options = options.delete(:index)
index(name, index_options.is_a?(Hash) ? index_options : {}) if index_options
@columns_hash[name] = new_column_definition(name, type, options)
self
end
つっつきボイス: 「TableDefinitionなんてのがあるのね」「マイグレーションがらみのようです」「create_tableでt.columnが呼ばれるときの重複チェックを今回修正したと: テストコードがわかりやすい↓」「普通やらかさないエラーだろうけどraiseはしとかないとね![😋]() 」
」
# activerecord/test/cases/migration/change_schema_test.rb#L199
+ def test_create_table_raises_when_defining_existing_column
+ error = assert_raise(ArgumentError) do
+ connection.create_table :testings do |t|
+ t.column :testing_column, :string
+ t.column :testing_column, :integer
+ end
+ end
+
+ assert_equal "you can't define an already defined column 'testing_column'.", error.message
+ end
参考: Ruby on Rails 5.2 / ActiveRecord::ConnectionAdapters::TableDefinition — DevDocs
「columnがconnection_adapters/abstract/schema_definitions.rbにあるということは、abstractすなわち複数のコネクタで共通で使われるメソッドなんでしょうね: ぱっと見ですが」「abstractクラスなのでそれで合ってると思います![🧐]() : 細かくはちゃんと追わないといけないですが、上のエラーももしかするとDBMSの種類によっては通っちゃうことがあったのかもしれないですね: SQLite3とか割と作りが雑なんでカラム名かぶっても通っちゃうとかありそう、知らんけど
: 細かくはちゃんと追わないといけないですが、上のエラーももしかするとDBMSの種類によっては通っちゃうことがあったのかもしれないですね: SQLite3とか割と作りが雑なんでカラム名かぶっても通っちゃうとかありそう、知らんけど![😆]() 」「
」「![😆]() 」
」
「そういえば先週のウォッチでもSQLite3ラブラブ![❤]() な意見が出てました」「ちなみにSQLite3、かなり速いっすよ
な意見が出てました」「ちなみにSQLite3、かなり速いっすよ![🕶]() : Win32アプリみたいなPCローカルアプリで使うDBMSとしては読み込み速度とかめっちゃ優秀」「あー、そういえば以前いた職場の社内ツールでも中でSQLite3が走ってました」「ただSQLite3って型とかが割と雑で、確か内部では数値なんかも文字列で保存してたような覚えがあるんですよ」「『保存してSQLっぽく検索できればそれでいいのっ』って感じなんでしょうね
: Win32アプリみたいなPCローカルアプリで使うDBMSとしては読み込み速度とかめっちゃ優秀」「あー、そういえば以前いた職場の社内ツールでも中でSQLite3が走ってました」「ただSQLite3って型とかが割と雑で、確か内部では数値なんかも文字列で保存してたような覚えがあるんですよ」「『保存してSQLっぽく検索できればそれでいいのっ』って感じなんでしょうね![😓]() 」「だからこそ速いんでしょうけどね
」「だからこそ速いんでしょうけどね![🤓]() 」
」
参考: SQLite Home Page
![]()
sqlite.orgより
![⚓]()
ActiveSupport::Time.zone.atとTime::atの引数の不揃いを解消
# 同PRより
# Before:
Time.at(946684800, 123456.789).nsec #=> 123456789
Time.zone.at(946684800, 123456.789).nsec #=> ArgumentError (wrong number of arguments (given 2, expected 1))
# After:
Time.at(946684800, 123456.789).nsec #=> 123456789
Time.zone.at(946684800, 123456.789).nsec #=> 123456789
# activesupport/lib/active_support/values/time_zone.rb#L357
- def at(secs)
- Time.at(secs).utc.in_time_zone(self)
+ #
+ # A second argument can be supplied to specify sub-second precision.
+ #
+ # Time.zone = 'Hawaii' # => "Hawaii"
+ # Time.at(946684800, 123456.789).nsec # => 123456789
+ def at(*args)
+ Time.at(*args).utc.in_time_zone(self)
end
つっつきボイス: 「Time.atとTime.zone.atを揃えたようです」「おや?これで見るとTime.zone.atの方を変えてる?: Time.zone.atの方が使用頻度多いし(つかRailsではそもそもこっちを使うべき![👮♂️]() )、
)、Time.atをじかに使うことってほとんどないと思うんだけどなー」「それもそうですね…![🤔]() 」「breaking changeになりそうに見える
」「breaking changeになりそうに見える![🕶]() 」「そのときはRailsアップグレードガイドに載るんでしょうね」
」「そのときはRailsアップグレードガイドに載るんでしょうね」
参考: Ruby on Rails 5.2 / Time::at — DevDocs
参考: Ruby on Rails 5.2 / Time::zone — DevDocs
![⚓]()
.dup.freezeを-ショートハンドに置き換え
# activemodel/lib/active_model/attributes.rb#L103
def self.set_name_cache(name, value)
const_name = "ATTR_#{name}"
unless const_defined? const_name
- const_set const_name, value.dup.freeze
+ const_set const_name, -value
end
end
つっつきボイス: 「出たな-![🤣]() 」「あ、これ以前のウォッチでもみんなで『キモチワルイー』って言ってた文字列dup&freezeのショートハンドですね
」「あ、これ以前のウォッチでもみんなで『キモチワルイー』って言ってた文字列dup&freezeのショートハンドですね![😆]() 」「確かRuby 2.5の機能じゃなかったっけ?」
」「確かRuby 2.5の機能じゃなかったっけ?」
毎度のことですが、記号は検索しづらいです![😭]() 。マイナス記号
。マイナス記号-です。
参考: instance method String#-@ (Ruby 2.5.0)
selfがfreeze されている文字列の場合、selfを返します。 freezeされていない場合は元の文字列のfreezeされた (できる限り既存の) 複製を返します。
ruby-lang.orgより
参考: NEWS for Ruby 2.5.0 (Ruby 2.5.0)
参考: Feature #13077: [PATCH] introduce String#fstring method - Ruby trunk - Ruby Issue Tracking System
