
更新情報
2016/10/13: 初版公開
2020/11/27: 追記
こんにちは、hachi8833です。
少し前に、babaさんから「Rubyの内部文字コードはUTF-8じゃないよ」とツッコミがありました。

(追記: 上は会話の途中から切り取りましたのでご了承ください)
いきなりの展開にくらくらきましたが、babaさんはさらにたたみかけます。

こうしたことはとっくにご存じの方も多いと思いますが、「Rubyといえば2.0以来UTF-8完全対応なんじゃないの」と勝手に思い込んでた私は脳に掌底を食らったような思いです。ああ、でもこういうことがあるから面白い。
![⚓]() プログラミング言語と内部文字コードの関係
プログラミング言語と内部文字コードの関係

まず最初に押さえておきたい点です。プログラミング言語で文字コードに関連する部分は、「文字列」「正規表現」「入出力」「コード中の文字リテラル(””の中など)」「コード中の文字リテラル以外の要素(変数名など)」「ファイル名」などが中心になります。そして文字列に関連して「ソート順」などについても考慮が必要です。

とbabaさんが指摘しているとおり、Rubyで文字コードに関連するのはほとんどの場合標準ライブラリです。
![⚓]() UCS正規化方式
UCS正規化方式
Java、C#、Python、Perl、Goなど、多くの言語では内部でUnicodeを用いています。言い方を変えれば、文字コードを固定してそれ以外のコードについては変換のみで対応するということです。このように内部表現をUnicodeの文字コードに統一する方式をUCS正規化(UCS Normalization)と呼びます【注: リンク修正いたしました】。UCSは「UnicodeUniversal Character Set」の略です。
UCS正規化を採用している言語では、たとえばStringクラスなどで原則としてその文字コードしか保存できません。たとえばJavaのStringクラス、Characterクラス、char型であれば文字をUTF-16で保存します。そのため、UTF-16Unicodeに含まれない文字(実はそれなりにあるのです)は原則として言語標準のStringクラスなどでは扱わない/扱えないことになります。
こうした言語でも、標準のStringクラスなどを使わずにchar[]型などに保存して自力でハンドリングしたり別ライブラリで扱ったりする分には構いませんし、その必要が生じることはいくらでもありえます。
![⚓]() Rubyは1.9から「CSI方式」
Rubyは1.9から「CSI方式」
これに対し、Rubyは1.9でCSI(Code Set Independent)という独自の多言語化方式を導入しました。
UCS正規化と異なり、CSI方式では特定の内部コードを仮定しません。たとえばStringクラスの変数にはその気になればUnicode以外の文字コードでも直接保存できます。つまり文字列は内部的に事実上バイナリとして保存されているのです。その代わりStringクラスで文字コード情報を持てるようにする(以下のコード例の#encoding)などの改良が行われました。
実装が複雑になることもあり、CSI方式を導入した言語はRuby以外にはなかなかないようですが、多様性に富んだチャレンジングな多言語化方式とされています。なお、Ruby 1.9でオレオレ文字コードを導入してみた豪の者を見つけました。
また、1.9ではマジックコメントが導入され、スクリプトファイルの冒頭(冒頭がshebangの場合は2行目)に# coding: euc-jpなどの方法でファイルのエンコーディングを指定できるようになりました。
#!/usr/bin/env ruby -
# coding: utf-8
str='ab漢字'
puts str[2]
puts __ENCODING__
puts str.encoding
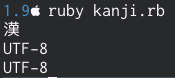
ただし1.9の場合、マジックコメントを指定しない場合のデフォルトのファイルエンコーディングはUS-ASCIIです。UTF-8ではありません。
#!/usr/bin/env ruby -
puts __ENCODING__

![⚓]() Ruby 2.0での文字コード周りの変更とその後
Ruby 2.0での文字コード周りの変更とその後
Rubyが2.0になってから、このマジックコメントを指定しない場合のデフォルトのファイルエンコーディングがUS-ASCIIからUTF-8に変更されました。
#!/usr/bin/env ruby -
puts __ENCODING__

2.0でのデフォルト文字コードの変更はもちろん大きなものであり、他にも文字コードについての変更点はありますが、CSIの部分に関しては引き続き変わっていません。つまり2.0の文字列は1.9のときと同様、内部では事実上バイナリなのです。
Rubyでは、1.9でのCSI導入、2.0でのデフォルトのファイルエンコーディングのUTF-8への変更という段階的な方法で多言語化を切り替えてきました。2.0以降、これらの点について変更はありません。
私がRuby 2.0からUTF-8完全対応だと思い込んでいたのはいろんな意味で誤りでした。後述するようにRubyは1.9より前からUTF-8を含む複数の文字コードを扱えましたし、2.0でUTF-8になったのは「デフォルトのファイルエンコーディング」の部分です。
![⚓]() 参考: Ruby 1.8以前の場合
参考: Ruby 1.8以前の場合
Ruby 1.8以前は文字列をデフォルトでASCII単位でとして扱い、文字列メソッドもバイト単位で動作しました。たとえば1.8でstr="ab漢字"の後でstr[2]の値を取り出すと0xB4(EUCの「漢」の最初のバイト)になりました。
str='ab漢字'
p sprintf('%#x', str[2])
このkanji.rbはEUC-JPで保存されているとします。

1.8以前でこうしたスクリプトを実行するには、スクリプトファイルの文字コードに応じた-Ku(UTF-8)や-Ke(EUC-JP)や-Ks(Shift_JIS)などのオプション指定が欠かせませんでした(2.0から非推奨)。指定したオプションは$KCODEで確認でき、正規表現は$KCODEに応じて文字数の数え方が変わりました。文字列ごとに異なる文字コードを指定することはできませんでした($KCODEは1.9で廃止)。
![⚓]() 注意
注意
UCS正規化とCSIには、それぞれメリットとデメリットがあります。どちらが優れているというものではなく、ユースケースによって変わります。
一般にUCS正規化では文字コードの実装を一本化できますが、Unicodeにない文字などは標準的な方法では直接扱えないので別のライブラリなどで対応する必要があります。
CSIでは標準的な方法で複数の文字コードを同時に扱うことができますが、正規表現の文字数の数え方などを文字コードに応じて実装側で切り替えるなど、実装が複雑になることが考えられます。

![⚓]() 参考文献
参考文献
今回の記事では『プログラマーのための文字コード技術入門』に大変お世話になりました。
追記(2020/11/27): 2018年に同書の改訂版が出ました↓。


同書の裏帯に書かれているように、特定の文字コード体系を押したりせず、評価を読者の判断に任せている点に好感が持てます。同書ではRuby 1.8と当時最新だったRuby 1.9を比較しており、決して新しい内容ではありませんが、今回取り上げたRuby 1.9でのCSI導入についても詳しく解説されていて、現在でも読む価値のある良書です。Unicode、UTF-8が万能ではないということがわかったのは自分にとっては大きな収穫でした。
文字コードはどこまで行っても奥が深いので、理解の甘いところがありましたらTwitterで私までお知らせいただけると幸いです。
![⚓]() 追記(2020/11/27)
追記(2020/11/27)
RubyでCSI正規化が採用された経緯についてMatz自らQuoraで回答していました 。
。