![⚓]() 記号の雑学
記号の雑学
ついでながら、マイナス記号とハイフン記号とダッシュ記号は本来は別の記号だったのですが、記号を増やしようがないタイプライターの時代に1つのキーで代用されてしまい(長いemダッシュは--としたり)、それがそのままASCIIなどにも持ち込まれてハイフンマイナスという苦し紛れな名前が付けられ、Unicodeで別記号が用意された今も地味に混乱を呼び続けてます。ハイフン記号とマイナス記号とダッシュ記号(emダッシュとenダッシュ)の使い分けには闇が横たわっています。ヨーロッパの一部には、ハイフンとダッシュを取り違えて使うとマジギレする国がありますのでご用心。見た目1ドットぐらいしか違わないんですけどね…![😫]() 。
。
![]()
![]()
Dash vs. Hyphen ~ IngliszTiczer.plより
参考: ハイフンマイナス - Wikipedia
参考: ハイフン - Wikipedia
参考: ダッシュ (記号) - Wikipedia
![⚓]() 重複した子レコードを親が
重複した子レコードを親がsaveしないよう修正
# 同issueより再現コード
# モデル
class Parent < ApplicationRecord
has_many :children
end
class Child < ApplicationRecord
belongs_to :parent
validates :name, uniqueness: true
end
# コード
parent = Parent.new(children: [Child.new(name: 'Wiske'), Child.new(name: 'Wiske')])
parent.save
parent.errors.any? # エラーになるはずが、ならない
つっつきボイス: 「validates uniqueness: trueだから本来エラーにならないといけないやつ: へー、この書き方↓するとすり抜けちゃってたのか![😇]() 」「
」「![😇]() 」「これは下手すると既存のアプリでも知らないうちにエラーを作り込んじゃってたりすることがあるかも?自分はこの書き方はしないけどねっ
」「これは下手すると既存のアプリでも知らないうちにエラーを作り込んじゃってたりすることがあるかも?自分はこの書き方はしないけどねっ![🕶]() 」
」
Parent.new(children: [Child.new(name: 'Wiske'), Child.new(name: 'Wiske')])
「ついでに聞いちゃいますけど、今見ているコードにあるreflection↓っていう言葉は、ここではどういう意味が込められているんでしょうか?(英語的にいっぱい意味がありすぎるので![🤯]() )」「reflectionというと、メソッドオブジェクトを取ってきてそれをゴニョゴニョしたいなんてときに使いますね」「あー、メタプログラミング的な?」「たぶんプログラミング関連ではそれ以外の意味でreflectionという言葉が出てくることはあまりないと思うので
)」「reflectionというと、メソッドオブジェクトを取ってきてそれをゴニョゴニョしたいなんてときに使いますね」「あー、メタプログラミング的な?」「たぶんプログラミング関連ではそれ以外の意味でreflectionという言葉が出てくることはあまりないと思うので![💦]() 」
」
# activerecord/lib/active_record/autosave_association.rb#L381
def save_collection_association(reflection)
if association = association_instance_get(reflection.name)
autosave = reflection.options[:autosave]
...
if autosave != false && (@new_record_before_save || record.new_record?)
if autosave
saved = association.insert_record(record, false)
elsif !reflection.nested?
- association_saved = association.insert_record(record)
if reflection.validate?
- saved = association_saved
+ valid = association_valid?(reflection, record, index)
+ saved = valid ? association.insert_record(record, false) : false
+ else
+ association.insert_record(record)
end
end
elsif autosave
「たとえばですが、reflectionという名前の変数があるとすると、その中には状況によってさまざまなオブジェクトが動的に入る可能性があるよ、という意図が強調される感じですかね」「おー、『あのクラスとあのクラスだけが入ると思うなよ』っていうイメージですか」
「あくまでイメージというか概念寄りの話ですが、reflectionという言葉が使われていると、そこにどんなオブジェクトが入るかわからないし、どんなオブジェクトが来てもいいという感じ: C言語の(void *)キャストとか、Javaの(object)キャストなんかが概念的に似ているかな」「なるほどー!![😀]() 」
」
参考: C言語: 汎用ポインタ
参考: 強く型付けされているJavaの理解に必修の“型変換” (2/3):【改訂版】Eclipseではじめるプログラミング(18) - @IT
「このコードならreflection.validate?とあるから、普通ならreflectionにはActiveRecordオブジェクトやActiveModelのインスタンスが入るんだろうけど、それ以外のオブジェクトが入る可能性だってあるんだぜ、という主張を込めて自分なら使うかな![😎]() 、ここでは知らんけどw」「
、ここでは知らんけどw」「![😃]()
![😃]() 」
」
reflectionには「反射」「反省(self reflection)」「反映」などなどいろんな意味がありますが(「反」の文字が共通してますね![🧐]() )、ポイントは意味が受動的なところかなと思いました。反映もapplyで表すと人間が能動的にやるイメージですが、reflectだと受動的というか性質に従って自動的に行われる、というニュアンスが強いと思います。reflectionがメタプロの文脈でよく使われるのもそれなのかなと。
)、ポイントは意味が受動的なところかなと思いました。反映もapplyで表すと人間が能動的にやるイメージですが、reflectだと受動的というか性質に従って自動的に行われる、というニュアンスが強いと思います。reflectionがメタプロの文脈でよく使われるのもそれなのかなと。
人間の態度や状況が何かにreflectするとは、そうした態度や状況(またはそう思われるもの)がそこに存在することが示されていることを表す。
Cobuldより大意
![⚓]() 初期化ブロックが
初期化ブロックがbuild_recordにあるのをbefore_addに移動
以下はコミットログから見繕いました。
# https://github.com/rails/rails/commit/c256d02f010228d260b408e8b7fda0a4bcb33f39#diff-20f545c453ee24942b6f7ae565e9e369R104
def build(attributes = {}, &block)
if attributes.is_a?(Array)
attributes.collect { |attr| build(attr, &block) }
else
- add_to_target(build_record(attributes)) do |record|
- yield(record) if block_given?
- end
+ add_to_target(build_record(attributes, &block))
end
end
つっつきボイス: 「改修範囲が広いので取りあえずこれだけ引用してみました」「ここだけ見て言うと、add_to_targetというのはおそらくフックを追加するメソッドかな: で、そういうコールバック登録の枠組みが既にあるならそれに揃えようよってことなんだと思う」「![😀]() 」
」
# rails/activerecord/lib/active_record/associations/collection_association.rb#L282
def add_to_target(record, skip_callbacks = false, &block)
if association_scope.distinct_value
index = @target.index(record)
end
replace_on_target(record, index, skip_callbacks, &block)
end
![⚓]()
force_equality?をpublic APIに
43ef00eの続きだそうです。
# https://github.com/rails/rails/pull/33067/files#diff-e66146ba2ab968e251944a764e4ed967R54
+ def force_equality?(value)
+ coder.respond_to?(:object_class) && value.is_a?(coder.object_class)
+ end
つっつきボイス: 「@kamipoさんが何度かに分けて修正したようです」「force_equality?ってメソッドがあるのか: どうやらrespond_to?(:object_class)でオブジェクトのクラスまで含めて等しいかどうかをチェックするやつみたいですね」「おー」「たとえばシリアライズしたときのパラメータのリストは同じでも、オブジェクトの種類が違うものがやってくることがあったりするけど、そういうのも検出するということでしょうね」「![😃]() 」
」
「このメソッドなら、たとえばSTI(Single Table Inheritance)なんかでそれが親クラスのオブジェクトなのか子クラスのオブジェクトなのか、なんてのも見分けられるはず」「なるほど!」「オブジェクトが参照しているデータベースが同じだとシリアライズした後では区別できなくなっちゃうけど、シリアライズより前にそういうところをチェックするときに使えるんじゃないかな?ってね![🤓]() 」「
」「![😋]() 」「これが欲しい気持ち、よくわかる」
」「これが欲しい気持ち、よくわかる」
Rails: STI(Single Table Inheritance)でハマったところ
参考: Rails ActiveRecordのSTI(Single Table Inheritance)の使い方 | EasyRamble
![⚓]() Rails
Rails
![⚓]() Bundler 2リリース間近のチェックリスト
Bundler 2リリース間近のチェックリスト
Bundler関連ということで関連してこちらも。
つっつきボイス: 「リリースはまだみたいなので、こういうことをやりますリストですね」「そういえば今はもうRubyをバージョンアップすると最新のBundlerが入るようになったんだっけ?どっちだったっけ?」
そういえば2.5でのBundler標準化は延期されたのでした↓。
「チェックリストをざざーっと見た感じでは互換性の心配ほとんどなさそうというか、こっちでやることあまりないかも?: つか互換性なかったらRubyバージョンを単純に上げたときに即死だし![😇]() 」「Bundlerといえば、HerokuのBundlerが最新でないのでwarning出たりたまにつっかえたりするんですよね(今はどうだったかな
」「Bundlerといえば、HerokuのBundlerが最新でないのでwarning出たりたまにつっかえたりするんですよね(今はどうだったかな![💦]() )」「まーHerokuの場合Herokuの環境に身を任せないといけないので、面倒を見てくれる範囲は大きいけど自分はコンテナでやりたいかなー
)」「まーHerokuの場合Herokuの環境に身を任せないといけないので、面倒を見てくれる範囲は大きいけど自分はコンテナでやりたいかなー![😂]() 」「
」「![😀]() 」「Linuxサーバーの面倒なところ触りたくないっという人にはもちろんHerokuはおすすめですね: Railsチュートリアルは今もHeroku使ってるんだったかな?」「今は違ってたような…?」
」「Linuxサーバーの面倒なところ触りたくないっという人にはもちろんHerokuはおすすめですね: Railsチュートリアルは今もHeroku使ってるんだったかな?」「今は違ってたような…?」
後で調べたら、Railsチュートリアルは今もHeroku使ってました。
![⚓]() graphql-ruby: Railsとも連携
graphql-ruby: Railsとも連携
![]()
graphql-ruby.orgより
今回のウォッチは何となくShopify成分が多めでした。
つっつきボイス: 「これ扱ったことなかったっけ?」「なかったっぽかったので(と思ったらありました![💦]() )」「このロゴは素晴らしいですね
)」「このロゴは素晴らしいですね![😍]() 」「グラフ理論のグラフをうまくあしらってるし
」「グラフ理論のグラフをうまくあしらってるし![😎]() 」
」
参考: apollo + rails(graphqlサーバー)でファイルをアップロードするmutationを作る方法 - Qiita
![⚓]() Active Record 5.2のメモリ肥大化を探る
Active Record 5.2のメモリ肥大化を探る
このSam Saffaronさんのブログは良記事多いですね。翻訳許可をいただいたので今後出したいと思います。
# 同記事より
a = []
Topic.limit(1000).each do |u|
a << u.id
end
つっつきボイス: 「あー、↑こうやって書けばそりゃ確かに肥大化するナ」「eachを使ってるから?」「eachだけじゃなくてu.idを参照してるから: このu.idを評価しないといけないのでu.idが呼ばれるたびにTopicというモデルのオブジェクトが生成される」「そっちかー」「しかもそれをa <<で代入しちゃってるからこのループの間このモデルオブジェクトがまったく解放されない」「![😲]() 」「
」「pluckすると速いって記事に書いてあるのもたぶんそれで、pluckならモデルオブジェクトを保持する必要ないはずだし」「pluckは配列を返しさえすればいいですしね」
「確かこの間のRails Developers Meetup 2018でもまさにこの辺の話をしていた人がいたと思う」「自分見てなかったかも![😓]() 」
」
後でmorimorihogeさんからセッション名を教えていただきました↓。
参考: railsdm2018で「ActiveRecordデータ処理アンチパターン」を発表しました - Hack Your Design!
「まーでもActiveRecordの挙動とかlazy loadingのあたりなんかを忖度できるようにならないと、上のような書き方がヤバイ理由は見た瞬間にはわからないでしょうねー![🧐]() 」「そこが経験が必要なところかー
」「そこが経験が必要なところかー![😃]() 」「あかんのは
」「あかんのはu.idという参照の仕方です![😎]() : 終わってからGCすれば消えますけど(たぶんね)」「覚えます!」
: 終わってからGCすれば消えますけど(たぶんね)」「覚えます!」
参考: Ruby on Rails 5.2 / Enumerable#pluck — DevDocs
最近知ったRailsの便利なメソッド
![⚓]() Rails 5で「関連付け先のないレコード」を使う(Ruby Weeklyより)
Rails 5で「関連付け先のないレコード」を使う(Ruby Weeklyより)
つっつきボイス: 「記事のスタイリングとかシンタックスハイライトがちと読みづらい…」「関連付けのない場合ってことなのかな?ざざっと見た感じ、assosiation先のレコードがなくても取得したい場合にLEFT JOINでの外部結合をActiveRecordでどう書くかって話のように見える」「時間ないので次行きましょうー」
# 同記事より
User.join('left outer join posts on posts.user_id = users.id')
.where(posts: {user_id: nil})
.first
- Rails 5はちょっとだけクリーンで読みやすい気がする
# 同記事より
User.left_joins(:posts)
.where(posts: {user_id: nil})
.first
![⚓]() Rails 5.2のcredentialはセキュアではない?(RubyFlowより)
Rails 5.2のcredentialはセキュアではない?(RubyFlowより)
つっつきボイス: 「GitHub Wikiにざざっと書いた、1ページで収まる内容ですね」「これはわかりみあるヤツ: Rails 5.2のcrenentialは、言ってみれば例のTwelve-Factor Apps↓の原則3『設定を環境変数に格納する』に反してるんですよ」「あー」
参考: The Twelve-Factor App (日本語訳)
![]()
12factor.netより
「原理主義者としては許せないでしょうけど、そこまで行かなくても自分もこの辺は微妙: マスターキーの扱いっていろいろ難しいんですよ」「というと?」「チーム開発をしていると、開発メンバーが入れ替わるたびにマスターキーを変えないといけなくなるから: そして現実にメンバーの出入りはよくあることだし」「あー!![🤫]() 」「しかもマスターキーの変更履歴がリポジトリに残るのも、どうもねー
」「しかもマスターキーの変更履歴がリポジトリに残るのも、どうもねー![🤔]() 」「記事の人はnot secureとか書いてるけど、単にcredentialが好きじゃないんでしょうねー
」「記事の人はnot secureとか書いてるけど、単にcredentialが好きじゃないんでしょうねー![😆]() 自分も使うつもりたぶんないし」「
自分も使うつもりたぶんないし」「![😆]() 」
」
![⚓]() deep_pluck gemがRails 5.2に対応
deep_pluck gemがRails 5.2に対応
つっつきボイス: 「pluckの入れ子版みたいなこのdeep_pluckもウォッチで扱ったことありましたね: たぶんバッチとか書くときなんかに優秀なヤツ![👍]() 」「
」「![😀]() 」「これもActiveRecordオブジェクトを生成しないから速いんだとしたら、自分なら生SQL書いちゃう、かなー?
」「これもActiveRecordオブジェクトを生成しないから速いんだとしたら、自分なら生SQL書いちゃう、かなー?![😆]() 」「
」「![😆]() 」
」
![⚓]() その他Rails
その他Rails
週刊Railsウォッチ(20170407)N+1問題解決のトレードオフ、Capybaraのテスト効率を上げる5つのコツほか
そろそろJSの組み合わせが爆発しそう。
つっつきボイス: 「ちょうど今日のチームミーティングでもWebpackについて発表ありましたけど、やっぱりWebpackerを知るにはWebpackそのものを知っておかないと結局後で困ることになりますね![😆]() 」「
」「![😆]() 」
」
![]()
webpack.js.orgより
つっつきボイス: 「テストって最初のうちはどの程度までみっちり書けばいいのか真剣に悩んじゃいました」「それはもう誰かに決めてもらうのが早い![😎]() 」「
」「![🤣]() 」「ただ思うのは、よほどシビアなアプリでもない限り、カバレッジの数字だけを当てにしてもあまり意味がないかなってことですね」「カバレッジの値が増えたからといって本当に必要な部分がカバーできてるかどうかはまた別なのか
」「ただ思うのは、よほどシビアなアプリでもない限り、カバレッジの数字だけを当てにしてもあまり意味がないかなってことですね」「カバレッジの値が増えたからといって本当に必要な部分がカバーできてるかどうかはまた別なのか![🙂]() 」
」
つっつきボイス: 「2位のMagentoって知りませんでした」「自分も![😁]() 」「それにしてもShopify、いつの間にかこんないい位置についてるなー: ユーザー数はともかく、捌いているトラフィック数は凄い
」「それにしてもShopify、いつの間にかこんないい位置についてるなー: ユーザー数はともかく、捌いているトラフィック数は凄い![👁]() 」「Shopify、Railsですしね
」「Shopify、Railsですしね![🤠]() 」「EC-CUBEと比較してみたいところだけど、日本製でほぼ日本市場だけだろうから比較は難しいかなー」
」「EC-CUBEと比較してみたいところだけど、日本製でほぼ日本市場だけだろうから比較は難しいかなー」
つっつきボイス: 「mizchiさんいいこと言うなー: フロントエンドの強い人で今は確かフリーランスだったかな?」「さっきのreflectionの話もそうでしたけど、コードを書いた人の意図を読み取る能力と、読み取れるようにコードを書く能力ってやっぱり重要ですね![🧔🏽]() 」
」
そのうちIPA試験あたりにコード読解問題とか出たりするんでしょうか。
![]()
![⚓]() Ruby trunkより
Ruby trunkより
![⚓]() Unicode 11のグルジア語の大文字小文字の取り扱いをどうしよう?
Unicode 11のグルジア語の大文字小文字の取り扱いをどうしよう?
![]()
http://www.unicode.org/versions/Unicode11.0.0/ch07.pdf (Section 7.7, Georgian, pp. 320-321) より
Geogianが「グルジア語の」とも「ジョージアの」とも読めてしまうので、いちいち断りが必要です。グルジアというとスターリンの出身国というイメージ。なおグルジア語とロシア語には共通部分がほぼありません。
![]()
https://ja.wikipedia.org/wiki/%E3%82%B0%E3%83%AB%E3%82%B8%E3%82%A2%E8%AA%9E#/media/File:Kartvelian_languages.svg より
参考: グルジア語 - Wikipedia
つっつきボイス: 「これはもう多言語マニアがいないとどうしようもない![😇]() 」「issueでもそう言ってました
」「issueでもそう言ってました![😆]() 」
」
![⚓]()
GRND_NONBLOCKを設定せずにgetrandomが複数呼ばれるとロックする
if which ruby >/dev/null && which gem >/dev/null; then
PATH="$(ruby -e 'puts Gem.user_dir')/bin:$PATH"
fi
つっつきボイス: 「GRND_NONBLOCKって、またLinuxに新しいフラグが出たのか」「(Linuxでしたか![😓]() )」「よく見つけたなこれ感」
)」「よく見つけたなこれ感」
参考: getrandom(2) - Linux manual page
![⚓]()
Procの行番号/カラム番号、できればfirstやlastも取りたい
# rspec-parameterized gemのサンプル
describe "lambda parameter" do
where(:a, :b, :answer) do
[
[1 , 2 , -> {should == 3}],
[5 , 8 , -> {should == 13}],
[0 , 0 , -> {should == 0}]
]
end
with_them do
subject {a + b}
it "should do additions" do
self.instance_exec(&answer)
end
end
end
# 出力例
lambda parameter
a: 1, b: 2, answer: -> {should == 3}
should do additions
a: 5, b: 8, answer: -> {should == 13}
should do additions
a: 0, b: 0, answer: -> {should == 0}
should do additions
tagomorisさんとjoker1007さんからのリクエストです。
つっつきボイス: 「最初気づかなかったけど、joker1007さんがそういう感じのgem作ってたそうです↓」「RSpecでwhere(:a, :b, :answer)みたいにwhereで指定したいってことのようだ: Procが複数になるとつらいとか、これは確かにやるなら言語でサポートする方がいいでしょうね![😋]() 」
」
![⚓]() Ruby
Ruby
![⚓]() Relaxed Ruby Style: ちょいゆるRubyスタイルガイド
Relaxed Ruby Style: ちょいゆるRubyスタイルガイド
![]()
Version 2.3とあるのはRubyのことなのかこのスタイルガイドのことなのか、どちらなんでしょう?
つっつきボイス: 「rubocop.ymlに軽くパッチを当てて使うようです」「パッチじゃなくて、元々rubocopにはinherit_fromというデフォルト設定を読み込む機能があるので、それを使って読み込んだ上で自分達のルールとの差分を上書きする、みたいな使い方ですね」「あー、そうでした![😓]() 」「うん、こういうのいいよね: BPS社内でも標準Rubocop.yml定めたいと思ってる
」「うん、こういうのいいよね: BPS社内でも標準Rubocop.yml定めたいと思ってる![🤓]() 」
」
![⚓]() ramda-ruby:
ramda-ruby:
# 同リポジトリより: トランスデューサー
appender = R.flip(R.append)
xform = R.map(R.add(10))
R.transduce(xform, appender, [], [1, 2, 3, 4]) # [11, 12, 13, 14]
xform = R.filter(:odd?.to_proc)
R.transduce(xform, appender, [], [1, 2, 3, 4]) # [1, 3]
xform = R.compose(R.map(R.add(10)), R.take(2))
R.transduce(xform, appender, [], [1, 2, 3, 4]) # [11, 12]
xform = R.compose(R.filter(:odd?.to_proc), R.take(2))
R.transduce(xform, R.add, 100, [1, 2, 3, 4, 5]) # 104)
R.transduce(xform, appender, [], [1, 2, 3, 4, 5]) # [1, 3])
R.into([], xform, [1, 2, 3, 4, 5]) # [1, 3])
JavaScriptのRamdajsをRubyに移植したものだそうです。名前からlambdaのもじりという感じで、ramdajs.comには「育ちすぎたram(子羊)じゃないんだなー、たぶん」とありました。ramだ。
つっつきボイス: 「ramda: いいのかその読み方で![😆]() 」「たぶん子羊じゃないといいつつ、シンボルマークは羊ですね
」「たぶん子羊じゃないといいつつ、シンボルマークは羊ですね![😄]() 」「関数型の追求というよりは、フィルタ的な便利ツール集という印象」
」「関数型の追求というよりは、フィルタ的な便利ツール集という印象」
![]()
ramdajs.comより
参考: ラムダ計算 - Wikipedia
トランスデューサーそのものはめちゃめちゃ意味が広いですが、ここでは関数型言語よりの何かなんでしょうね。何も見ずに「translator + reducer」かなと推測。
参考: トランスデューサー - Wikipedia
![⚓]() Rubyとmallocの問題
Rubyとmallocの問題
![⚓]() TTY: Ruby錬金術師の秘薬
TTY: Ruby錬金術師の秘薬
RubyKaigi 2018で自分が見てなかったやつです(´・ω・`)。
つっつきボイス: 「お、これ自分見ましたよ: いい内容![👍]() 」「
」「![😃]() 」「TTYってマルチスレッド対応のプログレスバーとかいろいろ機能揃ってますよ」
」「TTYってマルチスレッド対応のプログレスバーとかいろいろ機能揃ってますよ」
「このTTYってrails new的にファイルをどさっと作るんで、腰を据えて本格的なCLIアプリを作るためのテンプレート的なものでしょうね: 気楽にさっと書くにはかなり重装備な感じ」「この間のウォッチで取り上げたoptparseとはまた違うんでしょうか?」「optparseは引数処理を楽に書けるヤツなのでまた違いますね![🕶]() 」
」
「TTYは、railsコマンドとかsystemdコマンドみたいなものすごく複雑なCLIを見通しよく作れますね: その気になればaptやyarnだって作れちゃう![😆]() 」「
」「![🤣]() 」「TTY上でmarkdownすら書ける」「何だかすげー」
」「TTY上でmarkdownすら書ける」「何だかすげー」
「ただまあ、今こんなごついCLI書くぐらいならWebアプリにするよなという気もすると言えばする」「確かにー」「でも最初CLIで完成させてからそれをWebアプリ化するという流れはありかなとも思うし: CLIならバッチとかとっても扱いやすいし、融通が利きやすいし」「たぶんデバッグもしやすいし![😃]() 」
」
「『こういうCLIはRubyで作ればいいじゃん』っていう文化になったらいいなーと思うし」「こうやってTTYなんかで作ったRubyのCLIを、mrubyとかでコンパイルして配布できればいいのにとも思うし: 結局RubyのCLIって配布がだいたい問題になるんですよね」「確かにー」「CLIでのGo言語の強みはrun anywhereですからね![🕶]() 」
」
![⚓]() go-mruby: mrubyのGoバインディング
go-mruby: mrubyのGoバインディング
// 同リポジトリより
package main
import (
"fmt"
"github.com/mitchellh/go-mruby"
)
func main() {
mrb := mruby.NewMrb()
defer mrb.Close()
// Our custom function we'll expose to Ruby. The first return
// value is what to return from the func and the second is an
// exception to raise (if any).
addFunc := func(m *mruby.Mrb, self *mruby.MrbValue) (mruby.Value, mruby.Value) {
args := m.GetArgs()
return mruby.Int(args[0].Fixnum() + args[1].Fixnum()), nil
}
// Lets define a custom class and a class method we can call.
class := mrb.DefineClass("Example", nil)
class.DefineClassMethod("add", addFunc, mruby.ArgsReq(2))
// Let's call it and inspect the result
result, err := mrb.LoadString(`Example.add(12, 30)`)
if err != nil {
panic(err.Error())
}
// This will output "Result: 42"
fmt.Printf("Result: %s\n", result.String())
}
ついでにquartzという、RubyからGoプログラムを呼び出すgemも見つけたのですが、RubygemにGoのnative extensionを含める感じではなさそう…なぜかこの方面はさっぱり発展しません(´・ω・`)。
![]()
同リポジトリより
# 同リポジトリより
HTTP.post("http://example.com/upload", form: { file: HTTP::FormData::File.new(io) })
つっつきボイス: 「このhttprb/httpってどうでしょう?」「少なくとも表の青いところにある標準のNet::HTTPはまず使うことはないと思う、というかつらすぎて使いたくない![😆]() 」「
」「![😆]() 」「
」「![😆]() 」
」
![]()
同記事より
参考: class Net::HTTP (Ruby 2.5.0)
「この表の中で一番メジャーなHTTPクライアントって、赤いところにあるHTTPClient↓なんじゃないかなー: 少なくとも自分的にはベスト」
「ただ、HTTPClientはREADMEがそっけないんですが、実はそこから地味にリンク貼られているRDocのAPIドキュメントがすごくしっかり書かれてるんですよ↓」「ほー!!」「ここ読むとわかりますけど、プロキシもちゃんと対応してるし、BASIC認証の先にあるBASIC認証の対応とか、環境変数からプロキシ渡すなんてのもできます」「いいこと聞いた!![😍]() 」「
」「![😍]() 」
」
「表の緑色のところにあるFaraday↓もひと頃流行ったけど、Faradayの抽象化は人によって好みが分かれるかもしれない: クローラーを書くとかならFaradayが向いてますね」「逆にステータスコードが取りたいとかヘッダを確認したいとかならHTTPClientがいい」
「で、本題のhttprbは表の分類からもHTTPClientと同じところを狙ってるというのが取りあえずは見て取れますね」「![😃]() 」「おっ?httprbのインストールは
」「おっ?httprbのインストールはgem install httpだって: この名前よく取れたなー![😲]() 」「Rubygems.orgで決めてるんでしたっけ?」「早いもの勝ちです
」「Rubygems.orgで決めてるんでしたっけ?」「早いもの勝ちです![😎]() 」
」
![⚓]() Rubyで書かれたワールドカップ試合情報CLI(RubyFlowより)
Rubyで書かれたワールドカップ試合情報CLI(RubyFlowより)
# 同リポジトリより
$ footty # Defaults to today's world cup 2018 matches
今日は以下でした。
#1 Thu Jun/14 Russia (RUS) vs Saudi Arabia (KSA) Group A @ Luzhniki Stadium, Moscow
つっつきボイス: 「試合結果というより、『今日ある試合は何だったっけ?』用っぽいです」「こういう文化っていいですよねー」
![⚓]() Rubyの謎機能: フリップフロップ
Rubyの謎機能: フリップフロップ
# 同記事より
irb(main):021:0> (1..10).each {|i| puts i if i==3..i==5 }
3
4
5
=> 1..10
つっつきボイス: 「Less Feature-Rich, More Funという記事を翻訳していて、一番最後にRubyのフリップフロップという謎の機能について言及されていたので」「何だこれ…確かに謎![🤔]() 」
」
「あー、if i==3..i==5で..の前と後の条件がフリップフロップになってるのか!![😲]() 」「
」「![😲]() 」「
」「![😲]() 」「こんなのがコードレビューに出てきたらつらすぎ
」「こんなのがコードレビューに出てきたらつらすぎ![😭]() 」「Ruby Gold試験になら出そうですね…
」「Ruby Gold試験になら出そうですね…![😓]() 」
」
![⚓]() その他Ruby
その他Ruby
RubyKaigiの応募要項です。
ほのっとしちゃいました。その後英語版↓も出ました。
![⚓]() クラウド/コンテナ/Linux
クラウド/コンテナ/Linux
以下時間切れのため、つっつきはここまでです![🙇]() 。後追いで何か追記するかもしれません。
。後追いで何か追記するかもしれません。
![⚓]() Linuxのloadavgの問題を追求
Linuxのloadavgの問題を追求
はてブで見つけました。
つっつきボイス: 「これはとてもいい記事」
![⚓]() Googleのgvisorすごいかも
Googleのgvisorすごいかも
この間のウォッチで軽く取り上げたgvisorですが、TCFM #22の前半がこの話題でもちきりでした。
![⚓]() ワンライナー特集
ワンライナー特集
![⚓]() GitLabが立て続けに機能を拡大
GitLabが立て続けに機能を拡大
最新の記事ではありませんが一応。
![]()
![]()
参考: GitLabがGoogleのKubernetes Engineを統合、コンテナアプリケーションのデプロイが超簡単に | TechCrunch Japan
![⚓]() その他クラウド/コンテナ/Linux
その他クラウド/コンテナ/Linux
![⚓]() SQL
SQL
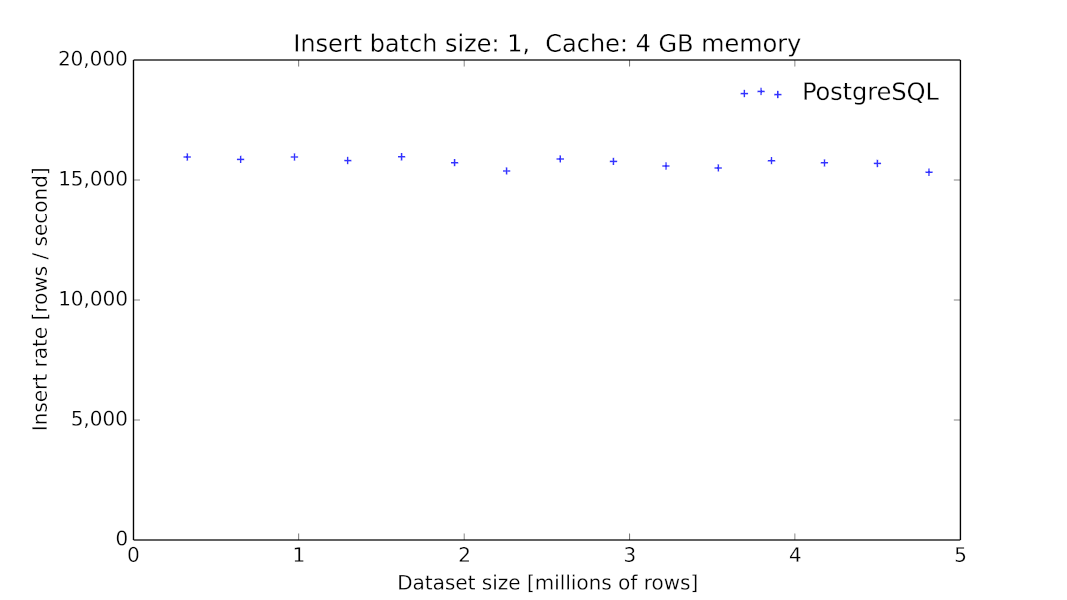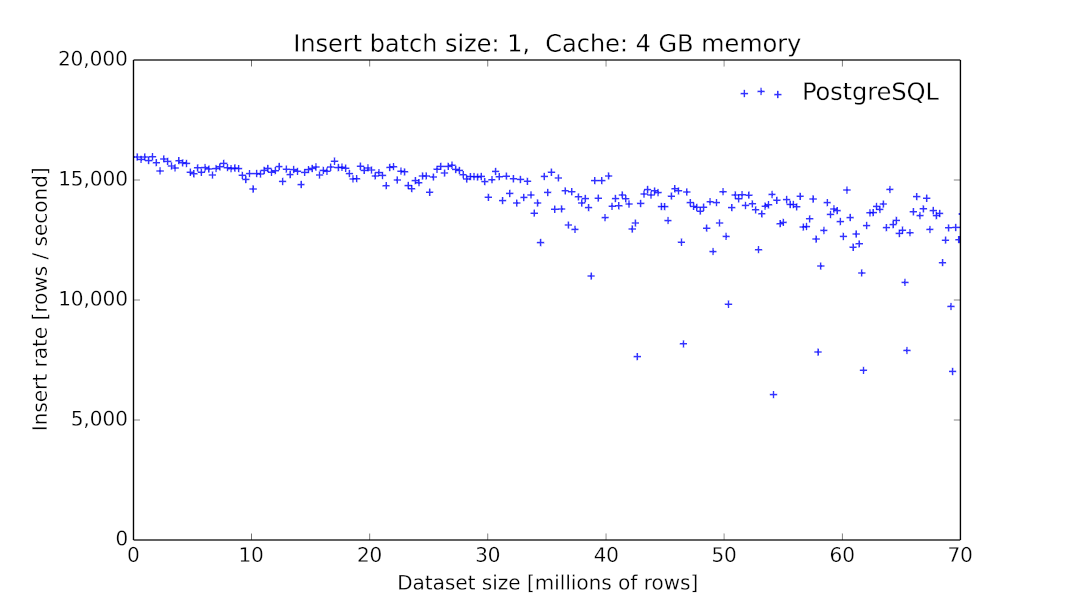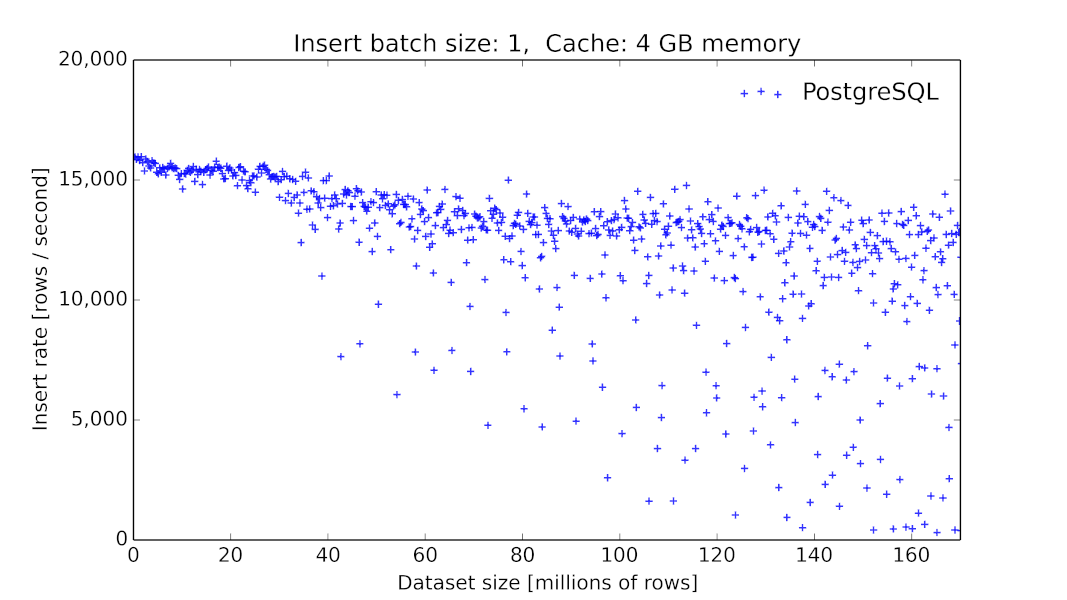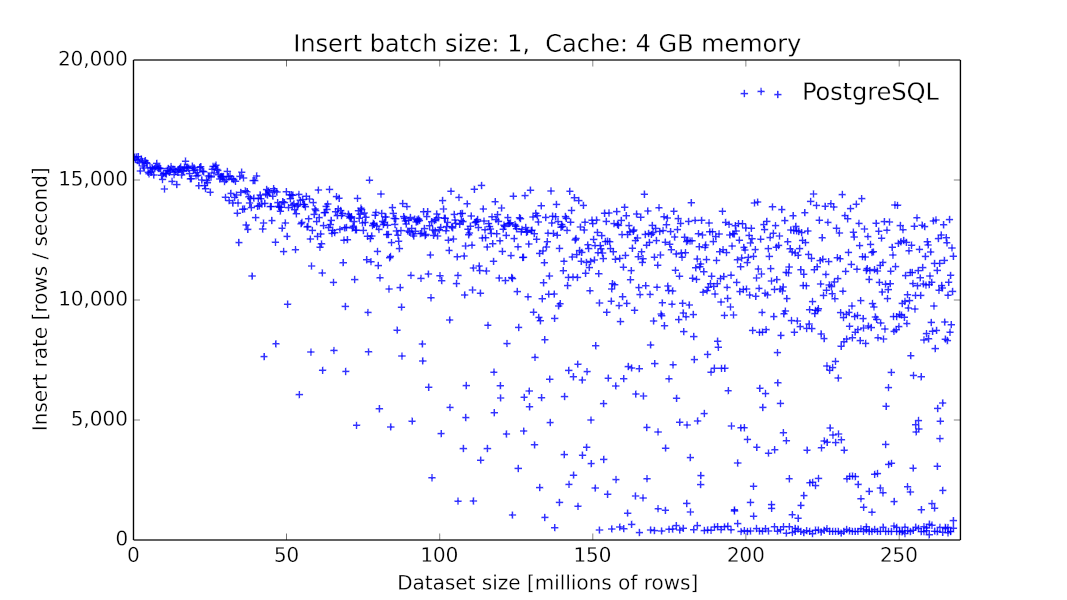
![⚓]() ロシア発: PostgreSQL 10の論理レプリケーションの復旧(Postgres Weeklyより)
ロシア発: PostgreSQL 10の論理レプリケーションの復旧(Postgres Weeklyより)
![]()
同記事より
かなり長いです。
![]()
同記事より
参考: マテリアライズドビュー - Wikipedia
![⚓]() JavaScript
JavaScript
![⚓]() Vue Native: VuejsでネイティブWebアプリを作るフレームワーク
Vue Native: VuejsでネイティブWebアプリを作るフレームワーク
![]()
vue-native.ioより
![⚓]() PhantomJSの開発が正式に終了し、アーカイブ化(JSer.infoより)
PhantomJSの開発が正式に終了し、アーカイブ化(JSer.infoより)
昨年のウォッチでもお伝えしたPhantomJSが正式に終了しました。お疲れさまです。
週刊Railsウォッチ(20171026)factory_girlが突然factory_botに改名、Ruby Prize最終候補者決定、PhantomJS廃止、FireFoxのFireBug終了ほか
参考: PhantomJSの開発が終了しリポジトリがアーカイブ化された - JSer.info
![⚓]() mobx: JSのステート管理ライブラリ(JSer.infoより)
mobx: JSのステート管理ライブラリ(JSer.infoより)
![]()
mobx.js.orgより
JavaScriptのステート管理はVuejsにもあったりReduxもあったりと賑やかですね。js.orgに集結している?
![]()
redux.js.orgより
JavaScript: Reduxが必要なとき/不要なとき(翻訳)
![⚓]() ExcelでJavaScriptがサポート
ExcelでJavaScriptがサポート
TypeScriptを直接サポートするつもりはないそうです。
参考: Microsoft、Excelカスタム関数としてJavaScriptのサポートを発表
![⚓]() その他JavaScript
その他JavaScript
![⚓]() CSS/HTML/フロントエンド/テスト
CSS/HTML/フロントエンド/テスト
↑著名な認知心理学者のDonald NormanことDon Normanの名前から「Norman door」と呼ばれているそうです。てっきりこのドアの発明者かと思ってしまいました。
引くかと思ったら押す、押すかと思ったら引くような、「押す/引く」表示がないとガンガンに間違えるドアだそうです。
参考: Urban Dictionary: Norman Door
参考: ドナルド・ノーマン - Wikipedia
![⚓]() テスティングを楽しく学びたい人向けのサイトなど
テスティングを楽しく学びたい人向けのサイトなど
- 元記事: テストラジオ — テスティングの話題が豊富なポッドキャスト
既に60回を超えているんですね。凄い。
![]()
testerchan.hatenadiary.comより
![⚓]() Apollo Clientとは
Apollo Clientとは
![]()
apollographql.comより
![⚓]() 言語よろずの間
言語よろずの間
![⚓]() Mage: Goのタスクランナー
Mage: Goのタスクランナー
![]()
同リポジトリより
英語の古語にある「メイジ(魔法使い)」だよなと思いつつ、日本人なのでつい「マゲ」かと思ってしまいました。
![⚓]() Fo: Goで関数型やってみる言語
Fo: Goで関数型やってみる言語
![]()
play.folang.orgより
なお、Goでジェネリクスを欲しいと思ったことが今のところありませんでした。
参考: ジェネリックプログラミング - Wikipedia
![⚓]() Stack Overflowのデベロッパーアンケート結果2018年版
Stack Overflowのデベロッパーアンケート結果2018年版
毎度お騒がせ。
参考: 2018年 人気&嫌われプログラミング言語トップ25- Stack Overflow | マイナビニュース
![⚓]() その他言語
その他言語
![]()
参考: 依存型 - Wikipedia
![⚓]() その他
その他
![⚓]() Gitコマンドを異世界転生モノで解説するよ
Gitコマンドを異世界転生モノで解説するよ
![⚓]() らめぇそれ
らめぇそれ
![⚓]() 「不正指令電磁的記録に関する罪」とは
「不正指令電磁的記録に関する罪」とは
はてブで知りました。
![]()
![⚓]() Windowsに新しいアプリインストール形式「MSIX」が登場予定
Windowsに新しいアプリインストール形式「MSIX」が登場予定
![]()
![⚓]() その他のその他
その他のその他
社内勉強会のお題が「トランザクションとロック」だったので、そういうときについ思い出す動画です。
![⚓]() 番外
番外
![⚓]() 今どきの法科学
今どきの法科学
![⚓]() あれそんなにヤバイ物質だったのか
あれそんなにヤバイ物質だったのか
![⚓]() 学校でがっつり教えられた人の立場は
学校でがっつり教えられた人の立場は
![⚓]() 香害
香害
![⚓]() リアルポケモン認定したい
リアルポケモン認定したい
![⚓]() 火星で有機物発見か
火星で有機物発見か
地球に巨大隕石がぶつかったか何かで火星に飛来した小型隕石によるコンタミの可能性が気になります。南極は一面真っ白で月の石や火星の石がちょくちょく見つかるので、逆もありそうな気がしてしまいます。
参考: 南極サイエンス基地 > 南極隕石
今週は以上です。
おたより発掘
バックナンバー(2018年度後半)
週刊Railsウォッチ(20180608)特集「RubyKaigi 2018後の祭り」、`Enumerable#index_with`は優秀、コントローラから`@`を消し去るほか
今週の主なニュースソース
ソースの表記されていない項目は独自ルート(TwitterやRSSなど)です。
![]()
![]()
![160928_1638_XvIP4h]()
![postgres_weekly_banner]()
![frontendweekly_banner_captured]()









 。
。


 でパーマリンクを置いてあります: 社内やTwitterでの議論などにどうぞ
でパーマリンクを置いてあります: 社内やTwitterでの議論などにどうぞ
 」
」 : 細かくはちゃんと追わないといけないですが、上のエラーももしかするとDBMSの種類によっては通っちゃうことがあったのかもしれないですね: SQLite3とか割と作りが雑なんでカラム名かぶっても通っちゃうとかありそう、知らんけど
: 細かくはちゃんと追わないといけないですが、上のエラーももしかするとDBMSの種類によっては通っちゃうことがあったのかもしれないですね: SQLite3とか割と作りが雑なんでカラム名かぶっても通っちゃうとかありそう、知らんけど 」「
」「 な意見が出てました」「ちなみにSQLite3、かなり速いっすよ
な意見が出てました」「ちなみにSQLite3、かなり速いっすよ : Win32アプリみたいなPCローカルアプリで使うDBMSとしては読み込み速度とかめっちゃ優秀」「あー、そういえば以前いた職場の社内ツールでも中でSQLite3が走ってました」「ただSQLite3って型とかが割と雑で、確か内部では数値なんかも文字列で保存してたような覚えがあるんですよ」「『保存してSQLっぽく検索できればそれでいいのっ』って感じなんでしょうね
: Win32アプリみたいなPCローカルアプリで使うDBMSとしては読み込み速度とかめっちゃ優秀」「あー、そういえば以前いた職場の社内ツールでも中でSQLite3が走ってました」「ただSQLite3って型とかが割と雑で、確か内部では数値なんかも文字列で保存してたような覚えがあるんですよ」「『保存してSQLっぽく検索できればそれでいいのっ』って感じなんでしょうね 」「だからこそ速いんでしょうけどね
」「だからこそ速いんでしょうけどね 」
」
 )、
)、 」「breaking changeになりそうに見える
」「breaking changeになりそうに見える 」「あ、これ以前のウォッチでもみんなで『キモチワルイー』って言ってた文字列dup&freezeのショートハンドですね
」「あ、これ以前のウォッチでもみんなで『キモチワルイー』って言ってた文字列dup&freezeのショートハンドですね 。マイナス記号
。マイナス記号 。
。

 」「
」「 )」「reflectionというと、メソッドオブジェクトを取ってきてそれをゴニョゴニョしたいなんてときに使いますね」「あー、メタプログラミング的な?」「たぶんプログラミング関連ではそれ以外の意味でreflectionという言葉が出てくることはあまりないと思うので
)」「reflectionというと、メソッドオブジェクトを取ってきてそれをゴニョゴニョしたいなんてときに使いますね」「あー、メタプログラミング的な?」「たぶんプログラミング関連ではそれ以外の意味でreflectionという言葉が出てくることはあまりないと思うので 」
」 、ここでは知らんけどw」「
、ここでは知らんけどw」「
 / Bundler 2 Release Checklist · Issue #6582 · bundler/bundler
/ Bundler 2 Release Checklist · Issue #6582 · bundler/bundler  (@y_yagi)
(@y_yagi)  」「
」「
 」「
」「 」「
」「 」「しかもマスターキーの変更履歴がリポジトリに残るのも、どうもねー
」「しかもマスターキーの変更履歴がリポジトリに残るのも、どうもねー 」「
」「
 」
」 」「それにしてもShopify、いつの間にかこんないい位置についてるなー: ユーザー数はともかく、捌いているトラフィック数は凄い
」「それにしてもShopify、いつの間にかこんないい位置についてるなー: ユーザー数はともかく、捌いているトラフィック数は凄い 」「Shopify、Railsですしね
」「Shopify、Railsですしね 」「
」「 」
」


 」「関数型の追求というよりは、フィルタ的な便利ツール集という印象」
」「関数型の追求というよりは、フィルタ的な便利ツール集という印象」

 わかばちゃんと学ぶGoogleアナリティクス発売中 (@llminatoll)
わかばちゃんと学ぶGoogleアナリティクス発売中 (@llminatoll) 
 。後追いで何か追記するかもしれません。
。後追いで何か追記するかもしれません。









 Ponanza (@issei_y)
Ponanza (@issei_y)  ◆テングモウミウシ◆
◆テングモウミウシ◆











 ニュースレター
ニュースレター
 ボタンを押してください。
ボタンを押してください。